机器学习之pandas库学习
这里写目录标题
- pandas介绍
- pandas核心数据结构
-
- Series
- DataFrame
-
- DataFrame的创建
- 列访问
- 列添加
- 列删除
- 行访问
- 行添加
- 行删除
- 数据修改
pandas介绍
pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入 了大量库和一些标准的数据模型,提供了高效地操作大型结构化数据集所需的工具。
pandas核心数据结构
Series
Series可以理解为一个一维的数组,只是index名称可以自己改动。类似于定长的有序字典,有Index和 value
也类似C++中的pair类型和map容器
Series的创建
import pandas as pd
import numpy as np
#Series的创建
#创建一个空的系列
s = pd.Series()
#从ndarray中创建一个系列
data = np.array(['a','b','c'])
s = pd.Series(data)
print(s)
s = pd.Series(data, index=[10, 11, 12])
print(s)

#从字典创建一个系列
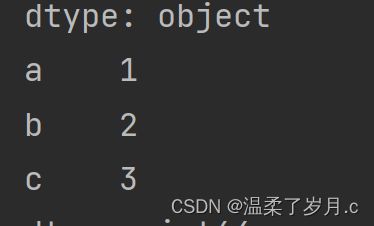
data1 = {"a" : 1, "b" : 2, "c" : 3}
p = pd.Series(data1)
print(p)
访问Series的数据
data1 = {"a" : 1, "b" : 2, "c" : 3}
p = pd.Series(data1)
print(p)
#通过索引访问数据(value)
print(p[0], "-->", p[1])
#通过索引访问数据(key 和 value)可结合切片使用
print(p[:2])
#通过key访问数据(value)
print(p['a'])

DataFrame
DataFrame是一个类似于表格的数据类型,可以理解为一个二维数组,索引有两个维度,可更改。DataFrame具有以下特点:
- 潜在的列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
DataFrame的创建
#二维数组,创建一个空序列
s = pd.DataFrame()
print(s)
#从列表中创建DataFrame
data1 = [1, 2, 3, 4 ,5 ]
s = pd.DataFrame(data1)
print(s)

如果只传一组数据,DataFrame也可以创建一维的数组
data1 = [ ['a', 10], ['b', 12],['c', 14]]
s = pd.DataFrame(data1, columns=['col1', 'col2'])
print(s)

传两组数据,可以创建二维的,DataFrame的columns参数,可以给元素中的列加标签
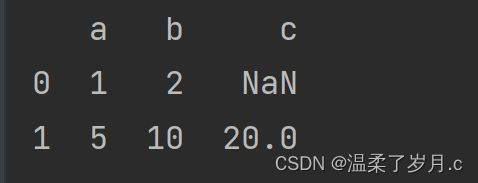
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print(df)
可以自己指定标签(列),添加数据
#从字典来创建DataFrame
data = {'name':['Tom', 'Jack', 'Kevin'], 'age' : [13, 15, 18]}
s = pd.DataFrame(data)
print(s)

通过字典和Series来创建
data = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data)
print(df)

列访问
DataFrame是一个带标签的二维数组,访问列,就访问列的标签就行了
data = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data)
print(df)
print(df['one'])
print(df['two'])

列添加
列添加,就直接新建一个列的标签,然后可以用Series对这个列进行赋值
data = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data)
print(df)
print(df['one'])
print(df['two'])
df['new'] = pd.Series(['a1', 'b1', 'c1'], index = ['a','b', 'c'])
print(df)
列删除
删除列要使用pandas的pop函数。参数是列的标签
df.pop('one')
print(df)

行访问
如果只是需要访问DataFrame某几行数据的实现方式则采用数组的选取方式,使用 “:” 即可:
类似切边操作
print(df[1 : 4 : 2])

loc方法是针对DataFrame索引名称的切片方法。loc方法使用方法如下
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df.loc['b'])
print(df.loc[['a', 'b']])

iloc和loc区别是iloc接收的必须是行索引和列索引的位置。iloc方法的使用方法如下:
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df.iloc[2])
print(df.iloc[[2, 3]])

行添加
行添加采用append函数,在后面追加行
import pandas as pd
df = pd.DataFrame([['zs', 12], ['ls', 4]], columns = ['Name','Age'])
df2 = pd.DataFrame([['ww', 16], ['zl', 8]], columns = ['Name','Age'])
df = df.append(df2)
print(df)
行删除
使用索引标签从DataFrame中删除或删除行。 如果标签重复,则会删除多行。
采用drop函数进行删除
import pandas as pd
df = pd.DataFrame([['zs', 12], ['ls', 4]], columns = ['Name','Age'])
df2 = pd.DataFrame([['ww', 16], ['zl', 8]], columns = ['Name','Age'])
df = df.append(df2)
# 删除index为0的行
df = df.drop(0)
print(df)
数据修改
更改DataFrame中的数据,原理是将这部分数据提取出来,重新赋值为新的数据。
import pandas as pd
df = pd.DataFrame([['zs', 12], ['ls', 4]], columns = ['Name','Age'])
df2 = pd.DataFrame([['ww', 16], ['zl', 8]], columns = ['Name','Age'])
df = df.append(df2)
df['Name'][0] = 'Tom'
print(df)