手写GPT实现小说生成(二)
引言
本文开始从零实现GPT1做一个小说续写器,即只需要给出一些文本,让模型帮你续写,主要内容包含:
- 模型编写
- 训练适配小说的中文分词器
- 将小说按固定大小拆分生成数据集
- 拆分训练/测试集
- 训练
- 体验小说续写效果
同时结合HuggingFace的transformers,可以将处理好的数据集、训练好的分词器和模型上传到HuggingFace Hub。
上篇文章中介绍了模型实现的大部分内容,本文继续模型的输出层。然后探讨除模型实现外同样重要的训练分词器、数据集生成以及如何训练等过程。
输出层
输出层采用Transformers中Head的思想,我们定义一个LMHead:
class GPTLMHeadModel(GPTPreTrainedModel):
"""The LM head model for the GPT model."""
def __init__(self, config: GPTConfig) -> None:
super().__init__(config)
# 定义GPT模型,命名为transformer
self.transformer = GPTModel(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.post_init()
同样继承GPTPreTrainedModel,定义一个GPTModel实例。同时定义一个线性层,用于将嵌入维度转换为词表大小维度。最后调用post_init参数初始化。
def forward(
self,
input_ids: torch.LongTensor,
labels: torch.LongTensor = None,
attention_mask: torch.FloatTensor = None,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
) -> Union[Tuple[torch.Tensor], CausalLMOutput]:
"""
Args:
input_ids (torch.LongTensor): (batch_size, sequence_length) Indices of input sequence tokens in the vocabulary.
labels (torch.LongTensor, optional): _description_. Defaults to None.
attention_mask (torch.FloatTensor) (batch_size, sequence_length) Mask to avoid performing attention on padding token indices.
output_attentions (bool, optional): Whether or not to return the attentions tensors of all attention layers. Defaults to False.
output_hidden_states (bool, optional): Whether or not to return the hidden states of all layers. Defaults to False.
return_dict (bool, optional): Whether or not to return a ModelOutput instead of a plain tuple. Defaults to True.
Returns:
Union[Tuple[torch.Tensor], CausalLMOutput]:
"""
# attention_mask转换为 (batch_size, 1, 1, sequence_length)的形状
if attention_mask is not None:
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype)
attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
transformer_outputs = self.transformer(
input_ids,
output_attentions=output_attentions,
attention_mask=attention_mask,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# hidden_states (batch_size, seq_len, n_embd)
hidden_states = transformer_outputs[0]
# lm_logits (batch_size, seq_len, vocab_size)
lm_logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
# 我们这里会进行偏移操作
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
if not return_dict:
# add hidden states and attention if they are here
output = (lm_logits,) + transformer_outputs[1:]
# return (loss, output) if loss is not None else output
return ((loss,) + output) if loss is not None else output
return CausalLMOutput(
loss=loss,
logits=lm_logits,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
我们这么定义是为了符合transformers的规范,返回的loss可以让该模型能在Trainer类中直接使用。
不仅如此,我们还可以调用transformers的save_pretrained或push_to_hub来保存或上传模型。
至此GPT模型定义好了,但是模型定义只是第一步,在模型能开始训练之前,我们还需要训练一个分词器。
当然实际上可以直接用别人训练好的分词器,但为了学习以及完整性,我们来看下如何利用tokenizers训练自己的分词器。
训练分词器
GPT使用的是字节级的字节对编码(BBPE)分词器,在中文上表现不佳。我们这里训练字节对编码(BPE)分词器即可。在之前的文章中我们探讨了如何编写自己的BPE分词器,本文我们利用tokenizers库来训练分词器。
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import BertPreTokenizer
from tokenizers.processors import TemplateProcessing, BertProcessing
from transformers import PreTrainedTokenizerFast
from transformers import AutoTokenizer
def train(file_path: str, save_path="tokenizer.json", vocab_size: int = 5000) -> None:
tokenizer = Tokenizer(BPE(unk_token="<|endoftext|>"))
# only has eos token
trainer = BpeTrainer(
special_tokens=["<|endoftext|>"], vocab_size=vocab_size
)
tokenizer.pre_tokenizer = BertPreTokenizer()
tokenizer.train([file_path], trainer)
tokenizer.post_processor = TemplateProcessing(
single="$A <|endoftext|>",
pair="$A <|endoftext|> $B:1 <|endoftext|>:1",
special_tokens=[
("<|endoftext|>", tokenizer.token_to_id("<|endoftext|>")),
],
)
print(f"vocab size: {tokenizer.get_vocab_size()}")
tokenizer.save(save_path)
下面就可以开始训练,训练速度非常快,训练好之后我们可以上传到HuggingFace Hub:
if __name__ == "__main__":
train("./data/novel.txt")
tokenizer = PreTrainedTokenizerFast(
tokenizer_file="tokenizer.json", model_max_length=512
)
if train_args.from_remote:
tokenizer.push_to_hub("greyfoss/simple-gpt-doupo")
else:
tokenizer.save_pretrained("greyfoss/simple-gpt-doupo")

上传完毕后,它默认会多创建几个文件,下次我们可以像使用其他分词器一样,从网上加载:
tokenizer = AutoTokenizer.from_pretrained("greyfoss/simple-gpt-doupo")
encodes = tokenizer("三十年河东三十年河西,莫欺少年穷!", "突破斗者!")
print(encodes)
print(tokenizer.convert_ids_to_tokens(encodes["input_ids"]))
[00:00:00] Pre-processing files (15 Mo) ███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 100%[00:00:00] Tokenize words ███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 405690 / 405690[00:00:01] Count pairs ███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 405690 / 405690[00:00:01] Compute merges ███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 1178 / 1178
vocab size: 5000
{'input_ids': [53, 456, 1127, 1941, 67, 53, 456, 1127, 1941, 3108, 3817, 2920, 1863, 4279, 2514, 3814, 0, 4531, 1620, 2735, 3814, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
['三', '十', '年', '河', '东', '三', '十', '年', '河', '西', ',', '莫', '欺', '少年', '穷', '!', '<|endoftext|>', '突破', '斗', '者', '!', '<|endoftext|>']
训练分词器就差不多了,但后面如果效果不行可能会调整分词器的一些参数,比如词表大小。
这里指定了一个特殊标记<|endoftext|>,同时作为未知标记和语句结束标记。
这里输入了一个语句对,分词结果为:
['三', '十', '年', '河', '东', '三', '十', '年', '河', '西', ',', '莫', '欺', '少年', '穷', '!', '<|endoftext|>', '突破', '斗', '者', '!', '<|endoftext|>']
可以看到在每句话的末尾添加了<|endoftext|>,并且token_type_ids正确标记出来了属于哪句话,这是通过上面代码指定的post_processor实现的。
在本文实现的小说生成任务重,很长的语句序列当成一个样本,即一个语句,因此可以不用考虑token_type_ids,这里只是介绍一下post_processor的用法。
以前面那句话为例:
['三', '十', '年', '河', '东', '三', '十', '年', '河', '西', ',', '莫', '欺', '少年', '穷', '!', '<|endoftext|>']
它对应的input_ids为:
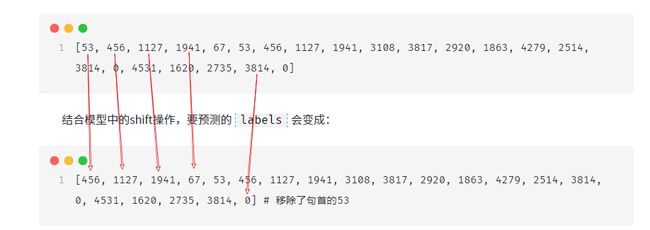
[53, 456, 1127, 1941, 67, 53, 456, 1127, 1941, 3108, 3817, 2920, 1863, 4279, 2514, 3814, 0, 4531, 1620, 2735, 3814, 0]
结合模型中的shift操作,要预测的labels会变成:
[456, 1127, 1941, 67, 53, 456, 1127, 1941, 3108, 3817, 2920, 1863, 4279, 2514, 3814, 0, 4531, 1620, 2735, 3814, 0] # 移除了句首的53
即模型通过:
'三'预测'十';'三', '十'预测'年';- …
'三', ... ,'穷', '!'预测'<|endoftext|>';
可以看到,模型的输入会移除末尾的'<|endoftext|>'对应的0 id。
在训练时:
shift_logits = lm_logits[..., :-1, :].contiguous() # 移除最后一个token
shift_labels = labels[..., 1:].contiguous() # 移除第一个token
# Flatten the tokens
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
即模型真正参与损失计算的logtis是
[53, 456, 1127, 1941, 67, 53, 456, 1127, 1941, 3108, 3817, 2920, 1863, 4279, 2514, 3814, 0, 4531, 1620, 2735, 3814] # 移除了最后一个0
对应产生的logits。对应上面说的:
'三'预测'十';'三', '十'预测'年';- …
'三', ... ,'穷', '!'预测'<|endoftext|>';
用一张图来描述就是:
处理数据集
有了分词器之后,我们还需要处理数据集。这里我们想实验的是文本生成(小说生成)任务,是一种无监督方式,见之前讨论的无监督预训练。
对于这里的小说生成任务,数据集中的样本直接是文本字符串即可。利用下三角注意力掩码,对于一个文本:“今天天气很好”。它的预测方式为:
“今” -> “今天”
“今天” -> “今天天”
“今天天” -> “今天天气”
“今天天气” -> “今天天气很”
“今天天气很” -> “今天天气很好”
从之前的Transformer文章我们知道,在训练时上面的这些过程其实是并行的,而在推理时,我们可以只输入"今",然后模型采用某种生成策略逐个Token进行预测下去,有些策略使生成的文本更流畅,但本文暂且不涉及,后续探讨GPT2的时候我们再来研究这些生成策略。
拿到一篇小说后,我们这里简单的当成一整个文档,然后按最大长度(比如1024)对整个文档进行拆分,最后可能会剩下一个不足1024的文本,直接丢弃掉。相当于这样我们在训练时无需填充。
直接来看代码:
def get_tokenized_datasets(text_path: str, tokenizer: AutoTokenizer) -> Dataset:
data_files = {"train": text_path}
# load raw datasets
raw_datasets = load_dataset("text", data_files=data_files, sample_by="document")
max_seq_length = tokenizer.model_max_length
def tokenize_function(examples):
return tokenizer(
examples["text"],
add_special_tokens=True,
truncation=True,
max_length=max_seq_length,
return_overflowing_tokens=True,
)
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
remove_columns="text",
desc="Running tokenizer on every text in dataset",
)
# just drop last example
tokenized_datasets = tokenized_datasets.filter(
lambda example: len(example["input_ids"]) == max_seq_length
)
tokenized_datasets = tokenized_datasets.remove_columns("overflow_to_sample_mapping")
# split train and valid
train_valid = tokenized_datasets["train"].train_test_split(test_size=0.05)
tokenized_datasets = DatasetDict(
{
"train": train_valid["train"],
"valid": train_valid["test"],
}
)
return tokenized_datasets
其中定义了一个内部函数:
def tokenize_function(examples):
return tokenizer(
examples["text"],
add_special_tokens=True, # 在每个样本后面增加EOS标记
truncation=True, # 超过最大长度的截断
max_length=max_seq_length, # 设置最大长度
return_overflowing_tokens=True, # 进行循环拆分
)
如果某个样分词后的长度超过max_seq_length,那么会从max_seq_length(512)处截断,由于return_overflowing_tokens=True,因此会继续拆分出第二个样本,这样进行循环拆分。
由于我们将整个数据集拼接成一个超大的文档,然后对其按max_seq_length分块(chunk)进行拆分,最后移除最后一个块(因为它大概率会小于max_seq_length),保证每个样本的长度一致,这样就不需要填充。
最后拆分训练和验证集,这里拆分时默认会进行打乱操作。
if train_args.from_remote:
tokenizer = AutoTokenizer.from_pretrained(
f"{train_args.owner}/{train_args.model_name}"
)
else:
tokenizer = AutoTokenizer.from_pretrained(train_args.model_name)
tokenized_datasets = get_tokenized_datasets(
text_path="./data/novel.txt", tokenizer=tokenizer
)
print(tokenized_datasets)
if train_args.from_remote:
tokenized_datasets.push_to_hub(f"{train_args.owner}/{train_args.dataset_name}")
else:
tokenized_datasets.save_to_disk(train_args.dataset_name)
最后得到的训练集大小为7000左右;验证集大小为360左右;每个样本长度为max_seq_length,同样也将该数据集推送到Hub上。

定义数据加载器
tokenized_dataset = load_dataset(f"{train_args.owner}/{train_args.dataset_name}")
tokenized_dataset.set_format("torch")
train_dataset = tokenized_dataset["train"]
eval_dataset = tokenized_dataset["valid"]
batch_size = int(train_args.batch_size / train_args.gradient_accumulation_steps)
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=default_data_collator,
)
eval_dataloader = DataLoader(
eval_dataset,
batch_size=batch_size,
collate_fn=default_data_collator,
)
因为我们的数据集中的样本长度都是512,并且不包含填充Token,因此直接使用default_data_collator进行数据打包成批次即可。
模型训练
定义训练参数:
@dataclass
class TrainArguments:
batch_size: int = 16
weight_decay: float = 1e-1
epochs: int = 50
warmup_proportion: float = 0.05
learning_rate: float = 4e-5
logging_steps = 100
gradient_accumulation_steps: int = 1
max_grad_norm: float = 1.0
use_wandb: bool = False
from_remote: bool = True
dataset_name: str = "doupo-dataset"
model_name: str = "simple-gpt-doupo"
tokenizer_name: str = "simple-gpt-doupo"
owner: str = "greyfoss"
devices: str = "0"
train_args = TrainArguments()
定义训练函数:
def train(model, train_dataloader, val_dataloader, optimizer, device, scheduler, args):
max_grad_norm = args.max_grad_norm
logging_steps = args.logging_steps
gradient_accumulation_steps = args.gradient_accumulation_steps
total_loss = 0.0
logging_loss = 0.0
best_loss = 10000
global_steps = 0
early_stopper = EarlyStopper()
for epoch in range(args.epochs):
model.train()
p_bar = tqdm(train_dataloader, disable=False)
for step, batch in enumerate(p_bar):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(batch["input_ids"], labels=batch["input_ids"])
loss = outputs.loss
total_loss += loss.item()
p_bar.set_description(
f"epoch {epoch + 1:2d} (loss={loss.item():5.3f} | global_steps {global_steps:4d} | lr {scheduler.get_last_lr()[0]:.5f} )"
)
if gradient_accumulation_steps > 1:
loss = loss / gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
if (step + 1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
global_steps += 1
if logging_steps > 0 and global_steps & logging_steps == 0:
if args.use_wandb:
train_loss = (total_loss - logging_loss) / (
logging_steps * gradient_accumulation_steps
)
wandb.log(
{
"global_steps": global_steps,
"lr": scheduler.get_lr()[0],
"train_loss:": train_loss,
}
)
logging_loss = total_loss
eval_loss = evalute(model, val_dataloader, device)
logger.info(
f"epoch {epoch} | global_steps {global_steps} | eval loss {eval_loss:.3f}"
)
if args.use_wandb:
wandb.log({"epoch": epoch, "eval_loss:": eval_loss})
if eval_loss < best_loss:
best_loss = eval_loss
logger.info(
f"Saving model to {args.model_name} with best eval loss {eval_loss:.3f}"
)
# save to local disk
model.save_pretrained(f"{args.model_name}")
torch.cuda.empty_cache()
if early_stopper.step(eval_loss):
print(f"Stop from early stopping.")
break
和之前的差不多,比较简单。
@torch.no_grad()
def evalute(model, dataloader, device):
model.eval()
p_bar = tqdm(dataloader, desc="iter", disable=False)
total_loss = 0.0
for batch in p_bar:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(batch["input_ids"], labels=batch["input_ids"])
total_loss += outputs.loss.item()
test_loss = total_loss / len(dataloader)
return test_loss
而评估函数仅使用验证集上的损失。
if __name__ == "__main__":
# run train_tokenizer.py to get tokenizer
if train_args.from_remote:
tokenizer = AutoTokenizer.from_pretrained(
f"{train_args.owner}/{train_args.tokenizer_name}", use_fast=True
)
else:
tokenizer = AutoTokenizer.from_pretrained(
f"{train_args.tokenizer_name}", use_fast=True
)
if train_args.use_wandb:
import wandb
wandb.init(
project="simple-gpt",
config=vars(train_args),
)
config = GPTConfig()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GPTLMHeadModel(config)
model.to(device)
# run data_process.py to get dataset
if train_args.from_remote:
tokenized_dataset = load_dataset(
f"{train_args.owner}/{train_args.dataset_name}"
)
else:
tokenized_dataset = load_from_disk(f"{train_args.dataset_name}")
tokenized_dataset.set_format("torch")
train_dataset = tokenized_dataset["train"]
eval_dataset = tokenized_dataset["valid"]
batch_size = int(train_args.batch_size / train_args.gradient_accumulation_steps)
train_dataloader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=default_data_collator,
)
eval_dataloader = DataLoader(
eval_dataset,
batch_size=batch_size,
collate_fn=default_data_collator,
)
total_training_steps = int(
train_args.epochs
* len(train_dataloader)
/ train_args.gradient_accumulation_steps
)
print(f"total train steps={total_training_steps}")
optimizer = AdamW(
get_grouped_params(model, weight_decay=train_args.weight_decay),
lr=train_args.learning_rate,
)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=int(train_args.warmup_proportion * total_training_steps),
num_training_steps=total_training_steps,
)
train(
model,
train_dataloader,
eval_dataloader,
optimizer,
device,
lr_scheduler,
train_args,
)
model = GPTLMHeadModel.from_pretrained(f"{train_args.model_name}")
generated_text = generate(model, tokenizer, device, "肖炎经过不懈地修炼,终于突破到了斗帝级别")
print(f"generated text: {generated_text}")
if train_args.from_remote:
logger.info(f"Pushing model to {train_args.owner}/{train_args.model_name}")
model.push_to_hub(f"{train_args.owner}/{train_args.model_name}")
...
epoch 37 (loss=2.495 | global_steps 16057 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.30it/s]
2024-01-25 16:47:49 - INFO - root - epoch 36 | global_steps 16058 | eval loss 3.511
2024-01-25 16:47:49 - INFO - root - Saving model to simple-gpt-doupo with best eval loss 3.511
epoch 38 (loss=2.478 | global_steps 16491 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.26it/s]
2024-01-25 16:50:23 - INFO - root - epoch 37 | global_steps 16492 | eval loss 3.512
2024-01-25 16:50:23 - INFO - root - early stop left: 4
epoch 39 (loss=2.456 | global_steps 16925 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.25it/s]
2024-01-25 16:52:56 - INFO - root - epoch 38 | global_steps 16926 | eval loss 3.509
2024-01-25 16:52:56 - INFO - root - Saving model to simple-gpt-doupo with best eval loss 3.509
epoch 40 (loss=2.442 | global_steps 17359 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.28it/s]
2024-01-25 16:55:30 - INFO - root - epoch 39 | global_steps 17360 | eval loss 3.509
2024-01-25 16:55:30 - INFO - root - Saving model to simple-gpt-doupo with best eval loss 3.509
epoch 41 (loss=2.437 | global_steps 17793 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.23it/s]
2024-01-25 16:58:05 - INFO - root - epoch 40 | global_steps 17794 | eval loss 3.508
2024-01-25 16:58:05 - INFO - root - Saving model to simple-gpt-doupo with best eval loss 3.508
epoch 42 (loss=2.411 | global_steps 18227 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.23it/s]
2024-01-25 17:00:39 - INFO - root - epoch 41 | global_steps 18228 | eval loss 3.508
2024-01-25 17:00:39 - INFO - root - early stop left: 4
epoch 43 (loss=2.385 | global_steps 18661 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.12it/s]
2024-01-25 17:03:12 - INFO - root - epoch 42 | global_steps 18662 | eval loss 3.509
2024-01-25 17:03:12 - INFO - root - early stop left: 3
epoch 44 (loss=2.360 | global_steps 19095 | lr 0.00001 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.24it/s]
2024-01-25 17:05:45 - INFO - root - epoch 43 | global_steps 19096 | eval loss 3.509
2024-01-25 17:05:45 - INFO - root - early stop left: 2
epoch 45 (loss=2.370 | global_steps 19529 | lr 0.00000 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.24it/s]
2024-01-25 17:08:18 - INFO - root - epoch 44 | global_steps 19530 | eval loss 3.511
2024-01-25 17:08:18 - INFO - root - early stop left: 1
epoch 46 (loss=2.354 | global_steps 19963 | lr 0.00000 ): 100%|██████████| 434/434 [02:30<00:00, 2.88it/s]
iter: 100%|██████████| 23/23 [00:02<00:00, 11.26it/s]
2024-01-25 17:10:51 - INFO - root - epoch 45 | global_steps 19964 | eval loss 3.511
Stop from early stopping.
肖炎经过不懈地修炼,终于突破到了斗帝级别,而这,便是萧炎所展现而出的恐怖实力。当然,这也正是因为那传说之中的天墓之魂,方才使得他晋入了八星斗圣后期的地步,不然的话,光凭借着这九品玄丹,便是能够达到七品高级的层次,可远非他可比。“现在怎么可能”药老沉吟道。萧炎默默点头,旋即苦笑道:“我倒是要看看,你能否突破到斗圣”“嗯”萧炎点了点头,手掌轻轻磨挲着下巴,眼中掠过一抹喜意,对于那所谓的“帝品雏丹”,他可是相当的熟悉,而且他也知道,这个世界上,有着什么东西,就算是他都没有想到过,萧炎居然会在他看来,真的能够将其当做到这种地步“那是陀舍古帝的帝玉”心中念头飞转动,药老也是有些惊愕,以他如今的实力,即便是古族,都是无法与其相抗衡,毕竟,如果这天地间的能量,还具备着帝境灵魂的能力的话,那他必然会有半点的作用,因此,说起来,也没什么好奇怪的东西。见到药老这般模样,萧炎也是一笑,伸出手来,将古玉收入纳戒,然后目光转向药老,轻声道:==第一千两百四十一章交易会的宝贝,虽说如今萧炎的实力,但也并非是不可能的事,不管怎样,至少,现在的他,已是达到了八品巅峰层次。听得药老此话,萧炎眉头也是微微一皱,既然如此,那么想必他也是明白,这位神秘的远古种族,究竟是何等的可怕了吧“呵呵,多谢前辈出手了”在萧炎身后,天火尊者也是笑眯眯的道。闻言,烛离长老也是笑着点了点头,看来他对萧炎也很是感到棘手了,若是他不想象中的那般容易便是将萧炎给予了他极大的危险感觉,恐怕就得当场毙命了“这小子,果然不是寻常人物,难怪连他都是能够遇见的斗尊强者”见到这一幕,萧炎心中也是忍不住的有些欣喜,连忙道,当年他尚还只是一个稚嫩的小辈而已,然而如今,如今却是已然无人能及,没想到,在这中州,居然还有这等传承了这么多年,不知道多少人
训练了45个epoch后触发了早停,在3090上训练,平均每个epoch耗时2分30秒左右。
使用AdamW优化器和带有热加载的线性学习率调度器,训练完成之后加载验证集上最佳的模型并上传到Hub。
模型推理
from transformers import AutoTokenizer
import torch
from modeling_gpt import GPTLMHeadModel
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("greyfoss/simple-gpt-doupo")
model = GPTLMHeadModel.from_pretrained("greyfoss/simple-gpt-doupo").to(device)
prefix = "肖炎经过不懈修炼,终于达到一个俯视一众强者的高度"
input_ids = tokenizer.encode(prefix, return_tensors="pt", add_special_tokens=False).to(
device
)
for i in range(3):
beam_output = model.generate(
input_ids,
max_length=512,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True,
do_sample=True,
top_k=50,
top_p=0.95,
repetition_penalty=1.25,
)
print("-" * 219)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True).replace(" ", ""))
由于我们的模型继承了HuggingFace Transformers相关的类,所以可以调用model.generate进行生成。
分词器和训练好的模型上传到了"greyfoss/simple-gpt-doupo",大家也可以体验,不过要注意使用GPTLMHeadModel.from_pretrained("greyfoss/simple-gpt-doupo")来加载权重,因为是自定义模型。
下面是生成结果:

其中生成的参数top_p和top_k等会在下篇文章GPT2中进行详解。
可以看到生成的结果单个几个句子的话是通顺的,但一起看感觉主题不明显且不连贯。期望GPT2的效果会更好一点。
尴尬,才发现主角的姓写错,不过模型生成的结果纠正了。
完整代码
https://github.com/nlp-greyfoss/nlp-in-action-public
参考
- HuggingFace GPT源码
- GAUSSIAN ERROR LINEAR UNITS (GELUS)
- 共享自定义模型