万字图解 | 深入揭秘IP层工作原理
大家好,我是「云舒编程」,今天我们来聊聊计算机网络面试之-(网络层ip)工作原理。
文章首发于微信公众号:云舒编程
关注公众号获取:
1、大厂项目分享
2、各种技术原理分享
3、部门内推
前言
想必不少同学在面试过程中,会遇到「在浏览器中输入www.baidu.com后,到网页显示,其间发生了什么」类似的面试题。
本专栏将从该背景出发,详细介绍数据包从HTTP层->TCP层->IP层->网卡->互联网->目的地服务器 这中间涉及的知识。
本系列文章将采用自底向上的形式讲解每层的工作原理和数据在该层的处理方式。
系列文章
图解 | 深入揭秘数据链路层、物理层工作原理
图解 | 深入揭秘IP层工作原理
图解 | 深入揭秘TCP工作原理
图解 | 深入揭秘HTTP工作原理
图解 | 深入揭秘Linux 接收网络数据包
图解 | 深入揭秘IO多路复用原理
通过上一篇文章每天5分钟玩转计算机网络-(数据链路层、物理层)工作原理的介绍,我们知道了数据链路层和物理层的基本工作原理。同时也知道了mac地址和ip地址的区别。
在上一篇只是简单引入了ip的概念。本篇将会详解对网络层(ip)进行介绍。
通过本文你可学到:
- ip地址构成
- 公有IP地址和私有ip地址
- ip路由原理
- ip分片与重组
IP基础知识
❝
IP是整个网络架构中的心脏,你的请求可以跨过大洋彼岸,准确的到达目的服务器,就是IP提供的能力。它实现了网络设备点对点通信。
❞
IP地址构成
IP地址(IPv4)由32位正整数构成,在计算机中采用二进制表示。但是为了方便记忆和查看,一般采用点分十进制进行书面表示。也就是将 32 位 IP 地址以每 8 位为组,共分为 4 组,每组以“.”隔开,具体格式如下:
 由于限制了IPv4由32位组成,那么IP最大可以表示的值为:2^32=4294967296,也就是最多允许42.9亿多台计算机进行网络连接。
由于限制了IPv4由32位组成,那么IP最大可以表示的值为:2^32=4294967296,也就是最多允许42.9亿多台计算机进行网络连接。
❝
这里肯定会有人有疑问了:按照现在的互联网发展,网络上的设备早就超过42.9亿多了,那为什么互联网还是在正常运行呢?
其实这得益于两方面的技术:ipv6和NAT。后面会详解介绍
❞
IP 地址的分类
互联网初开之时,网络上的设备还没有这么多,42亿多的IP地址显得非常充足。于是大佬们大手一挥,决定将IP地址进行三六九等区分,方便进行管理。
IP地址于是被分为了五类:A类、B类、C类、D类、E类。
同时还分为了网络号和主机号,网络号可以对比是小区,主机号可以对比是小区里的房间
❝
网络号和主机号的划分是为了实现网络地址的层次化管理。通过将网络号和主机号分开,可以将一个大的 IP 地址空间分成多个子网,每个子网可以包含多台计算机。这样可以更好地管理网络资源。
❞

A类:第一位固定为0,紧接着的7位为网络位,剩下的24位为主机位。
B类:前两位固定为10,紧接着的14位为网络位,剩下的16位为主机位。
…
其余类推。
所以ip是按照以下原则进行层次分配的:

上述的ip分配原则,具有明显的缺点:
- 资源无法合理分配
-
-
A类地址的主机位为24位,可以容纳2^24=16777216台主机。
-
B类可以容纳2^16=65536台主机。
-
C类可以容纳2^8=256台主机
C类网络的主机数不够用,A类,B类的主机有太多了。
-
- 同一网络号下的ip无法再次进行层次划分
- 无法组建超网
-
- 假设你拥有几个不同网络号的连续ip地址,你想把他们组合起来,形成自己的超级网络。但是由于网络号的固定划分方式,发现无法做到
于是人们开始放弃IP地址分类,采用任意长度分割IP地址的网络标识和主机标识。这种方式叫做CIDR(无类型域间路由)。
CIDR(无类型域间路由)
a.b.c.d/x
CIDR采用 a.b.c.d/x 的形式表示IP,其中 /x 表示前 x 位属于网络号, x 的范围是 0 ~ 32,这使得 IP 地址更加具有灵活性。
例如:
203.183.224.0/24

| 地址数 | 2^8-1=255 |
|---|---|
| 网络号 | 203.183.224.0 |
| 第一个IP地址 | 203.183.224.1 |
| 最后一个IP地址 | 203.183.224.255 |
CIDR应用的初期,网络内部采用固定长度的子网掩码机制,也就是说,当子网掩码的长度被设置后,域间的所有子网掩码都得使用同样的长度。
但是假如一个公司的市场部有100台电脑,销售部有70台电脑,一般企业中会希望将不同的部门划分成为不同的网段,一方面为了安全,一方面是为了方便网络管理。
如果想用c类地址段分别给三个部门划分不同的网段,我们看到需要用到三个c类地址段,我们知道一个c类地址段里就有254个主机地址,而这里用到了三个c类地址段,就造成了ip地址浪费的情况,为了保证ip地址的高利用率,这时候我们用到了vlsm(可变长子网掩码)。
可变长子网掩码(vlsm)
除了使用上诉a.b.c.d/x分割网络号主机号,还可以使用子网掩码的形式进行分割。
❝
子网掩码仅具有一项功能,即将IP地址分为两部分,即网络地址和主机地址。子网掩码也是由32构成,子网掩码不能单独存在,必须与IP地址一起使用。
❞
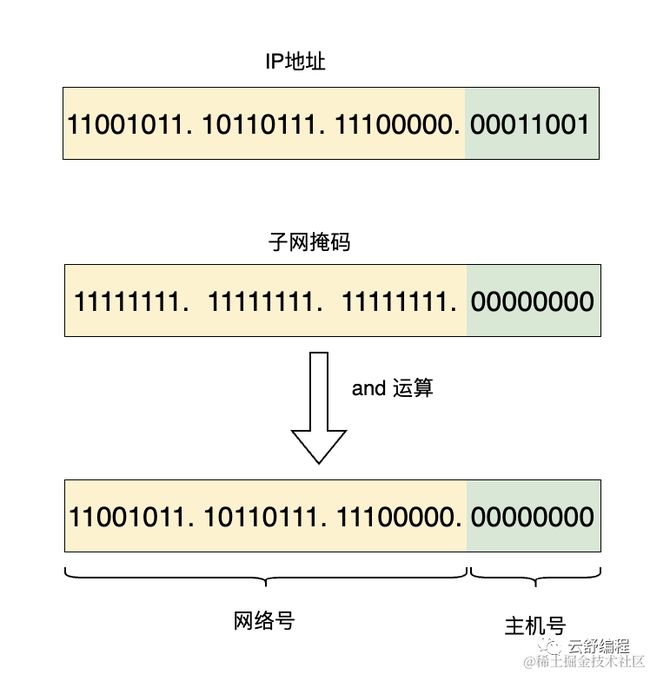
将ip地址跟子网掩码进行and运算,就可以得到IP地址的网络号。
例如图中IP地址为:203.183.224.1,子网掩码为:255.255.255.0。两者and运算得到:203.183.224.0。这就是该IP对应的网络号。同时子网掩码不为0的部分有8位,所以主机部分有8位可以进行分配。
变长子网掩码的应用
还是以上面的公司举例:
假设公司有一个C类地址:192.168.1.0 我们都知道这样一个c类地址段里有256个地址,接下来我们将这256个地址划分成两个不同的网段,一个给市场部,一个给销售部。
假设我们从8位主机位中借一位,当做内部网段的网络位:

那么市场部的网络号就是:11000000.10101000.00000001.0 0000000(后面7位可以分配给主机)
那么销售部的网络号就是:11000000.10101000.00000001.1 0000000(后面7位可以分配给主机)
那么相应的子网掩码就变为:11111111.11111111.11111111.1 0000000,表示为10进制:255.255.255.128
同样的,只要主机位有剩余的位可以借,市场部内部还可以继续划分为市场部一、市场部二。
通过这样的形式就可以把网络划分为不同的子网。
IP路由控制
前面已经了解了IP的构成,接下来进入本章的重点:路由控制
再次回顾上一篇最后画的网络拓扑图:

❝
补充:其中A,D的子网掩码都为255.255.255.0
❞
假设A现在要发消息到D,也就是192.168.0.1要发消息到192.167.0.1。
- A根据自己的子网掩码计算自己的IP地址和D的IP地址,发现结果不一样,于是判断出D与自己不在同一个子网
- 根据规则,A会将消息发送给默认网关,然后由默认网关进一步判断下一步发给谁
- A通过ARP协议获取默认网关的mac地址,然后封装消息发送给网关,消息格式:

4. 默认网关(一般是路由器),收到请求后会根据自己路由表判断下一步该发给谁(可能是路由器,也有可能是交换机)
4. 如果继续发给了路由器,那么路由器会继续跟进自己的路由表判断下一步发给谁,通过接力的形式转发到目的地
4. 如果发给了交换机,那么交换机将会直接广播给全部主机
默认网关
默认网关是提前配置好的一条路由规则,存储在路由表中,一般使用default标识。
默认网关一般情况下由路由器担当。
❝
A的默认网关必须跟A在同一个子网,D的默认网关必须跟D在同一个子网。但是A的默认网关可以不跟D的默认网关在同一个子网
❞

通常情况下,默认网关的IP地址就是直接连接的路由器的某个端口的IP地址。
一般情况下,当主机发现目的IP跟自己不是同一个子网时,就会把消息发给默认网关,由默认网关进行下一步处理。
ARP协议
前面说到,A发送消息给默认网关时,需要知道默认网关的mac,但是路由表中只有ip地址,该怎么获取mac地址呢?这就是arp协议的作用了。
当A需要知道某个ip的mac地址时,他就会广播arp消息:ip=xxx的mac地址是多少啊。当同一个子网上的设备收到消息后会判断ip与自己是否一致,一致的话就会响应消息:我的mac地址是xxx
路由表
当A把消息发送给路由器后,路由器怎么知道把消息发送给D呢?
这就是路由表的功能了。
❝
路由表是一个存储在路由器或者联网计算机中的电子表格(文件)或类数据库。它存储了网络周边的拓扑信息。他为路由器指明了怎么把收到的消息包正确发送出去。
❞
格式
路由表主要由以下几部分组成:
| 目的网络/掩码 | 协议类型 | 开销 | 下一跳 | 输出接口 |
|---|
路由规则
假设有如下路由拓扑:

A现在要发消息到D,也就是10.1.1.30要发消息到10.1.2.0。
- A根据自己的子网掩码计算自己的IP地址和D的IP地址,发现结果不一样,于是判断出D与自己不在同一个子网
- 根据规则,A会将消息路由器1(默认网关)
- 路由器1根据最长IP匹配原则,发现10.1.2.10跟10.1.2.0/24前缀匹配匹配上的长度最长,于是选择
| 10.1.2.0/24 | 10.1.0.2 | 2 |
|---|
这条路由规则将消息从端口2发送给10.1.2.1(路由器2)
- 路由器2收到消息后同样根据最长IP匹配原则,发现10.1.2.0/24前缀匹配匹配上的长度最长,于是选择
| 10.1.2.0/24 | 10.1.2.1 | 2 |
|---|
这条路由规则将消息从端口2发送给D
路由表是怎么生成的
静态路由
静态路由一般就是手动配置的,可管理性高。
缺点:
1、如果网络特别庞大、设备数量特别,配置的工作量就相当大了,这是很低效的;
2、静态路由无法根据网络拓扑的变更做出动态响应,因此当网络发生变化时,管理员可能不得不重新配置或调整静态路由。
所以静态路由一般很少使用。这里我们也不做讲解。
动态路由
❝
动态路由可以根据特定的算法策略,通过路由器之间不断地交互信息,从而建立和更新自己的路由表。可以更好的适应网络变化
❞
目前比较常用的是:基于链路状态路由算法的OSPF(Open Shortest Path First,开放式最短路径优先)
它把链路状态信息的获取分成了4个主要步骤:
- 发现节点
-
- 当一个路由器启动的时候,使用单播(Unicast)和组播(Multicast)来发送Hello包。收到这条消息的节点必须回应一条Response消息,告知自己是谁。
- 每个节点只要统计自己发出hello后收到的回应数量,就可以知道自己和哪几个节点相邻,也知道了它们的地址之类的信息,保存在本地就可以了。
- 测量链路成本
-
- 现在每个路由器都有了自己的邻居信息,接下来要做的就是衡量边权也就是链路成本。
- 每个节点向自己的邻居发送一个特殊的echo包,邻居收到之后,必须原封不动地把echo再返回给发出echo的节点,这样,每个节点只需要统计一下自己从发出echo到收到echo的时间差,然后取多次的平均值,就可以用它来估计和邻居之间的网络传输时延了(RTT),从而也就可以计算出链路状态算法所需要的链路成本了。
- 封装链路状态包
-
- 每个路由器都知道自己到所有邻居节点的链路成本了,现在只要每个路由器把自己收集到的信息广播出去,同时也尽快收集别人的信息,就可以拼接出整个路由的拓扑图。
- 状态链路包格式:
| 本机ID | |
|---|---|
| 序号 | |
| 生存期 | |
| 邻居1 | 链路成本 |
| 邻居2 | 链路成本 |
| 。。。 |
- 发送链路状态包
-
- 泛洪:计算机网络中常用的一种传播消息的机制,类似广播,每个节点都会把自己封装好的包和收到的包,发送或转发给所有除了该包发送方的节点。
- 这样,经过一小段时间的传播,每个节点就可以收到整个网络内所有其他节点的邻居信息,从而也就相当于有了一个拓扑图中邻接表的全部信息,就可以在内存中构建出一张完整的路由表了。

image.png
- 计算路由
-
- 根据收集到的信息,使用Dijkstra 算法,在有向图中计算出自己到网络中任何其他所有节点的最短路径。
A的最短路
A->B
A->B->D
A->B->D->E
A->B->D->E->F
A->C
A的路由表
Destination Gateway
B B
C C
D B
E B
F B
IP 报文分片与重组
类似我们在日常生活中寄快递,如果我们的东西非常多,那么会把东西分别打包成几个包裹再进行寄送。
在网络中也是一样的,受限于光缆和路由器内存限制,所以单个数据数据包不能过大,过大时需要分割成几个数据包再进行发送。
MTU
- MTU规定了每种数据链路的最大传输单元,类似我们最常见的以太网MTU就是1500字节。
- 那么当 IP 数据包大小大于 MTU 时, IP 数据包就会被分片。数据包分片可以在主机或者路由器进行,但是重组只能在主机进行。
- 假设需要发送4342字节的数据,由于MTU=1500,那么数据包就会被分割成3个数据包发送出去
分片与重组过程
IP报文的首部格式如下:

其中以下三个字段控制IP分片重组
![]()
-
标识(identification)占16位。
IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP是无连接服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU而必须分片时,这个标识字段的值就被复制到所有的数据报片的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报
-
标志(flag)占3位。
标志字段中由三部分组成(保留+DF+MF):但目前只有最后两位有意义。
-
- MF=1即表示后面“还有分片”的数据报。
- MF=0表示这已是若干数据报片中的最后一个。
- 标志字段中间的一位记为DF(Don’t Fragment),意思是“不能分片”。只有当DF=0时才允许分片。
-
片偏移,占13位。表示一个分片相对于原始 IP 包开头的偏移量,以 8 字节为单位;这就是说,每个分片的长度一定是8字节(64位)的整数倍,最后一片除外。
分片
还是以前面说的为例:假设需要发送4342字节的数据,由于MTU=1500,那么数据包就会被分割成3个数据包发送出去。

分片一:包含原包前 1480 字节数据,因此偏移量 offset=0 ,而 MF=1 表示后面还有其他分片。
分片二:包含原包紧接着的 1480 字节数据,偏移量 offset=1480/8=185 ,MF=1 ;
分片三:包含原包最后 1381 字节数据,偏移量 offset=(1480+1480)/8=370 ,MF=0 表示它是最后一片了。
重组
目标主机操作系统会分配一块内存作为重组分片的缓冲区,缓冲区存在多个队列。
- 分片达到后,系统根据(标识、源地址、目标地址、协议)计算出hash值,判断该hash值对应的队列是否存在,存在则把数据放入该队列,不存在则新建队列后再放数据。
- 根据报文的片偏移值将报文插入到分片队列中合适的位置。
- 判断报文是否全部到达
-
- 片偏移=0,代表第一个分片报文已经到了,INET_FRAG_FIRST_IN
- MF=0,代表最后一个分片报文已经到了,INET_FRAG_LAST_IN
- 所有报文数据部分的长度之和是否等于ip头部中的总长度-首部长度
- 校验报文是否完整
- 投递给上层
结尾
经过ip层的补充讲解,现在我们的网络分层长这样了,接下来我们需继续讲解TCP层。

推荐阅读
1、原来阿里字节员工简历长这样
2、一条SQL差点引发离职
3、MySQL并发插入导致死锁
如果你也觉得我的分享有价值,记得点赞或者收藏哦!你的鼓励与支持,会让我更有动力写出更好的文章哦!
更多精彩内容,请关注公众号「云舒编程」