Zookeeper+Kafka+Log4j日志采集与管理系统
1、Zookeeper+Kafka+Log4j-日志采集与管理
随着系统规模变大和复杂度上升,我们的日志管理变得复杂,一个完整的系统通常会有几十上百个节点。
如何方便管理我们的日志,动态的调整我们的日志级别变得非常重要,前文讲过如何构建一个千亿级的日志搜索系统。
本篇文章重点介绍如果搭建一套日志采集与管理系统,重点包含如下几个功能:
1) 应用节点的状态监控,离线及时告警、断线重连;
2) 日志级别动态修改,根据业务需要动态调整日志的打印级别和上报级别;
3) 消息的动态路由,动态调节消息的路由,应对突发情况,定向分析业务问题;
4) 不停服切换Kafka集群,无感知切换Kafka集群,故障转移;
5) 监控每个应用节点各级别的日志量;
6) 采集应用的各项KPI,监控并告警。
如下是架构图:

分为三个部分:客户端、配置管理中间件、日志管理器、存储。
2、客户端
封装Log4j的Java客户端
如下是客户端响应日志级别调整的流程图:

客户端监听Zookeeper的配置变化,动态调整日志级别,客户端启动之后第一时间上报自己的配置信息给Zookeeper,管理器监听到配置变化将变更的数据更新到数据库,这里我们使用MongoDB,实际中可以根据自己掌握的技术选择数据库,MongoDB是目前比较热门的NoSQL数据库,后面的章节会单独介绍。
客户端与Zookeeper建立长连接,保持会话,一旦客户端异常宕机或无响应,Zookeeper会将会话超时事件发送给管理器,此时管理器监听到客户端离线,将发送离线告警,通知运维人员处理,当然,也可以使用Zabbix监听应用的端口,但这样每部署一个应用或者修改端口zabbix都要重新监听,使用Zookeeper的会话来做应用状态监听能较少很多维护工作,应用一旦启动就会注册到Zookeeper,异常宕机Zookeeper将监听到离线。
实际应用过程中我们需要在客户端捕捉Zookeeper的断连,有时候是闪断或者网络抖动,此时客户端监听断连事件,重新连接到Zookeeper,保持健壮性。
如下是动态路由流程图:
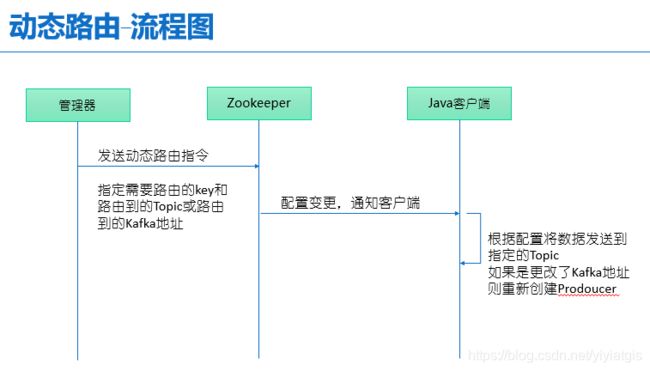
客户端收到Zookeeper的配资变化,根据下发的路由信息动态将数据发送到Kafka对应的Topic,如果是变更Kafka配置则重新创建Kafka Producer发送数据到新的Kafka。
这样设计能让客户端无感知的路由数据,在进行特定的业务分析时比较实用,另外,在服务器进行Kafka升级或者故障转移时很有帮助,可以在应用无感知的情况下进行Kafka的升级和地址的变更。
Go客户端
Go客户端的原理和Java客户端的原理一样,如下文件日志采集的流程图

Go客户端主要是采集文件日志上传到S3,前面的文章里讲过离线日志采集的架构,这里的Go客户端从管理器获取当前应用的进程和运行路径(一般说来我们在生产环境中要规范应用的部署路径和日志的存放路径和格式),获取路径之后自动添加文件路径监控,定期上传到指定的S3,这里的S3配置信息保存在管理器,当有变更时广播到Go客户端,当需要人为调整采集路径时通过发送配置变更给Zookeeper,Go客户端监听到配置变更,开始监听文件路径,定时上传。
设计客户端日志采集器要注意一下几点:
1) 尽可能的考虑异常场景,尽量不要人工干预才能恢复,做到异常情况自动恢复;
2) 异步,对应用程序尽量少的影响,不要影响主业务,设计时要考虑但应用的性能,达到一定量级处理不过来要发送告警,同时自我保护,策略性丢弃掉装不下的数据,通过打印日志来溯源;
3) 性能优化到极致,尽可能少的使用资源。
3、配置管理中间件
Zookeeper
这里用到了Zookeeper作为配置管理中心,Zookeeper是目前业界使用得比较多的配置管理工具,阿里巴巴的Dubbo也使用了Zookeeper作为配置管理工具,
Zookeeper除了配置管理还能协调分布式系统,后续的章节会专门讲到。
Apache Zookeeper地址
https://zookeeper.apache.org/
Kafka
Kafka是一款高性能的消息队列中间件,具有很好的吞吐性,目前业界很多事实流分析都使用Kafka作为消息中间件,后续的章节会专门讲到。
Apache Kafka地址
http://kafka.apache.org/