强化学习原理python篇04——迭代法
强化学习原理python篇04——迭代法
- Value iteration
-
- 数学原理
- 算法步骤
- 实例及python实现
- policy iteration
-
- 数学原理
- 算法步骤
- 实例及python实现
- Truncated policy iteration
- Ref
本章全篇参考赵世钰老师的教材 Mathmatical-Foundation-of-Reinforcement-Learning OValue Iteration and Policy Iteration章节,请各位结合阅读,本合集只专注于数学概念的代码实现。
Value iteration
数学原理
值更新策略
v k + 1 = m a x π ∈ Π ( r π + γ P π v k ) v_{k+1} = max_{π\in \Pi }(rπ + γP_πv_k) vk+1=maxπ∈Π(rπ+γPπvk)
v k v_k vk 和 π k \pi_k πk 收敛到最优状态值和最优策略,当 k → ∞ k\rightarrow \infin k→∞

算法步骤
- 第一步,q_table给定状态值
- 第二步,计算q_value
- 第三步:选择最优策略
- 第四步:根据最优策略计算
- 第五步:更新 v
实例及python实现
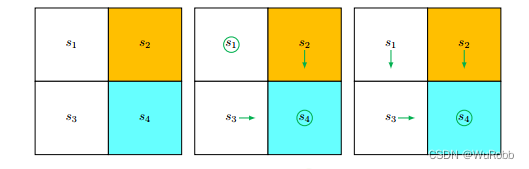
import numpy as np
import math
q_table = np.array(
[
[-1, -1, 0, -1, 0],
[-1, -1, 1, 0, -1],
[0, 1, -1, -1, 0],
[-1, -1, -1, 0, 1],
]
)
def q_table_v_matrix_methods(v):
# the state values matrix for calculating q
v = v.reshape(-1)
# state transfer matrix
transfer_matrix = np.array(
[
[0, 1, 2, 0, 0],
[1, 1, 3, 0, 1],
[0, 3, 2, 2, 2],
[1, 3, 3, 2, 3],
]
)
# the state values matrix for calculating q
q_table_v_matrix = transfer_matrix.copy()
for i in range(transfer_matrix.shape[0]):
for j in range(transfer_matrix.shape[1]):
q_table_v_matrix[i, j] = v[transfer_matrix[i, j]]
return [q_table_v_matrix, transfer_matrix]
def value_iteration(q_table, gamma, q_table_v_matrix_methods):
# 第一步,q_table给定状态值
n = q_table.shape[0]
v_new = np.random.rand(n).reshape(-1, 1)
v = np.array([math.inf for i in range(n)]).reshape(-1, 1)
# 迭代
while abs(np.sum(v_new - v)) > 1e-28:
v = v_new
# 获得位置转移矩阵,和q_table计算的v矩阵
q_table_v_matrix, transfer_matrix = q_table_v_matrix_methods(v)
# 第二步,计算q_value
q_value = q_table + gamma * q_table_v_matrix
# 第三步:选择最优策略
pi = np.argmax(q_value, axis=1).reshape(-1, 1)
# 第四步:根据最优策略计算
# 计算 R
R = [q_table[idx, pi[idx]] for idx in range(pi.shape[0])]
# 计算P
P = np.zeros((4, 4))
for idx in range(pi.shape[0]):
P[idx, transfer_matrix[idx, pi[idx]]] = 1
# 第五步:更新 v
v_new = R + (gamma * P).dot(v)
return v_new
value_iteration(q_table, 0.9, q_table_v_matrix_methods)
输出:
array([[ 9.],
[10.],
[10.],
[10.]])
policy iteration
数学原理

算法步骤
- 第一步,给定策略
- 第二步,计算状态值
- 第三步:使用第二节状态值迭代法获得该策略下收敛的状态值
- 第四步:由该状态值更新最优策略
实例及python实现
import math
import numpy as np
q_table_r = np.array(
[
[-1, -1, 0, -1, 0],
[-1, -1, 1, 0, -1],
[0, 1, -1, -1, 0],
[-1, -1, -1, 0, 1],
]
)
# state transfer matrix
q_table_transfer_matrix = np.array(
[
[0, 1, 2, 0, 0],
[1, 1, 3, 0, 1],
[0, 3, 2, 2, 2],
[1, 3, 3, 2, 3],
]
)
def q_table_v_matrix_methods(v, transfer_matrix):
# the state values matrix for calculating q
v = v.reshape(-1)
# the state values matrix for calculating q
q_table_v_matrix = transfer_matrix.copy()
for i in range(transfer_matrix.shape[0]):
for j in range(transfer_matrix.shape[1]):
q_table_v_matrix[i, j] = v[transfer_matrix[i, j]]
return q_table_v_matrix
## 严格按照定义方式
def iterative_solution(R, P, gamma):
# n_iter 为迭代次数
# 初始化 vπ
n = R.shape[0]
v_new = np.random.rand(n, 1).reshape(-1, 1)
v = np.array([math.inf for i in range(n)]).reshape(-1, 1)
while abs(np.sum(v_new - v)) > 1e-8:
v = v_new
v_new = R + (gamma * P).dot(v)
return v_new
def policy_iteration(q_table, transfer_matrix, gamma, q_table_v_matrix_methods):
# 第一步,随机给定策略
action_n = q_table.shape[1]
state_n = q_table.shape[0]
# 给定策略
pi = np.random.randint(low=0, high=action_n, size=state_n)
# 当状态值收敛时停止
v = np.array([0 for i in range(state_n)]).reshape(-1, 1)
v_new = np.array([math.inf for i in range(state_n)]).reshape(-1, 1)
while abs(np.sum(v_new - v)) > 1e-8:
v = v_new
# 第二步,计算状态值
# 计算 R
R = np.array([q_table[idx, pi[idx]] for idx in range(pi.shape[0])])
# 计算P
P = np.zeros((state_n, state_n))
for idx in range(pi.shape[0]):
P[idx, transfer_matrix[idx, pi[idx]]] = 1
# 计算该策略下的状态值
v_new = iterative_solution(R, P, gamma)
## 第三步,由该状态值更新最优策略
# 计算 q_table
q_table_v_matrix = q_table_v_matrix_methods(v_new, transfer_matrix)
# 计算q_value
q_value = q_table + gamma * q_table_v_matrix
# 选择最优策略
pi = np.argmax(q_value, axis=1).reshape(-1, 1)
return pi
policy_iteration(q_table_r, q_table_transfer_matrix, 0.9, q_table_v_matrix_methods)
输出:
array([[2],
[2],
[1],
[4]], dtype=int64)
最优策略与值更新法例子相同。
Truncated policy iteration

Truncated policy iteration 和 policy iteration 一样,只不过以固定的步数,来控制状态值的收敛,读者可以自己尝试修改。
Ref
Mathematical Foundations of Reinforcement Learning,Shiyu Zhao