Spark——Spark SQL逻辑计划(Logical Plan)、物理计划(Physical Plan)和Catalyst优化器(Catalyst Optimizer)
文章目录
- Trees
- Rules
- Spark SQL中使用Catalyst
- Analysis
- 逻辑优化(Logical Optimizations)
- 物理计划(Physical Planning)
- 代码生成(Code Generation)
Spark SQL的核心是Catalyst优化器,它以一种与众不同的方式利用高级编程语言特性来构建可扩展的查询优化器。
Catalyst是一个基于Scala的函数式编程结构设计的可扩展优化器。Catalyst的可扩展设计有两个目的:首先,我们希望能够方便地为Spark SQL添加新的优化技术和特性,特别是为了解决我们在大数据方面看到的各种问题(例如,半结构化数据和高级分析);其次,我们希望外部开发人员能够扩展优化器,例如,通过给不同的数据源添加不同的规则,来将过滤或聚合操作下推到数据源存储系统端,或支持新的数据类型。Catalyst支持基于规则和基于成本的优化。
Catalyst其核心包含一个通用库,用于表示树结构(trees)和作用在树结构上的规则(rules)。我们基于这个框架构建了特定于关系查询处理的库(例如,表达式、逻辑查询计划),以及处理查询执行的不同阶段的几组规则:分析(Analysis)、逻辑优化(Logical Optimizations)、物理计划(Physical Planning)以及将查询部分编译为Java字节码的代码生成技术(Code Generation)。对于代码生成,我们使用了另一个Scala特性:准引用(Quasiquotes),它可以很容易地在运行时从可组合表达式生成代码。最后,Catalyst提供了几个公共扩展点,包括外部数据源和用户自定义类型。
Trees
在Catalyst中,主要的数据类型就是一个由node对象组成的树(tree)。每个node都有一个node类型和零个或多个子node。新的node类型在Scala中被定义为TreeNode类的子类。这些对象是不可变的,可以使用函数进行转换。
举个简单的例子,假设有下面3个node类:
- Literal(value: Int): 表示一个常量
- Attribute(name: String): 表示一个变量
- Add(left: TreeNode, right: TreeNode): 表示两个表达式的和
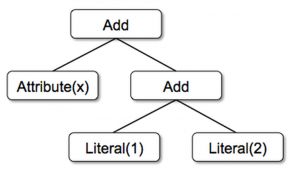
上面这几个类可以被用来构建树(trees)。例如,下面是用Scala代码来表示表达式x+(1+2)的树:
Add(Attribute(x), Add(Literal(1), Literal(2)))
对应的树结构图如下:
Rules
可以使用规则(rules)对树(tree)进行操作,规则就是将树转变另一棵树的函数。虽然规则可以在其输入树上运行任意代码,但最常见的方式是使用一组模式匹配来查找特定结构的子树并将其替换掉。
模式匹配是许多函数式语言的一个特性,它允许从潜在嵌套的数据结构中提取值。在Catalyst中,树提供了一种转换方法,递归地在树的所有节点上应用模式匹配函数,将匹配每个模式的节点转换为结果。例如,我们可以实现一种规则,将两个常量相加的操作进行合并:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
将上面的模式匹配应用到x+(1+2)对应的树上就可以生成新的树x+3,。case关键字是Scala中的标准模式匹配语法,可以用来匹配对象的类型,也可以为提取的值命名。
传递给tree.transform{}的模式匹配表达式是一个不完全的函数,这意味着它只需要匹配所有可能输入树的子集。Catalyst将测试给定规则适用于树的哪些部分,并自动跳过和下降到不匹配的子树中。这种能力意味着规则只需要对匹配的树进行推理优化,而不用管不匹配的哪些树。因此,当向系统添加新的操作类型时,不需修改规则。
规则可以在同一个tree.transform {}中匹配多个模式,使得一次调用可以实现多个匹配:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
}
在实际情况中,规则可能需要执行多次才能完全转换一个树。Catalyst将规则进行分组,并在达到一个固定点(即直到树在应用规则后停止变化)的时候执行每批规则。例如,执行第一批规则是为了给表达式中的变量分配数据类型,执行第二批是用之前的类型对常量进行合并。
最后,规则条件及其主题可以包含任意的Scala代码,这为优化器提供了比领域特定语言更强大的功能,同时保持了对简单规则的简洁性。
Spark SQL中使用Catalyst
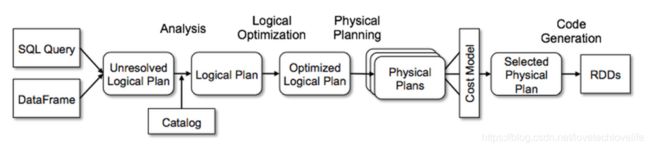
我们将Catalyst的通用树转换框架分为四个阶段:
- 分析逻辑计划以解析引用
- 逻辑计划优化
- 物理计划
- 代码生成,将部分查询编译成Java字节码。
在物理计划阶段,Catalyst可以生成多个计划,并基于代价进行比较,选择最优的那个。而其他阶段都是基于规则的。每个阶段使用不同类型的树节点;Catalyst包括用于表达式、数据类型以及逻辑和物理运行算的节点库。
下图表示了Catalyst中的每个阶段:
Analysis
Spark SQl计算可以从SQL解析器返回的抽象语法树(AST)开始,也可以从使用API构造的DataFrame开始。在这两种情况下,(SQL或代码)都可能包含无法解析的属性引用,例如在SQL中(select col from sales),col字段的类型,或者甚至是sales表中是否存在col字段,都只有到我们去查询sales表之后才能知道。如果我们不知道字段的类型,或不知道表中是否存在这个字段,我们就称这个条SQL语句是unresolved。Spark SQL使用Catalyst规则和一个Catalog对象来跟中所有数据源中的表来解析这些字段,它首先会构建一个未绑定字段和数据类型的“unresolved logical plan”树,然后应用以下规则:
- 从Catalog中查找指定的表
- 从表中查找给定的字段
- 确定哪些字段指定了相同的值,给它们一个唯一id
- 强制类型转换,例如,我们只有在知道col的类型之后才能知道1+col的返回类型
逻辑优化(Logical Optimizations)
逻辑优化阶段对逻辑计划应用标准的基于规则的优化,这些规则包括常量合并、谓词下推、列裁切、布尔表达式简化等。
查看逻辑优化规则代码
物理计划(Physical Planning)
在物理计划阶段,Spark SQL获取一个逻辑计划,并使用与Spark执行引擎匹配的物理操作来生成一个或多个物理计划,然后使用基于代价的模型在这个多个物理计划中选择最优的那个。目前,基于代价的优化仅用于join操作:对于join中较小的表,Spark SQL使用broadcast join来避免shuffle。
物理计划也执行基于规则的物理优化,例如将查询或过滤下推到Spark map端。此外,他还可以将操作从逻辑计划下推到支持谓词下推的数据源端。
代码生成(Code Generation)
查询优化的最后阶段涉及生成在每台机器上运行的字节码。因为Spark SQL要频繁地操作内存中的数据,而数据的处理收CPU的限制,所以我们希望使用代码生成技术来加速执行。然而,代码生成引擎的都贱是非常复杂的,基本上相当于一个编译器。Catalyst依靠Scala语言的一个特殊特性quasiquotes使得代码生成变得更简单。quasiquotes允许我们在Scala语言中以编程的方式构造抽象语法树(AST),然后在运行时将其提供给Scala编译器以生成自耳机吗。我们使用Catalyst将表示SQL表达式的树转换为用于Scala代码的AST,以计算该表达式,然后编译并运行生成的代码。
例如,我们之前提到的Add、Attribute和Literal树节点,它允许我们编写(x+y)+1这样的表达式,如果没有代码生成,就必须通过遍历有Add、Attribute和Literal节点组成的树来为每一行数据解释这样的表达式,这就会引入大量的分支和虚函数调用,从降低执行速度。有了代码生成,我们就可以编一些一个函数,将指定的表达式转换成Scala AST:
def compile(node: Node): AST = node match {
case Literal(value) => q"$value"
case Attribute(name) => q"row.get($name)"
case Add(left, right) => q"${compile(left)} + ${compile(right)}"
}
以q开头的字符串是quasiquotes,尽管它们看起来很行字符串,但它们在编译时由Scala编译器解析,并表示其中代码的AST。quasiquotes可以使用$将变量或者其他AST拼接在一起。
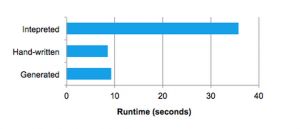
quasiquotes在编译时进行类型检查,以确保只替换适当的AST,这使得它们比字符串连接更有用,并且它们直接生成Scala AST,而不是在运行时运行Scala解析器。此外,它们是高度可组合的,因为每个节点的代码生成规则不需要知道其他子节点返回的树是如何构造的。最后,Scala编译器会进一步优化生成的代码,以防Catalyst遗漏了表达式的优化。下图显示,quasiquotes让我们生成的代码的性能可以媲美手动调优的程序:
注:本篇文章翻译之Databricks Blog中的一篇文章——Deep Dive into Spark SQL’s Catalyst Optimizer。