【AI Agent系列】【MetaGPT】9. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体(2)
文章目录
-
- 0. 前置推荐阅读和本文内容
-
- 0.1 前置推荐阅读
- 0.2 本文内容
- 1. 修改一:直接用大模型获取网页信息,不用爬虫程序
-
- 1.1 我们要给大模型什么内容
- 1.2 提取网页文本信息
- 1.3 组织Action
- 1.4 完整代码及细节注释
- 1.5 可能存在的问题及思考
- 2. 修改二:解耦RunSubscription和SubscriptionRunner
-
- 2.1 思路
- 2.2 首先将 SubscriptionRunner 移出去
- 2.3 打通SubRole和SubAction
- 2.4 触发时间的传递
- 2.5 完整代码及运行结果
0. 前置推荐阅读和本文内容
0.1 前置推荐阅读
-
订阅智能体实战
- 【AI的未来 - AI Agent系列】【MetaGPT】3. 实现一个订阅智能体,订阅消息并打通微信和邮件
- 【AI Agent系列】【MetaGPT】8. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体
-
ActionNode基础与实战
-
【AI的未来 - AI Agent系列】【MetaGPT】4. ActionNode从理论到实战
-
【AI的未来 - AI Agent系列】【MetaGPT】4.1 细说我在ActionNode实战中踩的那些坑
-
0.2 本文内容
在上篇文章 【AI Agent系列】【MetaGPT】8. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体 中我们实现了一个更通用的订阅智能体,本文在此基础上作一些修改优化。
1. 修改一:直接用大模型获取网页信息,不用爬虫程序
在我们之前实现的通用订阅智能体中,从网页中提取信息的方法都是通过爬虫程序来进行的,那可不可以不用爬虫程序,而是直接借助大模型的能力去总结信息?答案是肯定的,不过存在一些其它问题需要我们来解决。下面是实现过程。
1.1 我们要给大模型什么内容
首先考虑下我们需要给大模型什么内容?
- url : 需要大模型自己去访问url(调用插件等)
- html内容
- 网页中的文本内容
最容易想到的大概也就上面三种内容。给url的话还需要我们去让大模型调用相应的插件,有点复杂,本文暂不考虑。对于html内容,前面我们在利用大模型帮助我们写爬虫程序的时候已经见识到了,内容非常多,一是会严重干扰大模型生成爬虫程序的质量,二是非常容易导致token超限,所以直接用这种数据让大模型总结信息也是不合适也不太可能的。

那就剩下给大模型【网页中的文本内容】这一条路子了。联想下大模型对文本的总结能力和使用方法,就是给大模型一段文本,然后让大模型总结,是不是觉得这种方法非常可行?下面来看具体做法。
1.2 提取网页文本信息
(1)原来的代码分析
class SubAction(Action):
...... 省略 ......
async def run(self, *args, **kwargs):
pages = await WebBrowserEngine().run(*urls)
通过WebBrowserEngine获取到了网页内容。打印出来看一下,大概长下图这样,这些内容都在返回结果pages.inner_text中。

(2)提取出纯文本信息。
对 pages.inner_text 进行处理,去掉里面的一些特殊符号。可以用下面的代码。
def get_linktext(html_content):
flag = False
if len(html_content) > 0:
html_content = html2text.html2text(html_content)
html_content = html_content.strip()
if len(html_content) > 0:
flag = True
return flag, html_content
html2text是一个 Python 库,用于将 HTML 格式的文本转换为纯文本格式。它特别适用于从网页抓取数据,并将这些数据从复杂的 HTML 格式转换为简单的纯文本格式。
来看下提取之后的效果:

(3)将提取到的文本和用户需求一起给大模型,让大模型总结内容
1.3 组织Action
好了,主要的修改我们已经做完了。下面就是将修改融入到我们之前的代码中。
来看一下我们现在有的元素:
-
[Role] SubscriptionAssistant
- [Action] ParseSubRequirement : 解析用户需求
- [Action] RunSubscription :创建并开启订阅智能体
-
[Role] SubRole : 订阅智能体
- [Action] SubAction
就让SubscriptionAssistant的Action顺序执行就可以了。
class SubscriptionAssistant(Role):
"""Analyze user subscription requirements."""
name: str = "同学小张的订阅助手"
profile: str = "Subscription Assistant"
goal: str = "analyze user subscription requirements to provide personalized subscription services."
constraints: str = "utilize the same language as the User Requirement"
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
self._init_actions([ParseSubRequirement, RunSubscription]) ## 2. 先解析用户需求,然后运行订阅
self._set_react_mode(react_mode="by_order") ## 按顺序执行
1.4 完整代码及细节注释
from metagpt.actions.action_node import ActionNode
from metagpt.actions.action import Action
import asyncio
from uuid import uuid4
import sys
import aiohttp
## 分析用户的要求语言
LANGUAGE = ActionNode(
key="language",
expected_type=str,
instruction="Provide the language used in the project, typically matching the user's requirement language.",
example="en_us",
)
## 分析用户的订阅推送时间
CRON_EXPRESSION = ActionNode(
key="Cron Expression",
expected_type=str,
instruction="If the user requires scheduled triggering, please provide the corresponding 5-field cron expression. "
"Otherwise, leave it blank.",
example="",
)
## 分析用户订阅的网址URL,可以是列表
CRAWLER_URL_LIST = ActionNode(
key="Crawler URL List",
expected_type=list[str],
instruction="List the URLs user want to crawl. Leave it blank if not provided in the User Requirement.",
example=["https://example1.com", "https://example2.com"],
)
## 分析用户所需要的网站数据
PAGE_CONTENT_EXTRACTION = ActionNode(
key="Page Content Extraction",
expected_type=str,
instruction="Specify the requirements and tips to extract from the crawled web pages based on User Requirement.",
example="Retrieve the titles and content of articles published today.",
)
## 分析用户所需要的汇总数据的方式
CRAWL_POST_PROCESSING = ActionNode(
key="Crawl Post Processing",
expected_type=str,
instruction="Specify the processing to be applied to the crawled content, such as summarizing today's news.",
example="Generate a summary of today's news articles.",
)
## 补充说明,如果url或定时器解析为空,则提示用户补充
INFORMATION_SUPPLEMENT = ActionNode(
key="Information Supplement",
expected_type=str,
instruction="If unable to obtain the Cron Expression, prompt the user to provide the time to receive subscription "
"messages. If unable to obtain the URL List Crawler, prompt the user to provide the URLs they want to crawl. Keep it "
"blank if everything is clear",
example="",
)
NODES = [
LANGUAGE,
CRON_EXPRESSION,
CRAWLER_URL_LIST,
PAGE_CONTENT_EXTRACTION,
CRAWL_POST_PROCESSING,
INFORMATION_SUPPLEMENT,
]
PARSE_SUB_REQUIREMENTS_NODE = ActionNode.from_children("ParseSubscriptionReq", NODES)
## 解析用户的需求的Action
PARSE_SUB_REQUIREMENT_TEMPLATE = """
### User Requirement
{requirements}
"""
SUB_ACTION_TEMPLATE = """
## Requirements
Answer the question based on the provided context {process}. If the question cannot be answered, please summarize the context.
## context
{data}"
"""
class ParseSubRequirement(Action):
async def run(self, requirements):
requirements = "\n".join(i.content for i in requirements)
context = PARSE_SUB_REQUIREMENT_TEMPLATE.format(requirements=requirements)
node = await PARSE_SUB_REQUIREMENTS_NODE.fill(context=context, llm=self.llm)
return node ## 3. 返回解析后的用户需求
# if __name__ == "__main__":
# from metagpt.schema import Message
# asyncio.run(ParseSubRequirement().run([Message(
# "从36kr创投平台https://pitchhub.36kr.com/financing-flash 爬取所有初创企业融资的信息,获取标题,链接, 时间,总结今天的融资新闻,然后在晚上七点半送给我"
# )]))
from metagpt.schema import Message
from metagpt.tools.web_browser_engine import WebBrowserEngine
import html2text
from pytz import BaseTzInfo
from typing import Optional
from aiocron import crontab
import os
class CronTrigger:
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None) -> None:
self.crontab = crontab(spec, tz=tz)
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next()
return Message()
class WxPusherClient:
def __init__(self, token: Optional[str] = None, base_url: str = "http://wxpusher.zjiecode.com"):
self.base_url = base_url
self.token = token or os.environ["WXPUSHER_TOKEN"] # 5.1 从环境变量中获取token,所以你需要在环境变量中配置WXPUSHER_TOKEN或在配置文件中设置WXPUSHER_TOKEN
async def send_message(
self,
content,
summary: Optional[str] = None,
content_type: int = 1,
topic_ids: Optional[list[int]] = None,
uids: Optional[list[int]] = None,
verify: bool = False,
url: Optional[str] = None,
):
payload = {
"appToken": self.token,
"content": content,
"summary": summary,
"contentType": content_type,
"topicIds": topic_ids or [],
# 5.2 从环境变量中获取uids,所以你需要在环境变量中配置WXPUSHER_UIDS
# uids是你想推送给哪个微信,必须是关注了你这个订阅号的微信才可以知道uid
"uids": uids or os.environ["WXPUSHER_UIDS"].split(","),
"verifyPay": verify,
"url": url,
}
url = f"{self.base_url}/api/send/message"
return await self._request("POST", url, json=payload)
async def _request(self, method, url, **kwargs):
async with aiohttp.ClientSession() as session:
async with session.request(method, url, **kwargs) as response:
response.raise_for_status()
return await response.json()
# 5.3 微信callback wrapper,使用WxPusherClient给指定微信推送消息
async def wxpusher_callback(msg: Message):
client = WxPusherClient()
await client.send_message(msg.content, content_type=3)
# 运行订阅智能体的Action
class RunSubscription(Action):
async def run(self, msgs):
from metagpt.roles.role import Role
from metagpt.subscription import SubscriptionRunner
req = msgs[-1].instruct_content.dict() ## 获取用户需求,注意这里msgs[-1],不是[-2]了,没有code了
urls = req["Crawler URL List"]
process = req["Crawl Post Processing"]
spec = req["Cron Expression"]
SubAction = self.create_sub_action_cls(urls, process) ## 创建一个Action,urls网页链接、process用户需求的数据
SubRole = type("SubRole", (Role,), {}) ## 定时触发的Role
role = SubRole()
role.init_actions([SubAction])
runner = SubscriptionRunner()
callbacks = []
callbacks.append(wxpusher_callback)
async def callback(msg):
print(msg)
await asyncio.gather(*(call(msg) for call in callbacks)) # 遍历所有回调函数,触发回调,分发消息
await runner.subscribe(role, CronTrigger(spec), callback)
await runner.run()
@staticmethod
def create_sub_action_cls(urls: list[str], process: str):
class SubAction(Action):
@staticmethod
def get_linktext(html_content): ## 提取出网页中的纯文本信息
flag = False
if len(html_content) > 0:
html_content = html2text.html2text(html_content)
html_content = html_content.strip()
if len(html_content) > 0:
flag = True
return flag, html_content
async def run(self, *args, **kwargs):
pages = await WebBrowserEngine().run(*urls)
flag, page_content = self.get_linktext(pages.inner_text) ## 这块可能有点bug,没有考虑多个url的情况
return await self.llm.aask(SUB_ACTION_TEMPLATE.format(process=process, data=page_content))
return SubAction
# 定义订阅助手角色
from metagpt.roles import Role
from metagpt.actions import UserRequirement
from metagpt.utils.common import any_to_str
class SubscriptionAssistant(Role):
"""Analyze user subscription requirements."""
name: str = "同学小张的订阅助手"
profile: str = "Subscription Assistant"
goal: str = "analyze user subscription requirements to provide personalized subscription services."
constraints: str = "utilize the same language as the User Requirement"
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
self._init_actions([ParseSubRequirement, RunSubscription]) ## 2. 先解析用户需求,然后运行订阅
self._set_react_mode(react_mode="by_order") ## 按顺序执行
if __name__ == "__main__":
import asyncio
from metagpt.team import Team
team = Team()
team.hire([SubscriptionAssistant()]) ## 从SubscriptionAssistant开始run,这里只有一个角色,其实都不用再使用Team了
team.run_project("从36kr创投平台https://pitchhub.36kr.com/financing-flash爬取所有初创企业融资的信息,获取标题,链接, 时间,总结今天的融资新闻,然后在10:49送给我")
asyncio.run(team.run())
- 运行结果

1.5 可能存在的问题及思考
(1)网页中文本内容仍然可能有token超限的可能
- 思考:如果文本太多,可以考虑文本分块给大模型分别总结,然后最后再组合等方式。
(2)Prompt的好坏直接影响最终总结的结果的好坏
2. 修改二:解耦RunSubscription和SubscriptionRunner
目前,订阅智能体是通过RunSubscription运行的,即RunSubscription这个action,不仅创建了订阅智能体代码,并启动了SubscriptionRunner,这会让我们的RunSubscription一直无法退出,请尝试将二者分离,即从RunSubscription分离出AddSubscriptionTask的action,并且让SubscriptionRunner单独运行
2.1 思路
先看下RunSubscription中都做了什么:
create_sub_action_cls创建了SubAction- 创建了
SubRole,并添加了SubAction作为自身的Action - 创建了
SubscriptionRunner,依赖SubRole,并运行run - 添加了
callback
要将 RunSubscription 和 SubscriptionRunner分离,需要将 SubscriptionRunner 移出去,而它依赖 SubRole,SubRole又依赖SubAction。
一种思路:我们可以让 RunSubscription 只创建SubAction,只要想办法将SubAction传给SubRole,就打通了流程。简单画了个图:
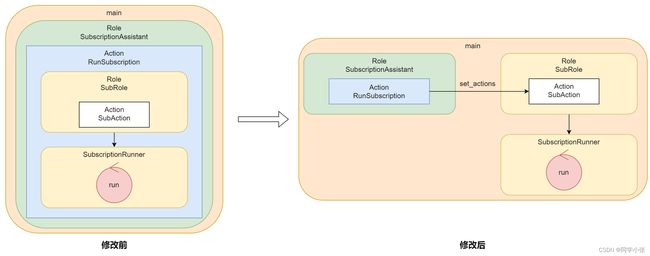
2.2 首先将 SubscriptionRunner 移出去
我放到了main函数里。其依赖的SubRole和callback,也一并在这里创建了。
if __name__ == "__main__":
...... 省略 ......
role = SubRole()
runner = SubscriptionRunner()
callbacks = []
callbacks.append(wxpusher_callback)
async def callback(msg):
print(msg)
await asyncio.gather(*(call(msg) for call in callbacks)) # 遍历所有回调函数,触发回调,分发消息
async def mainloop():
await runner.subscribe(role, CronTrigger(role.triggle_time), callback)
await runner.run()
asyncio.run(mainloop())
2.3 打通SubRole和SubAction
SubscriptionRunner已经独立run了,下面就是将SubAction加到SubRole里去执行。
这里我将SubRole作为一个参数传递到RunSubscription里,在RunSubscription创建完SubAction之后,通过一个set接口塞给SubRole。
class SubRole(Role):
triggle_time : str = None ## 触发时间
def __init__(self, **kwargs) -> None:
super().__init__(**kwargs)
def set_actions(self, actions:list): ## 开放一个set接口,接收设置action
self._init_actions(actions) ## 在这里给role设置actions
class RunSubscription(Action):
subrole : SubRole = None ## 这里接收外部的SubRole实例,用来后面添加actions
def __init__(self, subrole: SubRole) -> None:
super().__init__()
self.subrole = subrole
async def run(self, msgs) -> Action:
...... 省略 ......
subAction = self.create_sub_action_cls(urls, code, process) ## 创建一个Action,urls网页链接、code爬虫代码、process用户需求的数据
self.subrole.set_actions([subAction]) ## 给SubRole设置一个Action,打通SubRole和SubAction
self.subrole.triggle_time = spec ## 给SubRole设置一个触发时间
print("Subscription started end.")
return spec ## 这里需要返回一个字符串,任意的都行,但不能没有返回
class SubscriptionAssistant(Role):
...... 省略 ......
def __init__(self, subrole:SubRole, **kwargs) -> None: ## 这里接收外部的SubRole实例
super().__init__(**kwargs)
self._init_actions([ParseSubRequirement, RunSubscription(subrole)]) ## 将接收的外部SubRole实例传给 RunSubscription
if __name__ == "__main__":
role = SubRole()
## team.hire([SubscriptionAssistant, CrawlerEngineer()]) ## 1. 从SubscriptionAssistant开始run
team.hire([SubscriptionAssistant(role), CrawlerEngineer()]) ## 将SubRole实例传递进取
这样在 RunSubscription 创建了SubAction之后,我们的订阅智能体SubRole就有这个SubAction可以执行了。
2.4 触发时间的传递
可能你也发现了,将SubscriptionRunner移出来后,await runner.subscribe(role, CronTrigger(spec), callback)代码中的定时器的spec参数就无法获取到了。所以我也像SubAction传递一样,在SubRole中加了个参数:triggle_time : str = None ## 触发时间,用来记录触发时间。在使用时,直接用role.triggle_time即可。
await runner.subscribe(role, CronTrigger(role.triggle_time), callback)
2.5 完整代码及运行结果
代码修改就以上这么点,比较简单,就不再贴完整代码了。有需要的可以+v jasper_8017要源码,一起交流。
- 运行结果

最终订阅的信息并没有想象中的好,只是个demo,要想做成产品,还有很长路要走。