高级RAG(七): 评估句子-窗口检索

在上一篇博客中我们介绍了LlamaIndex的句子窗口检索,它的主要思想是将文档按句子来切割,每个句子会被切割成一个文档,同时将每条句子周围的若干条句子作为“窗口”数据保存在文档的元数据中。当用户发起检索时会将问题与每个句子文档向量进行匹配,当匹配到相似度最高的文档后,将该文档的“窗口”数据以及问题一起发送给LLM, 最后由LLM来生成最终的回复, 如下图所示:
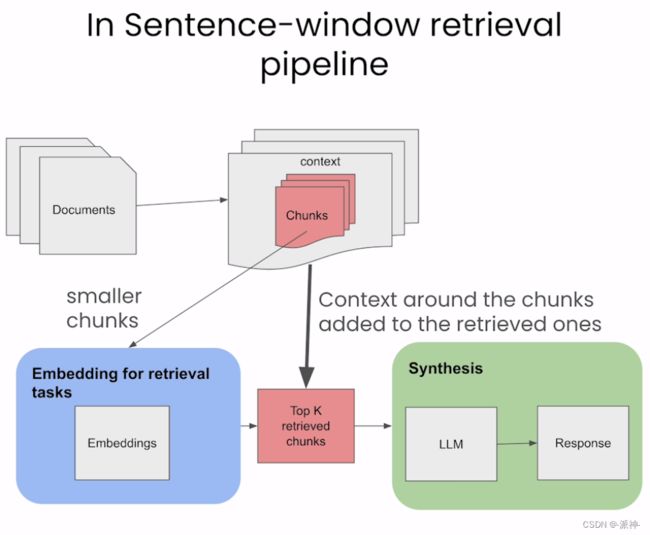
那么句子窗口检索的效果怎么样,如何来设置一个合适窗口的尺寸(sentence_window_size)以达到最佳的检索效果呢?下面我们来介绍如何使用TruLens来评估句子窗口检索的效果,如果对TruLens还不熟悉的朋友可以先看一下我之前写的TruLens 评估-扩大和加速LLM应用程序评估这篇博客。
一、环境配置
我们首先需要安装如下python包:
pip install llama_index trulens-eval trafilatura torch sentence-transformers接下来我们需要做一些初始化的工作,比如导入openai或者gemini等大模型的api_key:
import os
os.environ['OPENAI_API_KEY']="your_api_key"下面我们需要导入在后续实验中所需要使用到的所有python包:
import os
from llama_index.llms import OpenAI
from llama_index import ServiceContext, VectorStoreIndex, StorageContext
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index import load_index_from_storage
from llama_index.readers.web import TrafilaturaWebReader
from llama_index import Document
from trulens_eval import Tru
from trulens_eval import Feedback,TruLlama
from trulens_eval import OpenAI as fOpenAI
from trulens_eval.feedback import Groundedness
import numpy as np
import nest_asyncio
import pandas as pd
pd.set_option("display.max_colwidth", None)二、加载数据
这里我们仍然使用前几篇博客中使用的数据即从百度百科的网页中抓取一篇关于恐龙的文章:
url="https://baike.baidu.com/item/恐龙/139019"
docs = TrafilaturaWebReader().load_data([url])
#将全角标点符号转换成半角标点符号+空格
for d in docs:
d.text=d.text.replace('。','. ')
d.text=d.text.replace('!','! ')
d.text=d.text.replace('?','? ')
docs
这里我们使用的是LlamaIndex提供的网页爬虫工具TrafilaturaWebReader来爬取百度百科上的这篇文章,然后我们会将文章中全角标点符号如句号、感叹号、问号全部转换成半角标点符号+空格,至于为什么要将全角的标点符号替换成半角标点符号,我在句子-窗口检索这篇博客中已经说明过了,不清楚的朋友可以看一下这篇博客。
三、创建向量数据库和查询引擎
接下来我们需要定义两个主要的函数,它们分别用来创建向量数据库和查询引擎,这里我们还会使用bge的embedding模型和rerank模型,对这些还不熟悉的朋友可以看看我之前的博客:
#定义创建向量数据库函数
def build_sentence_window_index(
documents,
llm,
embed_model="local:BAAI/bge-small-zh-v1.5",
sentence_window_size=3,
save_dir="sentence_index",
):
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=sentence_window_size,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
)
if not os.path.exists(save_dir):
sentence_index = VectorStoreIndex.from_documents(
documents, service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir=save_dir)
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=sentence_context,
)
return sentence_index
#定义查询引擎函数
def get_sentence_window_query_engine(
sentence_index, similarity_top_k=6, rerank_top_n=2
):
# define postprocessors
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return sentence_window_engine
#创建向量数据库
index = build_sentence_window_index(
docs,
llm=OpenAI(model="gpt-3.5-turbo",temperature=0.1),
save_dir="./sentence_index",
)
#创业查询引擎
query_engine = get_sentence_window_query_engine(index, similarity_top_k=6)这里需要说明一下的是,我们在创建查询引擎时设置了similarity_top_k=6,它的意思是每次检索的时候会返回6个相关文档,但是由于我们使用了rerank模型并且设置了rerank_top_n=2,所以这6个相关文档经过rerank模型的重新排序以后最后只会保留2个最相关的文档。
四、TruLens 评估
接下来我们要开始对句子窗口检索的效果进行评估,那么评估的一般过程是这样的:
- 句子窗口参数(sentence_window_size)从1开始逐渐增加。
- 用RAG 三元组评估应用版本
- 跟踪实验以选择最佳句子窗口大小(sentence_window_size)
- 注意tonken使用成本和上下文相关性(context Relevance)之间的权衡
- 注意窗口大小和基础性(groundedness)之间的权衡
- 注意上下文相关性(context Relevance)和基础性(groundedness)之间的关系
这里我们需要说明的是我们从sentence_window_size=1开始实验,然后组件增加sentence_window_size,我们每次都会评估RAG 三元组即Context Relevance,Groundedness和Answer Relevance的分数,在此基础上我们希望找到一个最佳的sentence_window_size值,同时我们还要考虑tonken使用成本和上下文相关性(context Relevance)之间平衡,当窗口的尺寸越大,上下文相关性越高这就意味着所需要的上下文信息也越多那么token的成本也会相应的增加。另外我们期望的是,当我们不断增加窗口尺寸时,上下文相关性会增加到一定程度,基础性(groundedness)也会增加,然后超过这个点,我们会看到上下文相关性要么变平缓要么减少,基础性也可能遵循类似的模式。此外,我们也肯能在实践中看到上下文相关性和基础性(groundedness)之间非常有趣的关系。当上下文相关性较低时,基础性(groundedness)也往往较低。这是因为llm通常会试图通过利用预训练阶段的知识来填补检索到的上下文片段中的空白,这就是所谓的“幻觉”产生的答案。
下面我们首先创建一组问题,然后使用句子窗口检索方法进行检索最后LLM给出这些问题的答案,然后将这组问题和答案交给TruLens进行评估,然后TruLens会给出每个问题的Context Relevance,Groundedness和Answer Relevance三个评估指标的分数,如果对这些评估指标还不熟悉的朋友可以查看一下我之前写的TruLens 评估-扩大和加速LLM应用程序评估这篇博客,这里需要说明一下的是,TruLens在评估时,其内部仍然是通过LLM来对question,context, answer进行评估的,也就是说整个评估过程LLM也都是全程参与的,那么说的通俗一点就是LLM在检索和评估的过程中即当球员又当裁判!
#定义问题
eval_questions = [
"恐龙分哪几类?",
"体型最大的是哪种恐龙?",
"恐龙是怎么繁殖的?",
"恐龙是冷血动物吗?",
"恐龙为什么会灭绝? 什么时候灭绝的?",
]这里为了演示,我们只创建了5个问题,那么在实际的应用中我们可能需要创建10-20组问题,接下来我们需要定义一个评估记录器,它会创建三个评估指标qa_relevance、qs_relevance、groundedness对这些还不熟悉的朋友可以看一下我的上一篇博客:TruLens 评估-扩大和加速LLM应用程序评估
#设置线程的并发执行
nest_asyncio.apply()
#创建评估器对象
tru = Tru()
#定义评估记录器
def get_prebuilt_trulens_recorder(query_engine, app_id):
openai = fOpenAI()
qa_relevance = (
Feedback(openai.relevance_with_cot_reasons, name="Answer Relevance")
.on_input_output()
)
qs_relevance = (
Feedback(openai.relevance_with_cot_reasons, name = "Context Relevance")
.on_input()
.on(TruLlama.select_source_nodes().node.text)
.aggregate(np.mean)
)
grounded = Groundedness(groundedness_provider=openai)
groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons, name="Groundedness")
.on(TruLlama.select_source_nodes().node.text)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
feedbacks = [qa_relevance, qs_relevance, groundedness]
tru_recorder = TruLlama(
query_engine,
app_id=app_id,
feedbacks=feedbacks
)
return tru_recorder
#执行评估
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
with tru_recorder as recording:
response = query_engine.query(question)
#初始化评估数据库
Tru().reset_database() 4.1 Sentence window size = 1
下面看我们来执行评估程序,这里我们首先设置的时Sentence window size = 1,当执行完评估程序以后,TruLens会开启一个基于streamlit的web应用程序, 下面我们可以在这个web应用程序中查看评估结果:
sentence_index_1 = build_sentence_window_index(
docs,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
sentence_window_size=1,
save_dir="sentence_index_1",
)
sentence_window_engine_1 = get_sentence_window_query_engine(
sentence_index_1
)
tru_recorder_1 = get_prebuilt_trulens_recorder(
sentence_window_engine_1,
app_id='sentence window engine 1'
)
run_evals(eval_questions, tru_recorder_1, sentence_window_engine_1)
Tru().run_dashboard()
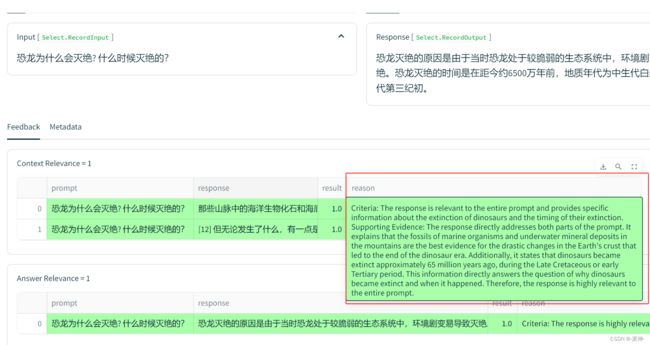
这里我们看到了这5个问题的总成绩(红框中),下面我们还可以看到明细的记录:

当我们点选其中任意一条明细的记录,我们还可以看到它给出的评分理由:
4.2 Sentence window size = 3
接下来我们将Sentence window size = 3,看看评估结果会怎么样:
sentence_index_3 = build_sentence_window_index(
docs,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-zh-v1.5",
sentence_window_size=3,
save_dir="sentence_index_3",
)
sentence_window_engine_3 = get_sentence_window_query_engine(
sentence_index_3
)
tru_recorder_3 = get_prebuilt_trulens_recorder(
sentence_window_engine_3,
app_id='sentence window engine 3'
)
run_evals(eval_questions, tru_recorder_3, sentence_window_engine_3)
tru.run_dashboard()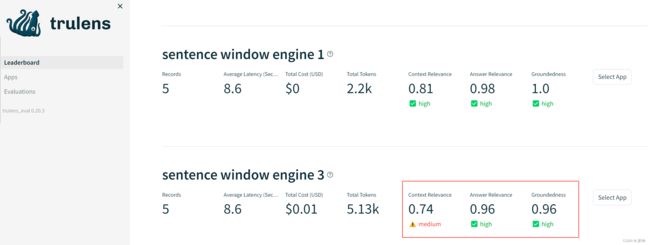
这里当我看到当我们设置Sentence window size = 3时,RAG三元组指标都有所下降,下面我们看一下明细数据:

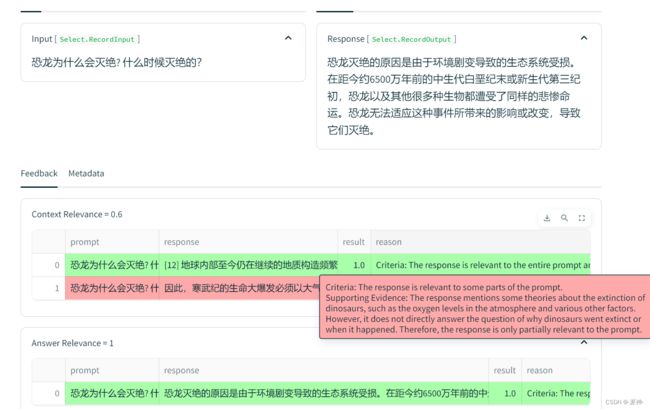
经过这两轮的评估,在本次实验中 Sentence window size =1 似乎是个较为理想的值,因为它的各项指标均好于Sentence window size =3。
五、总结
今天我们详细介绍了如何使用trulens对LlamaIndex的句子窗口检索结果进行评估,基于成本的考虑我们只进行了两轮评估,从评估的结果上看 Sentence window size =1 似乎是个较为理想的值,因为它的各项指标均由于Sentence window size =3,希望今天的内容对大家学习RAG有所帮助。