深度学习与神经网络pytorch版 基础知识
深度学习与神经网络pytorch版 基础知识
1.简单介绍
PyTorch是一个开源的深度学习框架,由Facebook于2016年发布的第一个开源项目。与TensorFlow等其他深度学习框架相比,PyTorch更加灵活和易于使用,尤其适合快速原型设计和实验。
以下是PyTorch的一些主要特点:
1.动态计算图:PyTorch使用动态计算图,这意味着您可以在运行时构建和更改计算图。这使得模型开发和调试更加直观和灵活。
2.易于使用的API:PyTorch的API设计得非常直观,使得开发者可以轻松地构建和训练神经网络。此外,PyTorch的文档和社区支持也非常出色。
3.GPU加速:PyTorch支持GPU加速,可以大大提高模型的训练速度。4.PyTorch还提供了与NVIDIA CUDA深度集成,使得使用GPU更加容易。
4.广泛的应用:PyTorch已经被广泛应用于计算机视觉、自然语言处理、强化学习等多个领域。许多研究者和开发者都选择PyTorch作为他们的首选深度学习框架。
使用PyTorch进行深度学习的基本步骤通常包括:
1.数据准备:加载和预处理数据,以便用于模型训练。
2.模型定义:使用PyTorch的API定义神经网络的架构。
3.损失函数和优化器:定义损失函数和优化器,以便在训练过程中更新模型参数。
4.训练过程:迭代训练数据集,并在每个迭代中使用优化器更新模型参数。
5.评估模型:使用测试数据集评估模型的性能。
PyTorch是一个功能强大的深度学习框架,适合各种深度学习任务。它的灵活性和易用性使得它成为许多研究者和开发者的首选。下面我将介绍一些关于Pytorch入门的必备知识,为以后的学习打下基础:
2.1 数据操作
2.1.1 入门
# 2.1 数据操作
# 2.1.1 入门
import torch
# 使用arrange创建一个行向量 x
x1 = torch.arange(12)
print(x1)
# tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 使用张量的shape属性来访问张量(沿着每个轴的长度)的形状。
print(x1.shape)
# 查看张量中元素的总数
print(x1.numel())
# 改变一个张量的形状而不改变元素数量和元素值
X = x1.reshape(3,4) # 形状改为三行四列的矩阵
Y = x1.reshape(-1,4) # 使用-1自动计算张量的形状,或者x.reshape(3,-1)
print(X)
# 使用全0,全1或者其他随机张量
print(torch.zeros((2,3,4))) # 生成两个三行四列的全零张量矩阵
print(torch.ones((2,3,4))) # 生成两个三行四列的全一张量矩阵
print(torch.randn(2,3,4)) # 生成两个三行四列的矩阵,元素均值为0,标准差为1
# 为每个张量元素赋予指定值
print(torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]]))


2.1.2 运算符
import torch
# 2.1.2 运算符
# 常见的标准运算符("+","-","*","/","**")
x2 = torch.tensor([1.0,2,4,8])
y2 = torch.tensor([2,2,2,2])
print(x2+y2,x2-y2,x2/y2,x2**y2)
# 求幂运算
print(torch.exp(x2))
# 将张量连结在一起
X1 = torch.arange(12,dtype=torch.float32).reshape((3,4))
Y1 = torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
print(torch.cat((X1,Y1),dim=0))
print(torch.cat((X1,Y1),dim=1))
#
# 判断两个张量中元素是否相等,相等True,不相等False
print(X1 == Y1)
#
# 对张量中所有元素进行求和,产生一个单元素张量
print(X1.sum())
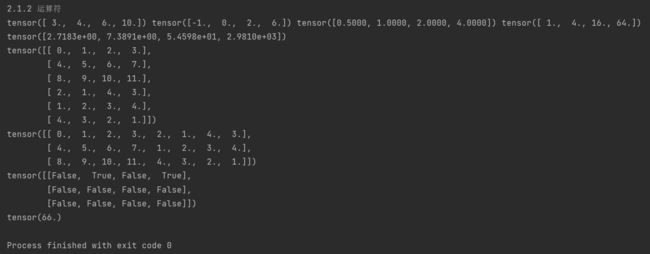
2.1.3 广播机制
# 2.1.3 广播机制
a = torch.arange(3).reshape((3,1))
b = torch.arange(2).reshape((1,2))
print(a,'\n',b)
# 由于a和b分别是3✖1和1✖2的矩阵,如果让它们相加,它们的形状不匹配。
# 我们将两个矩阵广播为一个更大的3✖2矩阵,
# 如下所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加
print(a + b)

2.1.4 索引和切片
# 2.1.4 索引和切片
import torch
X2 = torch.arange(12,dtype=torch.float32).reshape((3,4))
print(X2[-1]) # 使用[-1]选择最后一个元素
print(X2[1:3]) # 使用[1:3]选择第二个和第三个元素
#
X2[1,2] = 9 # 指定索引来将元素写入矩阵
print(X2)
#
X2[0:2,:] = 12 # 索引所有元素,将他们赋值
print(X2)
#

2.1.5 节省内存
# 2.1.5 节省内存
import torch
X1 = torch.arange(12,dtype=torch.float32).reshape((3,4))
Y1 = torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
before = id(Y1)
Y1 = Y1 + X1
print(id(1) == before)
#
Z = torch.zeros_like(Y1)
print('id(Z):', id(Z))
Z[:] = X1 + Y1
print('id(Z):', id(Z))
#
before = id(X1)
X1 += Y1
print(id(X1) == before)

2.1.6 转换为其他Python对象
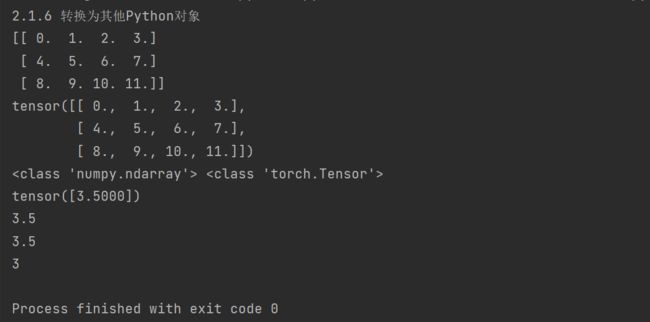
# 2.1.6 转换为其他Python对象
import torch
x = torch.arange(12,dtype=torch.float32).reshape((3,4))
a = x.numpy()
b = torch.tensor(a)
print(a)
print(b)
print(type(a),type(b))
a = torch.tensor([3.5])
print(a)
print(a.item()) # 调用item函数将张量转换为python中的标量
print(float(a))
print(int(a))
小结
深度学习存储和操作数据的主要接口是张量(维数组)。它提供了各种功能,包括基本数学运算、广播、索引、切片、内存节省和转换其他Python对象。
我正在学习深度学习神经网络Pytorch版,分享我的一些学习,希望大家可以给我一些建议,谢谢大家。评论,私信都可以,我以后也会不断的更新我的学习进度,谢谢大家。