关于dc综合问题
说明:本文内容存在作者在工作中的认识和思考,请谨慎参考,如有问题希望批评指正!
1. dc综合避免latch的产生
Latch 的主要危害有:
1)输入状态可能多次变化,容易产生毛刺,增加了下一级电路的不确定性;
2)在大部分 FPGA 的资源中,可能需要比触发器更多的资源去实现 Latch 结构;
3)锁存器的出现使得静态时序分析变得更加复杂。
Latch 多用于门控时钟(clock gating)的控制,设计时一般应当避免 Latch 的产生。
为避免 Latch 的产生,在组合逻辑中,需要注意以下几点:
1)if-else 或 case 语句,结构一定要完整;
2)不要将赋值信号放在赋值源头,或条件判断中;
3)敏感信号列表建议多用 always@(*)。
2. 算数运算的结构优化以及pipeline的优化
算数运算在较长运算情况下,通过加括号的方式进行结构优化,注意dc综合是否对此优化有效,也可对于组合逻辑进行流水线设计,通过打散组合逻辑层,插入寄存器分段组合逻辑的时序检查,但整体上来看,比加括号的方式时序更慢。但是这两种都是串行变并行结构,总体上都提高了速率,流水线结构同时也加大了面积。
3. 设计划分
把一个复杂的设计分割成几个相对简单的部分,称为设计划分(Design Partition)。这种方法, 也可以称为“分而治之” (Divide and conquer)的方法,在平常的电路设计中这是一种普遍使用的方法, 一般我们在编写 HDL 代码之前都需要对所要描述的系统作一个系统划分,根据功能或者其他的原则将一个系统层次化的分成若干个子模块, 这些子模块下面再进一步细分。 这是一种设计划分, 模块(module)就是一个划分的单位。
划分原则:
原则一:不要让组合逻辑穿越过多模块。

在这张图里, 组合逻辑被划到了 C 模块中, 它不仅能保证组合的最佳优化还能保证时序的最佳优化, 因为里面的寄存器在优化的过程中可以吸收前面的组合逻辑, 从而形成其他形式的时序元件, 如由原先的 D 触发器变成 JK 触发器、 T 触发器、 带时钟使能端的触发器等等。这样工艺库中的大量的时序单元都可以得到充分的利用了。
原则二:寄存模块的输出

在编写代码或者综合的过程中, 我们可以把模块尽量写成分层的组合逻辑, 将所有的输出寄存起来。 其实这样不但是最佳的优化结构,也可以简化时序约束(使得所有模块的输入延时相等)。但需要注意:
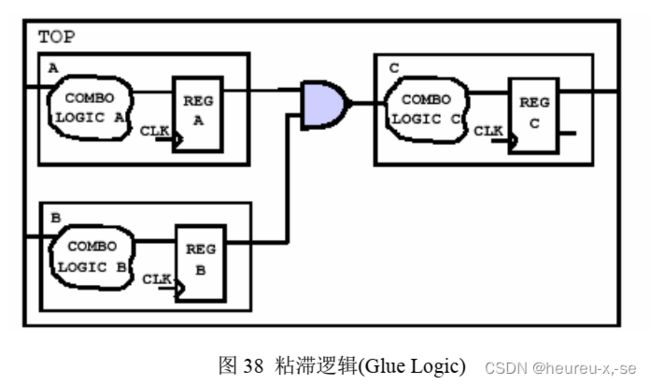
图中可以看到, 一个与非门连接了 A、 B、 C 三个模块, 同样的不难看出来,它也会影响到 C 的组合逻辑的优化。 一般这种情况只会在至下而上的综合策略中才出现。可以通过把与非门吸收到 C 中的组合逻辑的方法消除粘滞逻辑(如下图), 从而使得电路的顶层模块仅仅是将子模块拼接在一起, 而没有独立的电路结构, 这样的一个另一个好处是可以使得在至下而上的设计策略中不需要编译顶层模块。
原则三 根据综合时间长短控制模块大小
原则四 将同步逻辑部分与其他部分分离
上面我们介绍了四个划分的原则, 当然这些原则并不是我们在编写 HDL 代码的时候就必须遵守的, 它只是说明什么样的设计划分对于 DC 来说是最理想的, 能得到最优化的结果。事实上除了通过 HDL 中的模块体现划分,我们还可以运用 DC 的两个命令( Group 及Ungroup)来调整设计划分。
4. 时序运算
1)set_input_delay -max 4 -clock CLK [get_ports A]
我们指定外部逻辑用了多少时间,DC计算还有多少时间留给内部逻辑(输入端口到寄存器的延时)。在这条命令中,外部逻辑用了4 ns,对于时钟周期为10 ns的电路,内部逻辑的最大延迟为10 - 4 - Tsetup = 6 。
2)我们可以通过建立时间预算(Time Budget),为输入/输出端口设置时序的约束,也就是先预置这些延时,大家先商量好(或者设计规格书声明好)。但是预置多少才合适呢?就有下面的基本原则了:
DC要求我们对所有的时间路径作约束,而不应该在综合时还留有未加约束的路径。我们可以假设输人和输出的内部电路仅仅用了时钟周期的40%。如果设计中所有的模块都按这种假定设置对输人/输出进行约束,将还有20%时钟周期的时间作为富余量( Margin),富余量中包括寄存器FF1的延迟和FF2的建立时间,即:富余量=20%时钟周期 - Tclk-q - Tsetup。
input delay/output delay
一般是时钟的60%-70%约束,实际无法估计这个约束,这个约束与外部的传输延时,pcb延时,模拟到数字的延时有关,较为复杂。
5. 时序分析
静态时序分析(STA)是进行电路时序分析的一种方法,它的主要特点是分析不需要通过动态仿真, 并且对电路的覆盖率更高。 动态仿真(比如 VCS)需要给电路施加一个激励, 并检查输出信号,与理想信号比较, 这种办法速度较慢,而且不一定能覆盖到所有的逻辑。
静态时序分析的分为三个步骤——
- 将电路分解成不同的时序路径(timing paths)
- 计算每段路径的延时
- 检查所有路径的延时,看是否能满足时序要求
进行寄存器之间的时序检查,例如做建立时间检查,检查最大延时路径时,并非寄存器之间组合逻辑云所有单元和连线的简单相加,而要根据实际设计,考虑时钟的边沿敏感性,单元的上升沿下降沿延时不同。实际上, DesignTime 在计算每条路径的时候, 都会考虑边沿敏感性,即分别根据上升下降沿计算两次。
时序分析建立在路径上,两个寄存器之间是一条路径,setup和hold在一条路径上只可能有一个存在不满足情况,一般情况下不会存在setup和hold互卡的情况,也就是不存在乒乓debug,因为setup和hold在一个周期下很小,如果存在乒乓debug情况,考虑是否工艺落后无法支持高频时钟。Thold <= Tck-q +Tdp <= Tclk - Tsetup
6. 修时序思路
由于skew的引入,存在hold不满足,思路1:延时数据,通过分解组合逻辑(pipeline);思路2:如果skew很大,可以缩短时钟之间的相位差,就是时钟树平衡,skew利于setup,不利于hold 。
对于设计尽量避免双沿采样,对于高速时钟,可能会导致数据建立时间不够,有的可以接受。最好统一上升沿设计或者下降沿设计,但下降沿设计在dc综合时存在问题。
7. 创建约束例子
在完成启动文件的书写之后,我就需要根据设计规格书,进行书写约束了–>时钟的约束(寄存器和寄存器之间的路径约束):
1.时钟频率为333.33MHz,因此时钟周期就是3ns:
create_clock -period 3.0 [get_ports clk]
2.时钟源到时钟端口的(最大)延时即source latency是0.7ns(design外部时钟源到时钟端口的延时)
set_clock_latency -source -max 0.7 [get_clocks clk]
3.时钟端口到寄存器的时钟端口延时(端口到达触发器延时)即network latency为0.3ns有0.03ns的时钟偏移(design内部的线路延时,可以):
set_clock_latency -max 0.3 [get_clocks clk](贡献skew)
4.时钟周期有0.04ns的抖动
5.需要为时钟周期留0.05ns的建立时间余量
这里我们就要设置不确定因素了,由于设计规格声明是对建立时间留余量,因此我们主要考虑建立时间的不确定因素:
首先是时钟偏移为±30ps,则有可能是前级时钟往后移30ps,同时本级时钟往前移30ps,对于建立时间偏移的不确定因素为30+30 =60ps;
然后是时钟抖动,前级的时钟抖动影响不到本级,因此只需要考虑本级的时钟抖动,由于是考虑建立时间,因此考虑本级时钟往前抖40ps,即对于建立时间抖动的不确定因素为40ps;
最后是要留50ps的建立时间不确定余量;
因此对于建立时间,总的不确定时间为60+40+50=150ps=0.15ns:
set_clock_uncertainty -setup 0.15 [get_clocks clk](skew,jitter一般约束10%-20%,如果产生的时钟比较好,比较稳定,可以适当放松约束)
Thold + Tskew <= Tck-q +Tdp <= Tclk - Tsetup + Tskew
6.时钟转换时间为0.12ns:
set_clock_transition 0.12 [get_clocks clk]
7. 同步多时钟
 上图是一个同步多时钟网络,中间的模块是我们要综合的模块,内部只有一个 CLKC,但是输入和输出都是由不同周期的时钟控制的,也就是说,它们属于不同的路径组(Path
上图是一个同步多时钟网络,中间的模块是我们要综合的模块,内部只有一个 CLKC,但是输入和输出都是由不同周期的时钟控制的,也就是说,它们属于不同的路径组(Path
Group),但是这些时钟 CLKA-CLKE 都是从一个时钟分频得到的,因此称为同步多时钟。观察被综合模块的输入端口, 它同时受两个时钟的约束, 由于它们周期不同, 所以 CLKA
触发的信号到达 FF2 的时间也不是固定的。对于这样的时钟网络,我们需要用到虚拟时钟的概念(Virtual Clock)。对上图要综合的模块而言, 除了 CLKC 之外的其他时钟都可以称为虚拟时钟, 它们有如下要求——
- 在顶层模块之内的其他模块内定义的时钟
- 在当前的被综合模块(current_design)内不包含虚拟时钟驱动的触发器
- 作为当前模块的输入输出延时参考
8. 异步多时钟
异步多时钟网络和同步多时钟网络的结构类似,只是它的各个时钟 CLKA-CLKE 不是
从同一个时钟源中分频产生的, 而可能是不同的两个晶振,如下图所示——

由于是不同的晶振产生的时钟, 它们之间的就不存在最小公约数的关系, 但是在默认情况下, DC 并不知道, 它会认为它们是同步的时钟网络而尽量去找两个时钟之间的最小捕捉时间, 不但浪费了时间而且会产生出不符合要求的电路。 在这种情况下, 我们需要告诉 DC不要管两个时钟之间路径的时序,这里需要用到一个命令——set_false_path。False Path(伪路径)是指电路中的一些不需要考虑时序约束的路径,它一般出现在异步逻辑之中。
9. 多周期路径
我们默认所有组合路径的延时都是一个周期,然而实际电路中也可能存在超过一个周期的路径需要用到 DC 的一个设置多周期路径的命令——set_multicycle_path。

第一个语句说明建立时间是在 FF1 触发后的第二个周期后检查,第二个语句说明保持
时间在 FF1 触发后的第一个周期检查。
默认情况下综合工具会把每条路径定义为单周期路径,即源触发器在时钟的任一边沿启动(launch)的数据都应该由目的触发器在时钟的下一上升沿捕获(capture)。
有的设计可能存在时序例外(timing exceptions),如多周期路径、虚假路径等。数据从起点到终点的传输时间需要一个时钟周期以上才能稳定的路径,这类路径被称为多周期路径。在设计中很多地方都有涉及多周期路径,比如当个两个触发器之间的逻辑如果一个周期执行不完,这种情况一般有两个解决方案: ①插入流水线使得组合逻辑打散 ; ②使用使能信号控制,几个周期读取一次数据。 方法2就需要设定multi-cycle path,方法2和1之间是有区别的。方法1数据的吞吐量更大,方法2牺牲了数据吞吐量,但是设计中有的地方对吞吐量没有要求是可以使用这种方法的。
10.关于约束问题
- set_input_delay和set_output_delay里,选项-clock_fall,说的是时钟下降沿采样。是指设计内部的DFF为下降沿采样,还是指设计外部的DFF为下降沿采样?
答:外部,即假想的在设计外面存在DFF情况下,它用什么沿来采。设计内部的情况不需要你告诉工具,工具自己清楚得很。
11. 关于异步约束
异步路径就是不需要关心的路径,所以一般只要告诉dc不去做该路径的时序检查,但是也可以多做一些约束,例如dc综合出现异步电路中存在触发器之间延时较大走线较远情况,可能会导致亚稳态,所以
set_clock_groups -asynchronous -group clk1
-group clk2
set_max_delay -from Q1 -to D2 1(约束异步电路第一级和第二级之间的时序为1ns)
12. compile_utltra 要set sldb

13. 关于set_max_capacitance
dc出现输出端口的max_capacitance违例,表示设置的set_load过大,dc计算pin load超出工艺库的max_capacitance,可以确认外部(模拟)需要多大的load,其实dc的作用就是综合出合适的器件,所以外部有大load,出现max_capacitance违例已经表示dc综合出了可以驱动最大load的器件,至于违例就交由后端去修正,当然这比较适用在频率比较低的情况下,对于高频下时序比较紧张,需要通过dc set_load值设置的小一些,综合出适当的器件消除违例以满足时序的要求。
link -all
set port_load [load_of std_cell_maxdb/DFF/D]
set_load $port_load [all_outputs] //这里仅说明了解到数字模块外部驱动为模拟模块的寄存器则可以使用该指令自动查询工艺库中寄存器的load大小,并根据实际需要去放大数值
14.关于设计中使用for语句
for的使用,for不对应任何元器件,只是逻辑的复制,所以使用不当不熟练时会导致逻辑不可综合或者产生意想不到的的元器件,在有些项目中是禁止使用的,在Verilog中有两种用法,一种是使用generate语句,一种是在always块中使用,提倡用per脚本将for循环展开,尽量不使用的原因是一防止新人使用错误,二出现问题可以直接定位到元器件。
15.dc遇到loop
dc遇到loop,会自动break loop,disable timing表示时序分析不去分析loop,但问题依然存在。
16.set_max_fanout
这个扇出值一般在25以上,在高速设计中,如果有时序要可以小一点,因为25已经是比较小了。
17.关于高速设计可以尝试优化时序的综合指令
compile_ultra -no_autoungroup -no_boundary_optimization -retime//使用compile_ultra需要指定set synthetic_library “dw_foundation.sldb”
compile -map_effort high -incremental_mapping
18.门控时钟
编译指令-gata_clock ,目的减小功耗,工具自动插上时钟关断器件,插入门控时钟会在时序上的效果更好,工具会自动识别需要插门控的模块(一般找使能开关作为门控的使能开关,但会由于代码风格和设计有的是能不能作为门控使能,导致门控引起逻辑错位,可以将dc综合的文件进行0延时仿真查看功能,或者fm)
参考文献及链接:
- 为什么综合要避免产生latch
- 时序约束(很好)
- 数字设计中的时钟与约束(很好)
- 综合与Design_CompilerPDF(很好)
- 多周期路径及set_multicycle_path详解
- 数字IC时序约束的一些注意事项