【算法路线图】算法小抄题解-一文理解算法体系-费元星
做研发多年,对算法理解一直不够成体系,基本是每次在面试的时候才会去重点看算法,刷一些题,因此在这里,把我多年的总结发出来,希望晚辈站在一个高的位置学习。
最新链接:有道云笔记
--------------------------------------------
高频算法题——每次跳槽刷一遍
结合之前的面试经历和刷leetcode的经历,总计了113道高频算法题,建议在准备面试前的1-2周过一遍,这里尽量用简短的几个词,记录每道题的核心解法,帮助记忆。(文末附上之前求职时刷算法题的经历)
怎么用这个文档:
1)如果你还有1-2个月开始面试,那就跟着这个文档一道一道的写吧,看看里面说的解法是否符合你的预期,不符合,总结自己的思路即可,怎么简单,怎么有助于你记忆,就怎么总结。
2)如果你还有1-2周开始面试,那我相信你已经刷了不少题了,那就跟着这个文档一道一道过,思考自己能否写出来,感觉能写出来的,直接过下一道,感觉把握不大的,再写一遍吧。
同志们,加油冲啊,拿下高薪offer,就差最后这一步“强化记忆”了!
TOP 113
- 两数之和:1:unordered_map遍历LC
解法一:暴力算法,时间复杂度:n^2 ;解法2:定一个hashmap ,降低复杂度为N
两数相加:注意最后的进位不为0,
- 两数相加:2:注意最后的进位不为0;
1:迭代,相同位的值可以想加,定一个进位值;
2:递归:定义一个递归方法,传入两个链表和进位值;
- 无重复字符最长子串:滑动窗口
解法:定一个左指针和最大值,然后进行遍历值是否在hashmap里
滑动窗口题目:
3. 无重复字符的最长子串
30. 串联所有单词的子串
76. 最小覆盖子串
159. 至多包含两个不同字符的最长子串
209. 长度最小的子数组
239. 滑动窗口最大值
567. 字符串的排列
632. 最小区间
727. 最小窗口子序列
- 寻找两个正序数组的中位数:相当于找两个有序数组的第k大的数,二分,先判断k/2和小数组长度大小。
解法:hard级别难在怎么把代码写优雅
解法一:两个数组归并排序之后,取中间值;
解法二:通过切换加二分法查找,但是我没看懂
- 最长回文子串: 二维动态规划
dp[i] [j] = dp[i + 1] [j - 1]. if s[i + 1] [j - 1] 注意这个循环的遍历,外层是len from 0 to n,内层是i from 0 to n,j = i + len
解法1:中心扩展法
解法2:动态规划
- 整数反转:7:注意是否越界,可以用INT_MAX / 10或者INT_MIN / 10判断一下
- 字符串转整数atoi:8:主要就是越界的处理,和6一样,注意一点的就是-12 % 10 = -2,LC
- 正则表达式匹配:10:二维动态规划或者递归求解。LC
解法 dp[i] [j]:s的前i个和p的前j个是否匹配,dp[i] [0] = false, dp[0] [j] = dp[0] [j - 2] if p[j - 1] == '*' dp[0] [0] = true
- 盛最多水的容器:11 :双指针,每次选择小的方向往前/往后移动 LC 最简公式,三目表达式
- 罗马数字转整数: 一次遍历,遍历到第i时,看i + 1的数字,来判断+还是-。LC
- 数字转罗马数字:这个就把所有的罗马数字对应的数字列举出来,然后循环相减。 LC
- 最长公共前缀:横向比较,每次取两个算出最长公共前缀,得到的结果和后面一个继续算。LC
时间复杂度:横纵查找 mn m 为数据里字符串平均长度,n为数量 优化方向是增加2分查找
- 三数之和:排序+双指针 LC
解法:要关注数据重复的情况,时间复杂度:O(N^2)
- 电话号码的字母组合:当循环数不定时,就去递归/回溯吧。【超级经典回溯题】
解法:回溯解法
回溯相关文章汇总
| 题目 |
题解 |
题解 |
难度等级 |
| 全排列 |
两种实现+图解 |
中等 |
|
| 括号生成 |
两种实现+图解 |
中等 |
|
| 电话号码的字母组合 |
两种实现+图解 |
中等 |
|
| 复原IP地址 |
两种实现+图解 |
中等 |
|
| N 皇后 |
两种实现+图解 |
困难 |
- 删除链表倒数第N个节点:双指针,先走N个节点,再一起走。找到删除。 注意用一个dummy节点,放到头部。LC
解法1: 遍历链表,然后遍历全部,找到倒数的几位;解法2:采用压栈的方式,先进后出,弹出的第几位删除; 解法3:双指针 时间复杂度都是O(N)
- 最长有效的括号:32:栈解决,遇到左括号,就进栈,遇到右括号,就出栈,出的时候判断对错。LC
三种解题:1动态规划: 没太懂,
2.栈、解题:利用栈,(入栈,)出栈,然后判断栈是否为空,并统计最大长度;
3.额外的空间 : 注意栈存储下标,开始预先存储一个-1. 或者,利用两个计数器,left和right分别统计左括号和右括号的个数。左往右边找一遍、右往左找一遍;
- 合并两个有序链表:头部的判断,为了不用dummy,先判断两个链表是否都为空。LC 简单级别
- 括号生成:【超级经典回溯题】 组合问题,就上回溯,回溯就是不断加左括号,回溯,弹出左括号,左括号数量大于右括号时,加右括号,回溯,弹出右括号。LC
- 合并K个有序链表:归并排序的典型应用。LC
- 删除有序数组中的重复项:用一个临时变量一致保存前面的不一样的元素。LC
不重复的元素挪到左边:循环对右边的元素往右移动,右迈两步,左边迈一步
- 实现strStr():KMP算法,没法,只能硬背,不要尝试理解了,太费时间。LC
- 两数相除:倍增方法,注意把数都处理成负的,防止越界。位运算,掌握的不
解法:倍增运算,原理要了解到矩阵幂运算、快速乘;将复杂度从O(n) 降低到logn
- 旋转图像(90度):两种方法:先主对角交换,再左右交换;或者 找到旋转后的递推关系:dp[i] [j]---->dp[j] [n - i - 1] LC
解法1:需要辅助数组:matrix_new[j][n - i - 1] = matrix[i][j];
解法2:原地替换

- 搜索旋转排序数组::二分,注意先用nums[mid]和nums[left]相比较,确定[left, mid]和[mid+ 1, right]那个有序,再比较target和nums[left]/nums[right]进行比较 LC
解法:二分查找,在一个旋转后的数组里查找是否有目标值
- 在排序数组中查找元素的第一个和最后一个位置: 二分,查找左边界,右边界。LC
- 有效的数独:36: 注意小数独的遍历[k / 3 * 3, k / 3 * 3 + 2],[k % 3 * 3, k % 3 * 3 + 2] LC
解法:定义三个数组,通过双层for 循环;将数据映射到不同的下标,最后判断是否有重复数据;
- 外观数列:直接写。LC
解法:遍历生成,题目没太懂; 也可以走枚举查询;
- 缺失的第一个正数:41:LC 原地置换,把[1, n]范围内的数对应的下标都取负。(这步之前先把
hash表的思维:
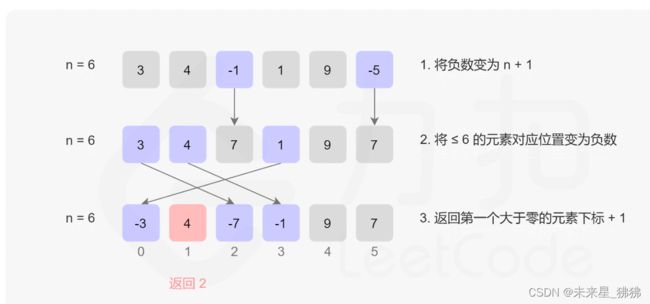
- 接雨水:42:考虑每个位置接多少雨水,也就是求左右两边在该位置最高高度的较小那个减去该位置高度。LC
就是找左边最大值(大于该元素)和右边最大值,两个取较小那个,再减去当前高度。 双指针。
有四种解决方案:1.按行取(超时) 2.按列取 3.动态规划 4.双指针 5.栈,和取有效括号一样
- 通配符匹配:44:二维动态规划
多种组合的动态规划: *符号:dp[i][j] = dp[i][j - 1] || dp[i - 1][j];
- 全排列:回溯法LC 【经典回溯题,必刷的】
Collections.swap 不断交换元素
- 字母异位词分组:使用hash,key是排序后的字符串,value是list ,存的是原始的key。【easy级别的题】
- Pow(x, n):主要考虑越界
- 最大子序和:一维动态规划,dp[i] = dp[i - 1] + nums[i - 1] if dp[i - 1] > 0 LC
- 螺旋矩阵:确定好上下左右四个边界,遍历时一直更新,注意跳出条件LC
- 跳跃游戏:解法1: dp[i] = dp[i - k] && nume[i - k] >= k. 解法2: 贪心 记录当每一步能到的最大值.该值要大于等于i。LC
- 合并区间:先排序,然后插入。LC
- 加1: 注意对9的处理。LC
- x的平方根:典型的二分求左边界。LC
- 爬楼梯:简单的dp。LC
解法:动态规划,和斐波那契数列题相似;还有其他解法没太懂,通项公式、矩阵快速幂
其他动规问题:
1. 746. 使用最小花费爬楼梯:消费版斐波那契数列:dp[i] 下标未i的最小花费; dp[i] = Math.min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
2.62.不同路径 : 转移方程: dp[i][j] = dp[i - 1][j] + dp[i][j - 1]; dp[i][j] 走到当前有多少种方法;
3.63.不同路径2:存在障碍物。 dp[i][j] = (obstacleGrid[i][j] == 0) ? dp[i - 1][j] + dp[i][j - 1] : 0;
4.64.最小路径和:不同路径加一起做为0 的判断
5.343.整数拆分: dp[i] = Math.max(dp[i], Math.max(j * (i - j), j * dp[i - j]));
6.不同的二叉搜索树:96:dp[i] += dp[j - 1] * dp[i - j];
7.不同的二叉搜索树II:95:这个就是想着怎么生成左子树,右子树。然后组合成新的树。
解:第一种方法,对字符串进行遍历,然后死循环匹配,完全匹配上返回下标,时间复杂度:O((n-m)*m)。
第二种解法:KMP 算法是一个快速查找匹配串的算法,它的作用其实就是本题问题:如何快速在「原字符串」中找到「匹配字符串」。
上述的朴素解法,不考虑剪枝的话复杂度是 O(m∗n) 的,而 KMP 算法的复杂度为 O(m+n)。
KMP 之所以能够在 O(m+n) 复杂度内完成查找,是因为其能在「非完全匹配」的过程中提取到有效信息进行复用,以减少「重复匹配」的消耗。
8. 01背包和完全背包、多重背包(leetcode 没有这道题)
01背包:有N种物品,每种物品只有1个,
完全背包:有N种物品,每种物品有无限个;
多重背包:有N种物品,每种物品的个数
- 矩阵置零:用第一行第一列记录该行该列是否有0,然后再单独处理首列首行。LC
- 颜色分类:双指针。LC
- 最小覆盖子串:滑动窗口。比较难,用两个map存储,一个用于存储信息,一个用于记录窗口里的信息。LC
- 子集:回溯法,选择本次元素,回溯,不选本次元素,回溯 LC
- 单词搜索:就是从每一个坐标,递归搜索. 回溯法。visted[i] [j] = true 回溯 false
- 柱状图中最大矩形:对于每个点,需要求出左边的第一个小于该点高度的坐标,右边第一个小于该点长度的坐标,这就需要递增栈,一个是i = 0...n-1,一个是i = n - 1...0。递增栈模板:LC
- 合并两个有序数组:从后往前遍历 LC
- 解码方法:一维动态规划,dp[i]:表示s的前i个字符编码数。LC
c++ dp[i] = dp[i - 1] if s[i - 1] // 是合法字符 dp[i] = dp[i] + dp[i - 2] if s[i - 2, i - 1] // 是合法字符
- 二叉树的中序遍历:递归和非递归两种写法。LC
- 编辑距离:二维dp. LC
c++ // dp[i][j]: 表示word1的前i字母,word2的前j个字母,编辑距离 if (word1[i - 1] == word2[j - 1]) dp[i][j] = dp[i - 1][j - 1] else dp[i][j] = min(dp[i][j - 1], dp[i - 1][j], dp[i - 1][j - 1]) + 1
- 验证二叉搜索树:递归,注意需要传递辅助信息:最小节点,最大节点。LC
c++ isValidBSTCore(TreeNode* root, TreeNode* min_tree, TreeNode* max_tree)
- 对称二叉树:递归,需要辅助函数,输入是两个节点,判断这两个节点是否是对称的。LC
c++ bool isSymmetricCore(TreeNode* left, TreeNode* right);
- 二叉树的层序遍历:easy题,借助队列LC
- 二叉树的锯齿形层序遍历:层序+双栈结合,再使用一个标识位来标识每次是左右孩子哪个先入栈。LC
- 二叉树的最大深度:max(l, r) + 1,递归。 LC
- 从前序与中序遍历序列构造二叉树:找到根,递归构造左右子树。LC
- 将有序数组转换为二叉搜索树: 每次取中间节点,进行根节点的构建。 LC
- 填充每个节点的下一个右侧节点指针:构建辅助函数,传入左右孩子节点。LC
- 杨辉三角:easy,找到每一行元素与上一行元素的关系。LC
- 买卖股票的最佳时机:easy,记录每个元素之前的最小元素值。LC
- 买卖股票的最佳时机II,不限次数:二维dp,其中第一维是第i天,第二维是持有/不持有。LC
- 二叉树的最大路径和:像这种不直接的题,肯定需要辅助函数,辅助函数记录每个节点加上其一个左右孩子节点中的一个可能构成的最大的边。LC
- 验证回文串:左右指针遍历即可。LC
- 单词接龙:解法1: BFS求解,利用队列存每层结果,利用hashset存字典,再用一个hashset存已经访问过的节点(必须有,否则必出现死循环)。解法2: 双向BFS,一个hashset存字典,一个hashset存正向遍历,一个hashset存反向遍历,一个hashset存已经访问过的,每层遍历,交换前两个hashset。LC
- 最长连续序列:一个hashset存储所有的,然后从begin开始,遍历begin,以及其所有上和下连续节点,遍历时不断删除,并同时更新最大连续值。LC
- 被围绕的区域:先对边界的O进行DFS寻找其所有的O,都修改成#,然后把矩阵都变成X,再把所有的#都修改成O。核心是DFS那块,四个方向。LC
- 分割回文串:这种分割问题,求组合的,等等,都是回溯法,这一题需要先用二维数组dp[i] [j]存储字符串中i到j是否是回文串。LC
c++ // 看下回溯的模板 void dfs(vector> & res, vector &temp, string s, int index) { if (index == s.length()) { res.push_back(temp); return; } for (int i = index; i < s.length(); i++) { if (dp[index][i]) { temp.push_back(s.substr(index, i - index + 1)); dfs(res, temp, s, i + 1); temp.pop_back(); } } }
- 加油站:贪心,用两个变量分别记录gas-cost的累积和total和cur,如果cur小于0,则重新置cur=0,更新res为下一个i,继续记录。LC
c++ for (int i = 0; i < gas.size(); i++) { total += gas[i] - cost[i]; cur += gas[i] - cost[i]; if (cur < 0) { res = (i + 1) % gas.size(); cur = 0; } }
- 只出现一次的数字:使用异或操作。LC
可以通过二分查找,时间复杂度logn 或者通过异或;元星总结:二分查找 扩展题,三个元素一样,只出现过一次;
- 复制带随机指针的链表:在每个节点后面多加一个节点,都加完以后再单独处理每个节点的random节点,然后再拆分。LC
- 单词拆分:一维动态规划。 拿到题目如果没有思路,就想想能不能用动态规划来解决,不能再考虑回溯,BFS等方法。LC
c++ // d[i] : 表示前i个字符是否可以被拆分都在单词表里 dp[i] = dp[i - k] && s[i-k+1...i] in wordDict
- 单词拆分II:就是求所有的可能,这种就是回溯法(DFS),确定回溯的输入参数,以及退出条件,回溯的可能步骤。LC
- LRU缓存机制:使用双向链表存储key,value。使用unordered_map存储key和节点,方便寻找。注意get操作需要把访问的节点移动到链表头,put操作需要把访问的节点移动到头,超出capacity 的,要删除尾部的,所有过程都要更新map。LC
- 排序链表:归并排序,每次找到链表的中点(注意奇数节点个数/偶数节点个数有点区别),把中点->next修改成nullptr。然后对这两段分别调用排序,排好序的,子集再调用合并两个链表的操作。LC
- 直线上最多的点数:对于每一个点,统计该点与其他点的斜率,用unordered_map的key存储斜率,用value存储个数。LC
- 基本计算器II:LC
- 寻找峰值:这个二分,有点意思。LC
- 分数到小数:长除法,先判断分子分母是否为0,再判断正负,再判断是否能够整除,然后循环存储,并记录余数。LC
- 多数元素:LC
- 逆波兰表达式求值:利用栈。LC
- 乘积最大子数组:使用两个一维dp,注意压缩成临时状态时,变量不要叠加,要换成其他变量代替。LC
c++ max_dp[i] = max(min_dp[i - 1] * nums[i - 1], max_dp[i - 1] * nums[i- 1], nums[i - 1]); min_dp[i] = min(min_dp[i - 1] * nums[i - 1], max_dp[i - 1] * nums[i- 1], nums[i - 1]);
- 最小栈:使用两个栈。LC
- 相交链表:先计算出两个链表长度差,然后让长的链表先走这个差,再一起走。LC
- N皇后:经典回溯。LC
- 阶乘后的零:LC
c++ return n == 0 ? 0 : n / 5 + trailingZeroes(n / 5);
- 最大数:排序+重构比较函数。LC
- 旋转数组:三次翻转。LC
- 颠倒二进制位:利用左移右移,n & 1取最后一位。LC
- 位1的个数:每次利用n & (n - 1)去掉右边的1 LC
- 打家劫舍:一维dp,easy。LC
dp[i]表示抢劫到第i家,累计最大收益 dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]); 这种都可以进行状态压缩
- 打家劫舍III:后续遍历。LC
c++ 正确的理解: 自底向上的 rob(root)就是以root为根,所能偷到的最高金额,这里涉及到可能偷root,也可能不偷root的 由于不能偷相邻的,如果偷root,则不能偷其左右孩子,但是可以偷其左右孩子的孩子 max(root->val + rob(root->left->left) + rob(root->left->right) + rob(root->right->left) + rob(root->right->right), rob(root->left) + rob(root->right)) 使用map存储,减少遍历
- 岛屿数量:LC
- 快乐数:用一个set保存每次变换结果,如果某次结果在set里,说明重复出现过。LC
- 计数质数:筛选法。LC
- 反转链表:LC
- 课程表:要做某事,必须先做其他事,问是否有可能,说白了就是判断图中是否有环,拓扑排序。两种做法:一种是DFS:
一种是BFS:先构建邻接矩阵,并统计每个课程(节点)的入度。把入度为0的都加到队列中,然后遍历队列,弹出元素(入度为0的节点),以从邻接矩阵中找到以该节点为入度的其他节点,并分别将它们的入度都减去一。最后判断所有节点的入度是否为0。LC,课程表II:LC
- 实现 Trie (前缀树):创建时,先创建26个孩子节点,并都置为nullptr。insert时,对于某个字母,先判断以其为索引的孩子节点是否存在,不存在需要创建,遍历到最后,需要置结束标识位。LC
- 单词搜索II:LC
- 存在重复元素:排序/哈希表LC
- 天际线:使用一个vector排序,遍历,放到multiset里(右端点放进去,左端点出来),获取最大高度,更新结果。LC
- 二叉树中所有距离为K的结点:LC
- 二叉搜索树中第K小的元素:LC
- 回文链表:找到链表中点进行反转后半部分,再比较。LC
- 二叉树的最近公共祖先:LC
- 删除链表中的节点:赋值为链表下一个节点的值。LC
- 除自身以外数组的乘积:左右乘积列表。LC
- 滑动窗口最大值:维持一个非严格单调递减队列。LC
- 搜索二维矩阵:右上->左下搜索,可以用二分加快搜索LC
- 有效的字母异位词:LC
- 缺失的数字:求和,再减。LC
- 完全平方数:返回和为n的完全平方数的最少数量,求最少这种问题,首先想到dp。
解法:转移方程:dp[n] = min(dp[n - i * i]) . for i = 0...sqrt(n) init dp[n] = i.
- 移动零:把0移动数组的最左边/最右边,双指针,一个遍历,一个记录0的位置。LC
for (int i = 0; i < n; i++) { if (nums[i] == 0) { continue; } else { swap(nums[p_0], nums[i]); p_0++; } }
115.找出字符串中第一个匹配项的下标:28,for 循环,时间复杂度m*n,KMP算法