双非本科准备秋招(4)——力扣链表与java基础
LeetCode基础链表题
java操作链表的时候要比c++方便一些,因为c++需要自己手动释放资源,而jvm虚拟机具有垃圾回收机制(GC),如果这个对象将来没被引用过,就会自动回收其所占用的内存。
LeetCode上的链表结构不是定义的集合形式,而是结点形式,什么意思呢,举个例子。
public class SinglyLinkedListSentinel{
private Node head = new Node(-1, null);
/**
* 节点类
*/
private static class Node{
int value;
Node next;
public Node(int value, Node next) {
this.value = value;
this.next = next;
}
}
public void addFirst(int val){
···
}
···
}
这种就属于集合的方式定义链表,在里面定义内部类Node节点对象,如果需要使用,只需要创建链表对象,调用其中的方法。
SinglyLinkedListSentinel list = new SinglyLinkedListSentinel();
LeetCode上的相当于把Node节点类直接拿出来,用头节点代表整个链表。
还有一件事,自己之前初学链表的时候,偶尔脑子发抽就再想,为啥定义一个Node node = head,然后给node.next赋值,那头节点就变了,这不应该是两个变量吗?不知道为啥之前学的时候经常这么想,其实就是对象赋值是把地址赋值过去了,所以node和head是一个地址,当时也知道对象的=运算符是赋值地址,但有时候脑子就是转不过来(乐)。
1、203. 移除链表元素
最好是加个哨兵节点(sentinel/dummy node),或者说是虚拟头节点,这样就不用考虑改变头节点的问题了,很方便,代码中SentinelHead就是我定义的虚拟头节点,这样删除元素时,head节点和其他节点都可以统一操作了。
public ListNode removeElements(ListNode head, int val) {
// 遍历链表,删除元素
ListNode SentinelHead = new ListNode(-1, head);
ListNode p = SentinelHead;
// 删除p.next
while(p.next != null){
if(p.next.val == val) {
p.next = p.next.next;
}
else{
p = p.next;
}
}
return SentinelHead.next;
}2、707. 设计链表
考察的就是基础的链表操作,这个题用的就是集合形式,所以得创建一个内部类代表节点。
class MyLinkedList {
Node SentinelHead = new Node(-1, null);
private static class Node{
int val;
Node next;
public Node(int val, Node next){
this.val = val;
this.next = next;
}
}
public MyLinkedList() {
}
public int get(int index) {
Node node = findNode(index);
if(node == null) return -1;
return node.val;
}
public Node findNode(int index) {
int i = -1;
for(Node p = SentinelHead; p != null; p = p.next, i++){
if(i == index){
return p;
}
}
return null;
}
public void addAtHead(int val) {
Node p = SentinelHead;
Node node = new Node(val, p.next);
p.next = node;
}
public void addAtTail(int val) {
Node p = SentinelHead;
while(p.next != null){
p = p.next;
}
p.next = new Node(val, null);
}
public void addAtIndex(int index, int val) {
Node pre = findNode(index-1);
if(pre == null){
return;
}
Node node = new Node(val, pre.next);
pre.next = node;
}
public void deleteAtIndex(int index) {
Node pre = findNode(index-1);
if(pre == null){
return;
}
Node now = pre.next;
if(now == null){
return;
}
pre.next = now.next;
}
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList obj = new MyLinkedList();
* int param_1 = obj.get(index);
* obj.addAtHead(val);
* obj.addAtTail(val);
* obj.addAtIndex(index,val);
* obj.deleteAtIndex(index);
*/3、206. 反转链表
这个题应该有很多做法,在此我用最简单的头插法做了,定义一个新结点(虚拟结点),遍历题目给你的链表,然后每次都插到新结点的头部就好了。本题给的就不是集合的形式,而是头节点代表整个链表。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
// 头插法
ListNode sentinel = new ListNode(-1, null);
ListNode p = head;
while(p != null){
ListNode n = new ListNode(p.val, sentinel.next);
sentinel.next = n;
p = p.next;
}
return sentinel.next;
}
}JAVA基础复习
异常
概念:
如果某个方法不能按正常的方式完成,那就会通过另一个路径退出,此时就会抛出一个封装了错误类型的对象,该方法不返回任何值并且调用此方法的其他代码也不执行。
分类:
Throwable是java所有错误和异常的父类(超类),下一层为Error、Exception
Error:java运行时系统内部错误或者资源耗尽,不会抛出该类对象,只能告知用户,并使程序安全终止。
Exception:分为运行时异常RuntimeException,也可以说是非受检异常,编译时异常CheckedException,也可以说是受检异常。
RuntimeException:java虚拟机正常运行期间抛出的异常,一定是程序员的错误,常见的有NullPointerException
CheckedException:一般是外部错误,这种异常通常发生在编译阶段,编译器强制程序捕获该类异常,要求使用try···catch···finally来捕获。
处理方式:
不处理,继续抛给调用者。
抛出异常的方式:throw,thorws,系统自动抛出
throw与throws区别:
位置不同:throw用在函数内,后面加异常对象;throws用在函数上,后面加异常类
作用不同:throw抛出具体的问题对象,执行到throw,功能就结束了;throws用来声名异常,表示出现异常的可能性,让调用者知道该功能可能出现什么问题,可以给出预先处理的方案。
内部类
内部类是类的五大成分之一(成员变量、方法、构造器、内部类、代码块) 。
分类:分为静态内部类,成员内部类,局部内部类,匿名内部类
静态内部类:
定义在类内部的静态类就是静态内部类。
静态内部类创建对象:
//格式:外部类.内部类 变量名 = new 外部类.内部类();
Outer.Inner in = new Outer.Inner();静态内部类可以访问外部类所有的静态成员(包括private)
成员内部类:
定义在内部类的非静态类。成员内部类不能定义静态方法和变量(final修饰的除外)。
局部内部类:
定义在方法中的类。如果一个类只在该方法中使用,可以考虑。
public void test(){
//局部内部类
class Inner{
public void show(){
System.out.println("Inner...show");
}
}
//局部内部类只能在方法中创建对象,并使用
Inner in = new Inner();
in.show();
}匿名内部类:
匿名内部类是一种特殊的局部内部类;所谓匿名,指的是程序员不需要为这个类声明名字。
匿名内部类本质上是一个子类,会立即创建一个子类对象继承父类或实现接口,我们自需要重写父类/接口的方法即可。
new 父类/接口(参数值){
@Override
重写父类/接口的方法;
}匿名内部类的作用:简化了创建子类对象、实现类对象的书写格式。
泛型
泛型提供了编译时类型安全检测机制,本质上是参数化类型,即所操作的数据类型被指定为一个参数。
泛型通配符:
1. 表示该通配符所代表的类型是T类型的子类。
2. 表示该通配符所代表的类型是T类型的父类。
3、类型通配符一般是使用?代替具体的类型参数。
类型擦除:java中的泛型基本上都是在编译器这个层次实现的,生成的字节代码中不包含泛型中各类型的信息。使用泛型时加上的类型参数,在编译的时候会被去掉,这就是类型擦除。
JAVA复制
将一个对象引用复制给另外一个对象,有三种方式。
1、直接赋值复制
Student s1 = s2;
这里的复制就是引用,s1和s2指向同一个对象,s1里面成员变量变化,s2里面成员变量也会变。
2、浅拷贝
创建一个新对象,把当前对象的非静态字段复制到新对象。如果字段是值类型,对字段进行复制。如果字段是引用类型,则复制引用但不复制引用的对象。
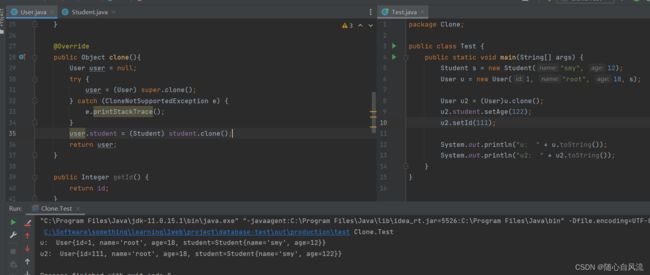
浅拷贝需要继承Cloneable接口,重写clone()方法。
@Override
public Object clone(){
User user = null;
try {
user = (User) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return user;
}如图所示,修改u2的student的值,u的student的值也会改变,说明是复制引用。

3、深拷贝
在clone方法中,把student也拷贝一份
@Override
public Object clone(){
User user = null;
try {
user = (User) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
user.student = (Student) student.clone();
return user;
}如此,修改u2的student的值,u中的student不会变,说明是复制了引用对象