深度学习核心技术与实践之深度学习研究篇
非书中全部内容,只是写了些自认为有收获的部分。
Batch Normalization
向前传播
(1)三个主要任务:计算出每批训练数据的统计量。
对数据进行标准化
对标准化后的数据进行扭转,将其映射到表征能力更大的空间上
有效性分析
內部协移
(1)内部协移是由于神经网络中每层的输入发生了变化,造成每层的参数要不断地适应新分布的问题
(2)BN可以在数据经过多层神经网络后,重新回到均值为0、方差为1的分布上,解决了以上问题,使数据的变化分布变得稳定,训练过程也随之变得平稳,超参数的调整变得简单
梯度流
(1)BN能够减少梯度对参数的尺度或初始值的依赖,使得调参更加容易。
(2)BN允许网络接受更大的学习率,学习率的尺度不会明显影响所产生的梯度的尺度。
(3)由于梯度流的改善,模型能够更快地达到较高的精度
使用与优化方法
为了最大化发挥BN的优势,在使用BN的网络中,可以采用以下几种优化方法。
(1) 增大学习率。在BN模型中,增大学习率可以加快收敛速度,但不会对梯度流产生副作用。
(2)去掉Dropout。
(3)减少L2正则的权重。将L2正则减少到1/5
(4)提高学习率的衰减速度。使用了BN后的模型会更快地收敛,所以学习率也应该相应地减小到较低的值。
(5)更加彻底地随机化训练数据,以防止每批数据总是出现相同的样本
(6)减少图片扭曲。因为BN的训练速度更快,能够观察到的图片变少了,所以应该让模型尽可能地观察真实的图片
Attention
Attention的应用
以MNIST为例
(1)模型每一步只把Attention集中在当前的小框(称为Glimpse) 所表现的像素和位置信息上,并以每两步一个字符的方式进行检测。小框以左至右扫过,获得的信息通过RNN不断累积到环境信息(模型的记忆区)中
(2)采用Hard Attention模式(一次只采样选择一个小框)。由于选取小框位置的发射模块引入了随机采样,使得模型无法使用传统的梯度下降法进行训练。然而,一种叫做“策略梯度” 的强化学习技术使得训练定位小框位置变得可能
一瞥模块
(1)对小框包含的信息进行提取
(2)结合小框的位置信息,整合得到一个中间向量
循环模块
(1)两层RNN,下层主要积累识别信息,上层主要负责预测位置
发射模块
(1)将上层RNN输出的累积位置信息映射成二维位置向量,并以这两个位置为中心点进行高斯采样,得到下一步Glimpse的中心位置
分类模块
(1)采用softmax根据下层RNN的输出向量进行预测
上下文模块
(1)解决第一步该往哪里看的问题
(2)接收整张图作为输入,输出一个初始状态向量作为上层RNN的初始输入,从而得到第一个Glimpse的位置
多任务学习
背景
(1)多任务学习可以学到多个任务的共享表示,这个共享表示具有较强的抽象能力,能够适应多个不同但相关的目标
(2)什么是相关任务?
1.如果两个任务是处理输入的相同函数,但是在任务信号中加入独立的噪声处理,那么很明显这两个任务是相关的。
2.如果两个任务用于预测同一个个体的属性的不同方面,那么这些任务比预测不同个体的属性的不同方面更相关。
3.两个任务共同训练时能相互帮助并不意味着它们是相关的。
什么是多任务学习
(1)多任务并行训练并共享不同任务已学到的特征表示,是多任务学习的核心思想
(2)在后向传播的过程中,多任务学习允许共享隐层中专用于某个任务的特征被其他任务使用
多任务分类与其他分类概念的关系
(1)多分类是多标签分类的一种
(2)多标签学习是多任务学习的一种
(3)多任务学习是迁移学习的一种
多任务学习如何发挥作用
提高泛化能力的潜在原因
(1)不相关任务对聚合梯度的贡献对于其他任务来说可以视为噪声
(2)增加任务会影响网络参数的更新
(3)多任务网络在所有任务之间共享网络底部的隐层,或许使用更小的容量就可以获得同水平或更好的泛化能力
(4)多任务学习的收益应归功于额外任务的训练信号中的信息
多任务学习机制
统计数据增强
假定有两个任务T和T’,在它们的训练信号中都加入了独立的噪声,都受益于计算隐层中输入的特征F。一个同时学习了T和T‘的网络,如果发现两个任务共享F,则可以使用两个训练信号通过在不同的噪声处理过程中平均化F,从而更好地学习F
属性选择
一个同时学习T和T’的网络将可以更好地选择与F相关的属性,因为数据增强为F提供了更好的训练信号,使该网络能更好地判断哪些输入用于计算F
信息窃取
一个网络学习T将可以学到F,但一个只学习T‘的网络将不能做到。如果一个网络在学习T’时还学习T,那么T‘可以在隐层中窃取T已经学到的信息,因此可以学得更好
表示偏置
多任务学习任务偏好其他任务也偏好的隐层表示;倾向于不使用其他任务不偏好使用的隐层表示
后向传播多任务学习如何发现任务是相关的
峰值函数
多任务学习的广泛应用
(1)使用未来预测现在
(2)多种表示和度量
(3)时间序列预测
(4)使用不可操作特征
(5)使用额外任务来聚焦
(6)有序迁移
(7)多个任务自然地出现
(8)将输入变成输出:当特征中存在噪声时,将特征作为输出比作为输入更有用,因为额外输出中的噪声比额外输入中的噪声危害小
多任务深度学习应用
脸部特征点检测
(1)希望优化脸部特征点检测和一些不同但细微相关的任务,比如头部姿势估计和脸部属性推断
(2)通过尽早停止辅助任务来促使学习收敛
(3)学习所有任务权重的协方差矩阵来解决收敛速度不同的问题(只能用于损失函数相同时)
DeepID2
(1)通过刻画从不同个体提取的DeepID2特征来增加个体之间的差异,而人脸验证任务通过激励从相同个体提取的DeepID2特征来减少个体内部的变化
(2)常用的约束包括L1/L2范数和余弦相似度,DeepID2采用基于L2范数的损失函数
Fast R-CNN
(1)损失函数L共同训练分类和矩形框回归,通过λ来控制两个任务的损失均衡
旋转人脸网络
(1)共享主任务的所有层,辅助任务附加在主任务后面以提高保留个体身份的能力
MNC
(1)由三个网络构成:区分实例、估计掩码、目标分类
(2)共享卷积特征的任务并不独立,后一阶段的任务依赖于前一阶段的任务的输出
(3)在第二个阶段,将共享的卷积特征和第一个阶段输出的边框作为输入
(4)在第三个阶段,将共享的卷积特征、第一个阶段输出的边框、第二个阶段输出的掩码作为输入,输出每个实例的分类得分
(5)每个任务的Lθ权重都是1,因为后置阶段依赖于更早阶段的输出
模型压缩
(1)网络的表达能力随着深度的增加呈指数级增长
剪枝
(1)删掉参数的本质:删掉不重要的参数
(2)OBD使用二阶偏导来计算“显著性”
(3)使用泰勒展开式来计算目标函数E可以避免计算量过大
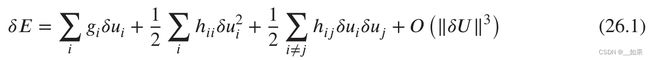
(4)剪枝的目标就是寻找这样一组参数,当删掉这些参数时,E的增长最少
但26.1的计算量还是太大,因此提出假设:海森矩阵都是对角阵,非对角线上的元素都是0,于是第三项可以被忽略;由于此时在E的一个局部最优点,所以第一项可以被忽略。于是26.1近似为:

(5)为了避免计算二阶偏导数,假设绝对值较小的参数就是不重要的参数
(6)L1正则会对非0的参教进行惩罚,所以会产生较多的0附近的参数。如果使用L1正则,在剪枝之后能获得较好的精确率,但是在重新训练后,其精度不如使用L2正则。迭代使用L2正则做剪枝和重新训练,在相同的压缩率下会得到最好的精度
(7)使用 Dropout 时,在训练阶段,每个参数被以一定的概率值丢弃;但是在测试阶段,所有的参数都会参与计算。剪枝与Dropout的区别在于,被剪掉的参数永远不会再回来参与计算。剪枝后,由于参数稀疏化,过拟合的程度被减轻,所以在再训练阶段,Dropout的比例也应该降低。
(8)剪枝之后,如果把剩下的神经元重新初始化再重新训练,效果会比较差。所以,在重新训练被剪枝的层时,需要保留剩下的这些参数
(9)采用迭代的方法,比只使用一次剪枝过程能够取得更好的压缩效果
(10)卷积层对剪枝比较敏感,所以在剪枝过程中需要对卷积层做较多的保留;而全连接层则对剪枝不太敏感,所以可以对全连接层做比较多的压缩
参数共享
(1)使用Hash函数来使多个参数共享同一个数值。这种方法通过限制桶的个数来达到压缩模型的目的
(2)多个数值相近的参数组成一簇,共同使用一个参数
(3)相近参数共享共有4个步骤:
第一步,weight做聚类,一般采用K近邻做聚类
第二步,生成由中心点组成的Codebook
第三步,根据Codebook把各参数数值化
第四步,重新训练,生成新的codebook,并返回第三步迭代训练
(4)原始梯度按照同样的分组方式分为4组,为每组的梯度求和来代表整组参数的梯度

(5)绝对值较大的参数出现的概率低,采用完全随机的方法就没有办法很好地表征这类参数;如果采用线性的方法来选择初始值,则对绝对值较大的参数的表征会更友好
紧凑网络
(1)在神经网络的每一层使用更紧凑的结构同样可以节约存储和计算资源:
在NIN,GoogLeNet,Residual-Net中,采用全局平均池化层来代替全连接层,获得了很好的结果
SqueezeNet采用 1x1 的卷积核代替部分 3x3 的卷积核用来构建非常紧凑的神经网络,参数数量能减少50倍
(2)如果在比较靠前的卷积层使里了比较大的降采样间隔,那么大多数层的激活映射就比较小。如果推迟降采样,或者缩小降采样间隔的大小,则可以让大多数层的激活映射保持在比较合理的大小
(3)紧凑网络与前面所提的剪枝、参数共享的方法可以同时使用
二值网络
(1)在BinaryConnect中,只有第1步和第2步是在二值网络上完成的,而参数更新是在实数网络上完成的
(2)在CPU计算方面,二值参数网络采用加减代替了乘加,二值参数二值输入网络采用位运算代替了大量乘加
GAN
生成模型
(1)生成模型主要用于描述数据分布的情况
(2)隐含变量:不出现在数据的表示中,但对数据的产生起到了十分重要的作用
(3)描述图像分布带来的问题:
1.数据的维度比较高,对于MNIST数据集中的图像,我们可以认为每张图都是28x28维空间中的一个点,这样复杂的空间很难用可视化的方法精确描绘出来,因此就不能用上面的方法将隐含变量分析出来
2.数据间的相关程度较高,导致数据的真实分布并不能够充满整个空间,往往只存在于子空间内,这使得问题的难度又增大不少
生成对抗模型的概念
(1)优化目标:

(2)右边的两个KL项又可以组成一个新的散度度量——Jason-Shannon散度(JS)。KL与JS的最大不同在于JS是一种对称的度量方式,因此不会出现在KL散度中因为不对称造成的问题
GAN实战
模型建议:
(1)将池化层做替换,判别模型可以将其替换为Strided Convolution,生成模型可以将其替换为Fractional Convolution。
(2)在生成模型和判别模型中使用Batch Normalization层。
(3)对于比较深的结构,去掉全连接层。
(4)对于激活函数的使用,在生成模型中使用RelU,最后一层输出使用Tanh;对于判别模型,使用Leaky ReLU,不要使用Sigmoid.
平衡两个网络之间的竞争学习:
(1)让判别模型使用一个和生成模型相比小一些的模型。因为生成模型需要生成一幅图像,难度相对比较大,所以需要更多的参数也是理所应当的,而判别模型只需要给出一个结果,难度相对较小,所以使用一个较小的模型更合适一些。
(2)在判别模型中使用Dropout,这样会使判别模型不易过拟合,因而不容易被生成模型的一些奇怪的图像所迷惑。
(3)在提高判别模型通用性的问题上,使L2正则也可以起到效果;同时,较高的L2正则还可以降低判别模型的能力,让生成模型变得更加容易学习
新的约束:
(1)希望真实数据的中间特征和生成数据的中间特征能够足够相近
InfoGAN
(1)而现在采用高度复杂的非线性函数做拟合,原始隐变量变得十分简单,简单到似乎不太容易找到它与生成数据的关系。比如想要生成一张人脸,我们无法很好地控制生成人脸的细节:脸型、眼睛、鼻子、嘴等,GAN只能帮助生成一样接近于真实的脸,却不能帮助做更多定制化的工作
(2)InfoGAN方法的第一步是重新审视隐变量。隐变量将被分离成两个部分:z继续充当随机噪声的作用;c充当隐式变量的作用,影响最终生成的数据。这样曾经的生成模型G(z)就变成了G(z,c)
(3)加入互信息。互信息的量是一个随机变量X的熵减去已知另一个随机变量Y后它的熵
![]()
Image-Image Translation
(1)在“Encoder-Decoder”网络的基础上增加了部分结构,使得图像长、宽变小的参数被再次利用到模型上,此时的模型结构被称为U-网络
(2)判别模型更偏向于细节部分,给每个局部一个评价概率,将整个图像分成许多小块,判别模型将评价每个小块内的图像是否一致
WGAN
GAN目标函数的弱点
(1)真实数据往往只占完整图像空间的一小部分,而KL散度的计算只在两个分布支撑面重合的区域有意义;JS散度在不重合区域为常值,很难衡量出两个分布之间的距离
(2)从对抗的角度:一旦两个分布没有重叠,对于一般使用的完备正规空间来说,根据乌雷松引理,找到一个连续函数将两个支撑面的映射值完美分开是可行的。而一旦判别模型可以完美分开生成数据分布和真实数据分布,那么生成模型的梯度将消失,这样模型的训练将无法进行
Wasserstein度量的优势
(1)表示一个度量空间下两个概率分布之间的距离,和KL、JS散度一样用来描述分布间的差异
(2)复杂的Wasserstein距离可以化简成:

是一个阶梯状的函数,可导,与KL和JS有很大不同
(3)Wasserstein loss是连续可导的,这样即使真实数据和生成数据的分布不重合,判别
模型将二者完美分开,生成模型也依然拥有梯度,并不会遇到梯度饱和的问题;其次,Wasserstein距离直接衡量了两个分布的移动距离,从数值上看更容易理解