python-自动化篇-运维-语音识别
文章目录
- 理论
-
- 文本转换为语音
-
- 使用 pyttsx
- 使用 SAPI
- 使用 SpeechLib
- 语音转换为文本
- 代码和效果
-
- 01使用pyttsx实现文本_语音
- 02使用SAPI实现文本_语音
- 03使用SpeechLib实现文本_语音
- 04使用PocketSphinx实现语音转换文本
理论
语音识别技术,也被称为自动语音识别,目标是以电脑自动将人类的语音内容转换为相 应的文字和文字转换为语音。
文本转换为语音
使用 pyttsx
使用名为 pyttsx 的 python 包,你可以将文本转换为语音。直接使用 pip 就可以进行安装, 命令如下:
pip install pyttsx3
【示例】使用 pyttsx 实现文本转换语音
import pyttsx3 as pyttsx
engine=pyttsx.init()
engine.say('你好 pyttsx')
engine.runAndWait()
使用 SAPI
在 python 中,你也可以使用 SAPI 来做文本到语音的转换。
【示例】使用 SAPI 实现文本转换语音
from win32com.client import Dispatch
msg="你好 SAPI"
speaker = Dispatch('SAPI.SpVoice')
speaker.Speak(msg)
del speaker
使用 SpeechLib
使用 SpeechLib,可以从文本文件中获取输入,再将其转换为语音。先使用 pip 安装, 命令如下:
pip install comtypes
【示例】使用 SpeechLib 实现文本转换语音
from comtypes.client import CreateObject
engine=CreateObject("SAPI.SpVoice")
stream=CreateObject('SAPI.SpFileStream')
from comtypes.gen import SpeechLib
infile='demo.txt'
outfile='demo_audio.wav'
stream.Open(outfile,SpeechLib.SSFMCreateForWrite) engine.AudioOutputStream=stream
f=open(infile,'r',encoding='utf-8')
theText=f.read()
f.close()
engine.speak(theText)
stream.close()
语音转换为文本
使用 PocketSphinx PocketSphinx 是一个用于语音转换文本的开源 API。它是一个轻量级的语音识别引擎, 尽管在桌面端也能很好地工作,它还专门为手机和移动设备做过调优。
首先使用 pip 命令安装所需模块,命令如下:
pip install PocketSphinx
pip install SpeechRecognition
【示例】使用 PocketSphinx 实现语音转换文本
import speech_recognition as sr
audio_file='demo_audio.wav'
r=sr.Recognizer()
with sr.AudioFile(audio_file) as source:
audio =r.record(source) try:
# print('文本内容:',r.recognize_sphinx(audio,language="zh_CN"))
print('文本内容:',r.recognize_sphinx(audio))
except Exception as e:
print(e)
注意:
□ 安装完 speech_recognition 之后是不支持中文的,需要在 Sphinx 语音识别工具包里 面 下 载 对 应 的 普 通 话 升 学 和 语 言 模 型 。 下 载 地 址 https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Mo dels/
□ 将 下 载 好 的 普 通 话 升 学 和 语 言 模 型 放 到 安 装 speech_recognition 模 块 的 pocketsphinx-data 目录下。
代码和效果
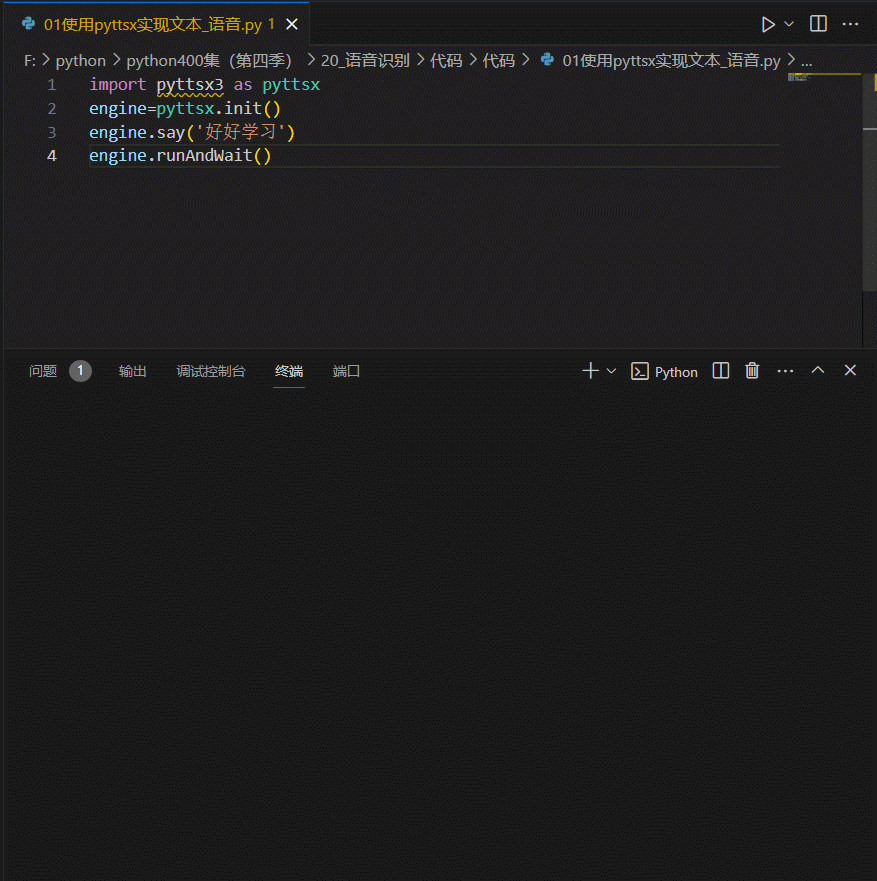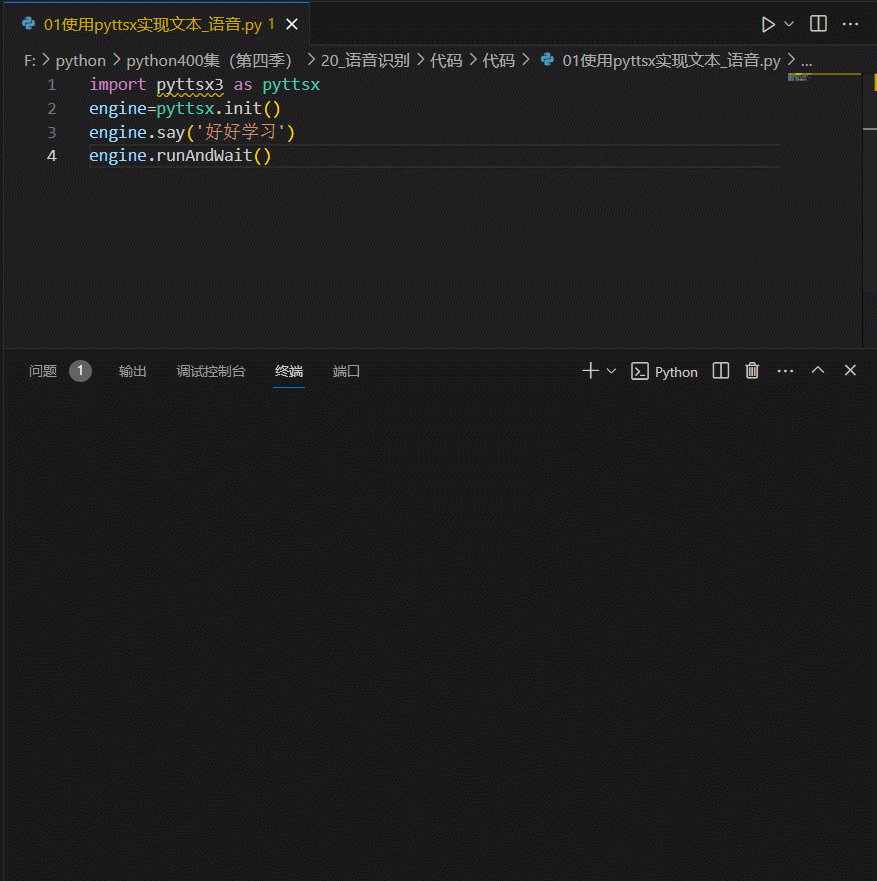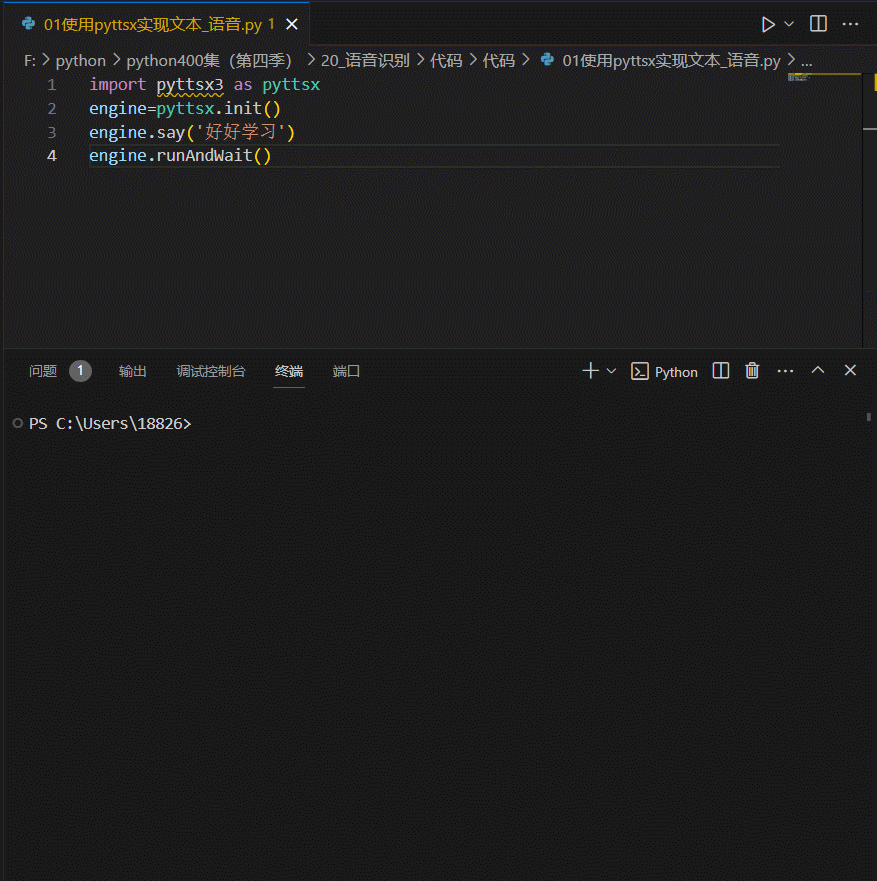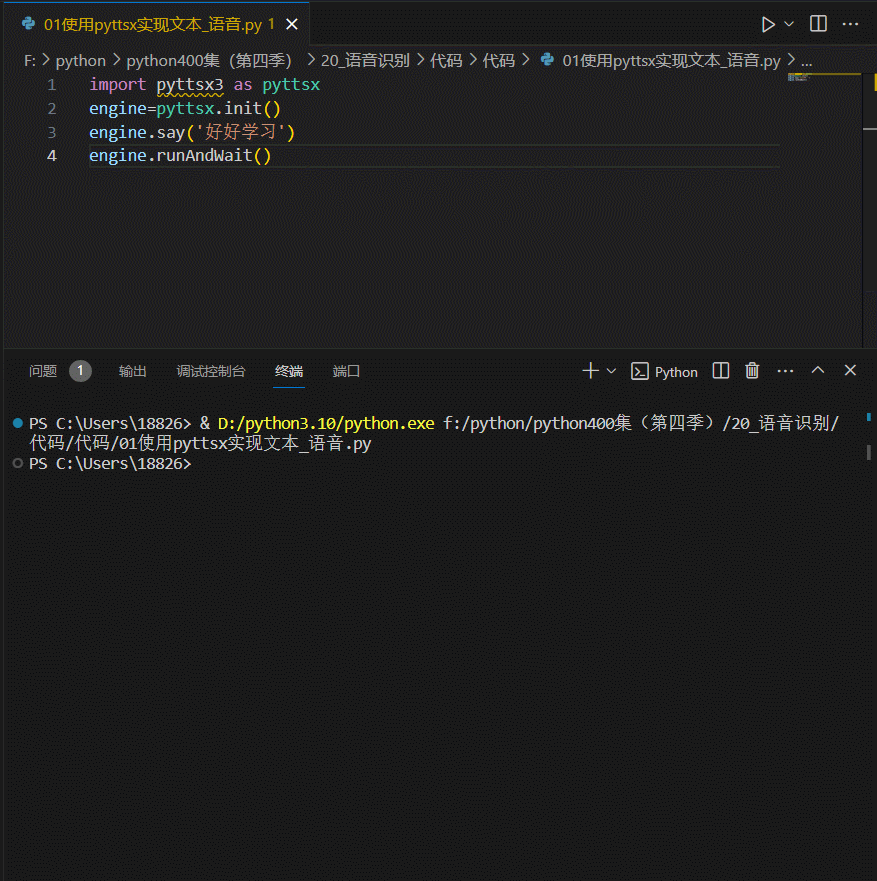
01使用pyttsx实现文本_语音
import pyttsx3 as pyttsx
engine=pyttsx.init()
engine.say('好好学习')
engine.runAndWait()
复制到vscode或其他,运行时需要 pip install pyttsx3

02使用SAPI实现文本_语音
from win32com.client import Dispatch
speaker=Dispatch('SAPI.SpVoice')
speaker.Speak('大家好')
del speaker

03使用SpeechLib实现文本_语音
from comtypes.client import CreateObject
from comtypes.gen import SpeechLib
engine=CreateObject('SAPI.SpVoice')
stream=CreateObject('SAPI.SpFileStream')
infile='demo.txt'
outfile='demo_audio.wav'
stream.open(outfile,SpeechLib.SSFMCreateForWrite)
engine.AudioOutputStream=stream
#读取文本内容
f=open(infile,'r',encoding='utf-8')
theText=f.read()
f.close()
engine.speak(theText)
stream.close()
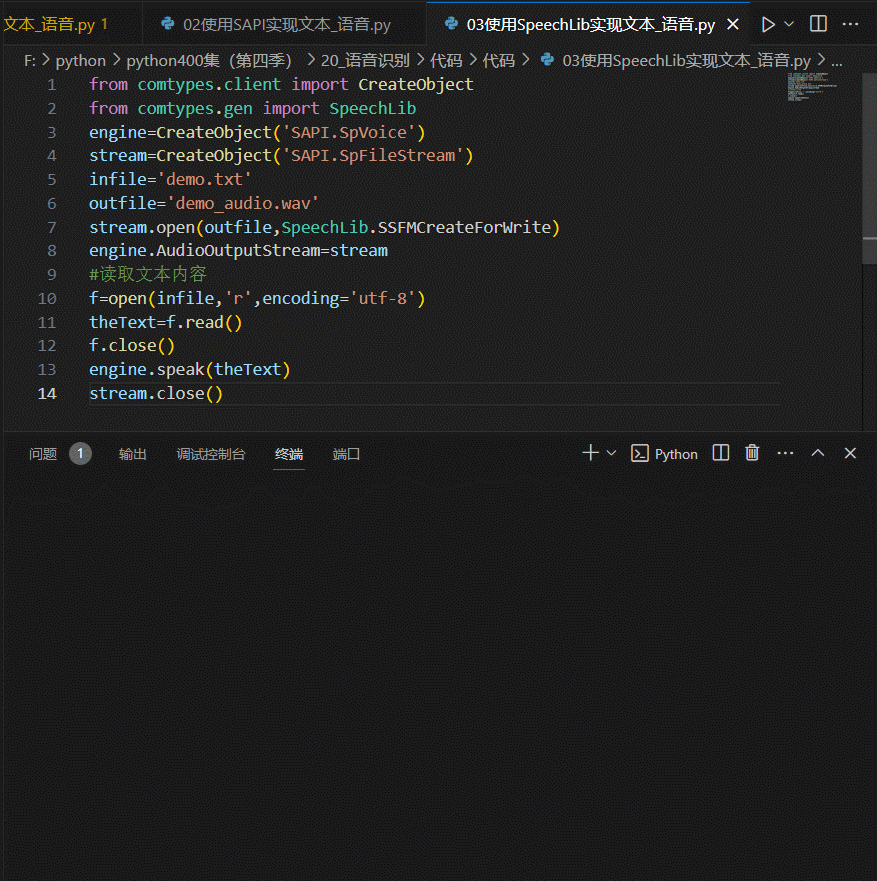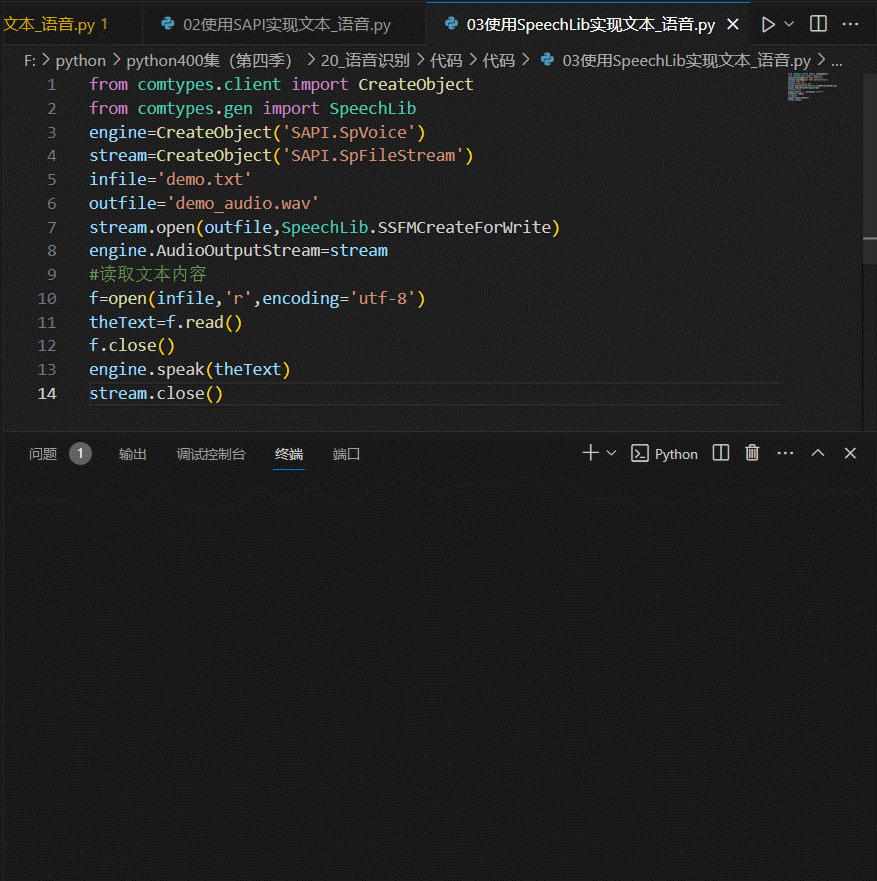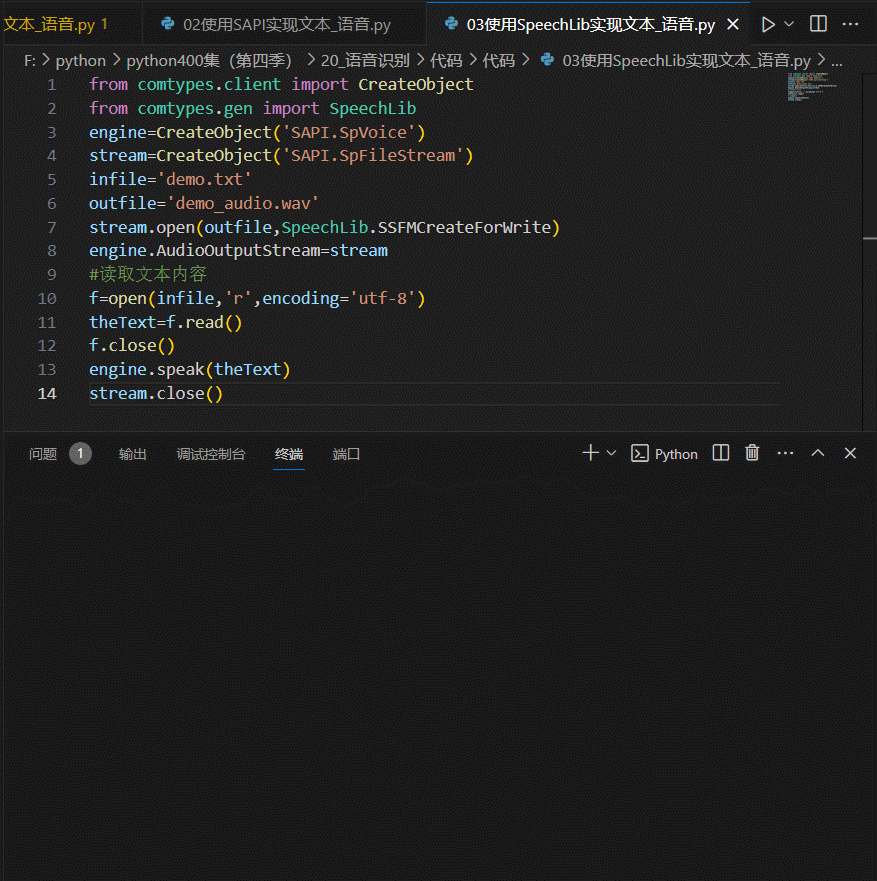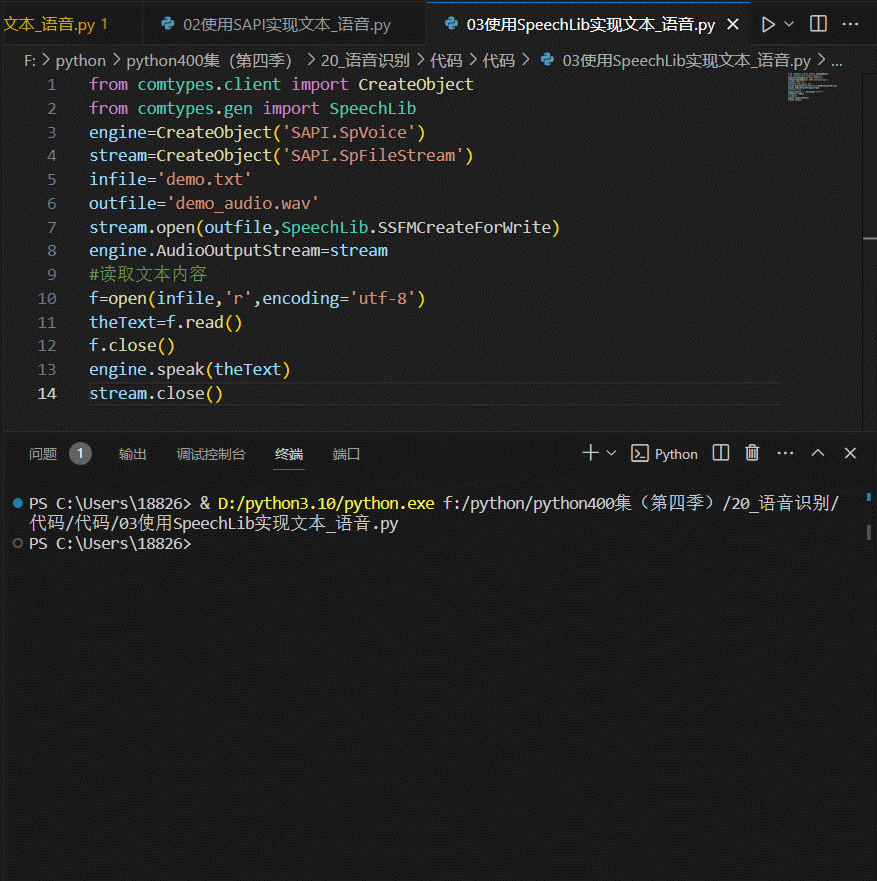
需要将文本放到电脑根目录下


04使用PocketSphinx实现语音转换文本
import speech_recognition as sr
audio_file='demo_audio.wav'
r=sr.Recognizer()
#打开语音文件
with sr.AudioFile(audio_file) as source:
audio=r.record(source)
#将语音转换为文本
# print('文本内容:',r.recognize_sphinx(audio))
print('文本内容:',r.recognize_sphinx(audio,language='zh-CN'))
一、安装环境库

ModuleNotFoundError: No module named ‘speech_recognition’
是:pip install speechrecognition

再安装:pip install PocketSphinx

二、文件放根目录
