秋招计算机网络知识汇总
计算机网络常见知识点&面试题
本文进行秋招中常见的计算机网络知识的汇总,来源主要有:
小林Coding
JavaGuide
牛客网
应用层有哪些常见的协议
HTTP:超文本传输协议
超文本传输协议(HTTP,HyperText Transfer Protocol) 主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的,整个过程如下图所示。
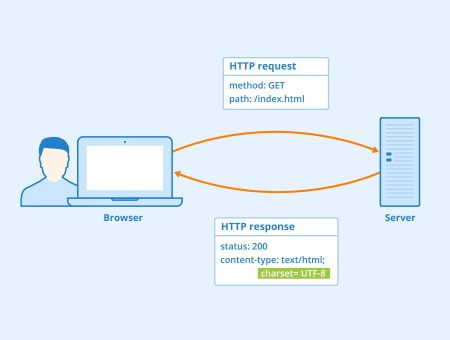
HTTP 协是基于 TCP协议,发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。目前使用的 HTTP 协议大部分都是 1.1。在 1.1 的协议里面,默认是开启了 Keep-Alive 的,这样的话建立的连接就可以在多次请求中被复用了。
另外,HTTP协议是“无状态”的协议,它无法记录客户端用户的状态,一般我们都是通过Session来记录客户端用户的状态
SMTP:简单邮件传输(发送)协议
简单邮件传输(发送)协议(SMTP,Simple Mail Transfer Protocol) 基于 TCP 协议,用来发送电子邮件。
注意⚠️:接受邮件的协议不是 SMTP 而是 POP3 协议。
SMTP 协议这块涉及的内容比较多,下面这两个问题比较重要:
- 电子邮件的发送过程
- 如何判断邮箱是真正存在的?
电子邮件的发送过程?
比如我的邮箱是“[email protected]”,我要向“[email protected]”发送邮件,整个过程可以简单分为下面几步:
- 通过 SMTP 协议,我将我写好的邮件交给163邮箱服务器(邮局)。
- 163邮箱服务器发现我发送的邮箱是qq邮箱,然后它使用 SMTP协议将我的邮件转发到 qq邮箱服务器。
- qq邮箱服务器接收邮件之后就通知邮箱为“[email protected]”的用户来收邮件,然后用户就通过 POP3/IMAP 协议将邮件取出。
如何判断邮箱是真正存在的?
很多场景(比如邮件营销)下面我们需要判断我们要发送的邮箱地址是否真的存在,这个时候我们可以利用 SMTP 协议来检测:
- 查找邮箱域名对应的 SMTP 服务器地址
- 尝试与服务器建立连接
- 连接成功后尝试向需要验证的邮箱发送邮件
- 根据返回结果判定邮箱地址的真实性
POP3/IMAP:邮件的接受协议
这两个协议没必要多做阐述,只需要了解 POP3 和 IMAP 两者都是负责邮件接收的协议即可。另外,需要注意不要将这两者和 SMTP 协议搞混淆了。SMTP 协议只负责邮件的发送,真正负责接收的协议是POP3/IMAP。
IMAP 协议相比于POP3更新一点,为用户提供的可选功能也更多一点,几乎所有现代电子邮件客户端和服务器都支持IMAP。大部分网络邮件服务提供商都支持POP3和IMAP。
FTP:文件传输协议
FTP 协议 主要提供文件传输服务,基于 TCP 实现可靠的传输。使用 FTP 传输文件的好处是可以屏蔽操作系统和文件存储方式。
FTP 是基于客户—服务器(C/S)模型而设计的,在客户端与 FTP 服务器之间建立两个连接。如果我们要基于 FTP 协议开发一个文件传输的软件的话,首先需要搞清楚 FTP 的原理。关于 FTP 的原理,很多书籍上已经描述的非常详细了:
FTP 的独特的优势同时也是与其它客户服务器程序最大的不同点就在于它在两台通信的主机之间使用了两条 TCP 连接(其它客户服务器应用程序一般只有一条 TCP 连接):
- 控制连接:用于传送控制信息(命令和响应)
- 数据连接:用于数据传送;
这种将命令和数据分开传送的思想大大提高了 FTP 的效率。

Telnet:远程登陆协议
Telnet 协议 通过一个终端登陆到其他服务器,建立在可靠的传输协议 TCP 之上。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用Telnet并被一种称为SSH的非常安全的协议所取代的主要原因
SSH:安全的网络传输协议
SSH( Secure Shell) 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
Telnet 和 SSH 之间的主要区别在于 SSH 协议会对传输的数据进行加密保证数据安全性。
键入网址到网页显示,期间发生了什么?
9.出境大门——路由器
路由器与交换机的区别
网络包经过交换机之后,现在到达路由器,并在此被转发到下一个路由器或目标设备。
这一步转发的工作原理和交换机类似,也是通过查表判断包转发的目标。
不过在具体的操作过程上,路由器和交换机是有区别的。
- 因为路由器是基于 IP 设计的,俗称三层网络设备,路由器的各个端口都具有 MAC 地址和 IP 地址;
- 而交换机是基于以太网设计的,俗称二层网络设备,交换机的端口不具有 MAC 地址。
路由器的基本原理
路由器的端口具有MAC地址,因此他就能够成为以太网的发送方和接收方;同时还具有IP地址,从这个意义上来说,它和计算机的网卡是一样的。
当转发包时,首先路由器端口会接收发给自己的以太网包,然后路由表查询转发目标,再由相应的端口作为发送方将以太网发送出去。
路由器的包接收操作
首先,电信号到达网线接口部分,路由器中的模块会将电信号转换为数字信号,然后通过包末尾的FCS进行错误校验。
如果没问题则检查 MAC 头部中的接收方 MAC 地址,看看是不是发给自己的包,如果是就放到接收缓冲区中,否则就丢弃这个包。
总的来说,路由器的端口都具有 MAC 地址,只接收与自身地址匹配的包,遇到不匹配的包则直接丢弃。
查询路由器确定输出端口
完成包接收操作之后,路由器就会去掉包开头的 MAC 头部。
MAC 头部的作用就是将包送达路由器,其中的接收方 MAC 地址就是路由器端口的 MAC 地址。因此,当包到达路由器之后,MAC 头部的任务就完成了,于是 MAC 头部就会被丢弃。
接下来,路由器会根据 MAC 头部后方的 IP 头部中的内容进行包的转发操作。
转发操作分为几个阶段,首先是查询路由表判断转发目标。
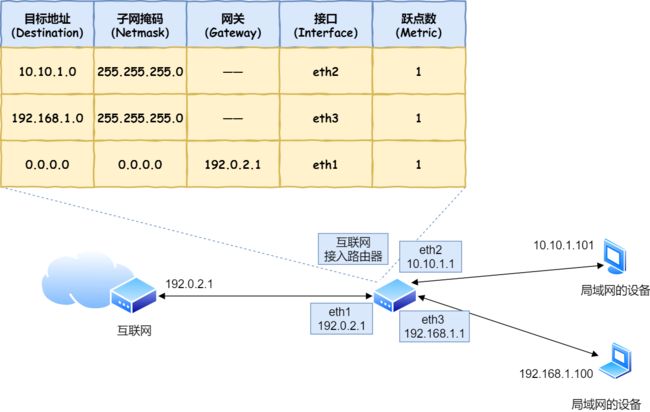
具体的工作流程根据上图,举个例子。
假设地址为 10.10.1.101 的计算机要向地址为 192.168.1.100 的服务器发送一个包,这个包先到达图中的路由器。
判断转发目标的第一步,就是根据包的接收方 IP 地址查询路由表中的目标地址栏,以找到相匹配的记录。
路由匹配和前面讲的一样,每个条目的子网掩码和 192.168.1.100 IP 做 & 与运算后,得到的结果与对应条目的目标地址进行匹配,如果匹配就会作为候选转发目标,如果不匹配就继续与下个条目进行路由匹配。
如第二条目的子网掩码 255.255.255.0 与 192.168.1.100 IP 做 & 与运算后,得到结果是 192.168.1.0 ,这与第二条目的目标地址 192.168.1.0 匹配,该第二条目记录就会被作为转发目标。
实在找不到匹配路由时,就会选择默认路由,路由表中子网掩码为 0.0.0.0 的记录表示「默认路由」。
路由器的发送操作
接下来就会进入包的发送操作。
首先,我们需要根据路由表的网关列判断对方的地址。
- 如果网关是一个 IP 地址,则这个IP 地址就是我们要转发到的目标地址,还未抵达终点,还需继续需要路由器转发。
- 如果网关为空,则 IP 头部中的接收方 IP 地址就是要转发到的目标地址,也是就终于找到 IP 包头里的目标地址了,说明已抵达终点。
知道对方的 IP 地址之后,接下来需要通过 ARP 协议根据 IP 地址查询 MAC 地址,并将查询的结果作为接收方 MAC 地址。
路由器也有 ARP 缓存,因此首先会在 ARP 缓存中查询,如果找不到则发送 ARP 查询请求。
接下来是发送方 MAC 地址字段,这里填写输出端口的 MAC 地址。还有一个以太类型字段,填写 0800 (十六进制)表示 IP 协议。
网络包完成后,接下来会将其转换成电信号并通过端口发送出去。这一步的工作过程和计算机也是相同的。
发送出去的网络包会通过交换机到达下一个路由器。由于接收方 MAC 地址就是下一个路由器的地址,所以交换机会根据这一地址将包传输到下一个路由器。
接下来,下一个路由器会将包转发给再下一个路由器,经过层层转发之后,网络包就到达了最终的目的地。
不知你发现了没有,在网络包传输的过程中,源 IP 和目标 IP 始终是不会变的,一直变化的是 MAC 地址,因为需要 MAC 地址在以太网内进行两个设备之间的包传输。
HTTP协议如何保存用户的状态
HTTP是不保存状态的协议,即无状态协议。也就是说HTTP协议本身不对请求和响应之间的通信状态进行保存。
那么我们如何保存用户状态?————Session机制
Session的主要作用就是通过服务端记录客户端用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的Session之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个Session,过了时间限制,就会销毁这个Session)
在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库 redis 保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
Cookie 被禁用怎么办?
最常用的就是利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
Cookie的作用
- Cookie的作用是什么?与Session有什么区别?
Cookie和Session都是用来跟踪浏览器用户身份的会话方式,但是二者的应用场景不太一样
Cookie一般用来保存用户信息:① 我们在 Cookie 中保存已经登录过的用户信息,下次访问网站的时候页面可以自动帮你把登录的一些基本信息给填了;② 一般的网站都会有保持登录,也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③ 登录一次网站后访问网站其他页面不需要重新登录。
**Session的主要作用是通过服务端记录用户的状态:**典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
Cookie数据保存在客户端(浏览器端),Session保存在服务器端
Cookie 存储在客户端中,而 Session 存储在服务器上,相对来说 Session 安全性更高。如果要在 Cookie 中存储一些敏感信息,不要直接写入 Cookie 中,最好能将 Cookie 信息加密,然后使用到的时候再去服务器端解密。
存储在客户端中,而 Session 存储在服务器上,相对来说 Session 安全性更高。如果要在 Cookie 中存储一些敏感信息,不要直接写入 Cookie 中,最好能将 Cookie 信息加密,然后使用到的时候再去服务器端解密。