1_图神经网络GNN基础知识学习
文章目录
- 对B站前十个视频的补充内容
-
- 视频链接
- 图神经网络的介绍
- 图神经网络的输入格式
-
- 图的输入格式:
- 例子:
- GNNs输入数据的结构
- GNNS中的MaxPooling
-
- “在图神经网络的各个点的特征组合中,对多个点做MaxPooling”这句话是什么意思?
- 举例说明图神经网络中的MaxPooling
- 图的基本组成
-
- 解释1:
- 解释2:
- 举例说明
-
- 实例:社交网络
- GNN的目的——整合特征
-
- 1. 整合特征
- 2. Vertex (or node) embedding
-
- 实例:社交网络中的推荐系统
- 3. Edge (or link) attributes and embedding
-
- 实例:货运网络
- 4. Global (or master node) embedding
- 实例:化学分子
- 全局嵌入、节点嵌入、边嵌入的关系
- 邻接矩阵表达形式为“source, target”
-
- 举例说明:
- 安装PyTorch Geometric
-
- 安装工具包
- 在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类
-
- 两个画图函数
- Graph Neural Networks
- 数据集:Zachary's karate club network.
- PyTorch Geometric
-
- 数据集介绍
- edge_index
-
- 使用networkx可视化展示
- Graph Neural Networks 网络定义:
- 输出特征展示
- 训练模型(semi-supervised)
- 回顾
-
- 综述
- 1. **目标**:
- 2. **数据加载**:
- 3. **数据可视化**:
- 4. **模型定义**:
- 5. **嵌入可视化**:
- 6. **模型训练**:
- 总结:
- 补充
- 在论文引用数据集上使用图卷积网络 (GCN) 进行节点分类
-
- Cora dataset(数据集描述:[Yang et al. (2016)](https://arxiv.org/abs/1603.08861))
- 试试直接用传统的全连接层会咋样(Multi-layer Perception Network)
- Graph Neural Network (GNN)
对B站前十个视频的补充内容
视频链接
图神经网络的介绍
图神经网络(Graph Neural Networks,GNNs)是专门用于处理图结构数据的深度学习方法。当数据具有显著的图结构特点或关系时,图神经网络特别有用。以下是一些典型的应用场景,你可能会考虑使用图神经网络:
-
社交网络:例如,预测用户可能的新朋友或推荐可能感兴趣的内容。
-
推荐系统:例如,考虑到用户与项目之间的复杂交互,为用户推荐项目。
-
生物信息学:例如,预测蛋白质之间的相互作用或药物与靶点之间的关系。
-
知识图谱:用于实体链接、关系预测或知识图谱补全。
-
物理系统:例如,预测分子稳定性或模拟复杂系统中的粒子行为。
-
交通系统:例如,预测交通流量或路网中的拥堵。
-
通信网络:例如,优化路由路径或监测网络异常。
-
程序分析:例如,程序代码的表示或缺陷预测。
-
金融领域:例如,预测金融网络中的欺诈行为或信贷风险。
-
半监督学习:在少量标注数据的情况下,图神经网络可以利用节点之间的结构信息来提高预测准确性。
-
地理信息系统:例如,预测区域发展或地震风险。
-
计算机视觉:例如,场景解析或3D形状分类。
要决定是否使用图神经网络,需要仔细考虑数据是否有图结构特征,以及图结构信息是否有助于解决问题。如果答案是肯定的,那么使用图神经网络可能是一个有效的选择。
图神经网络的输入格式
图神经网络(Graph Neural Network,GNN)是一种专门为处理图结构数据而设计的神经网络。在GNN中,图被表示为节点(vertices)和边(edges)的集合。每个节点和边都可以有其关联的特征。
图的输入格式:
-
节点特征矩阵 N × F N \times F N×F:
-
N N N: 节点的数量
-
F F F: 每个节点特征的维度
-
若图中有3个节点,每个节点有一个2维的特征,那么节点特征矩阵为:
[ f 1 , 1 f 1 , 2 f 2 , 1 f 2 , 2 f 3 , 1 f 3 , 2 ] \begin{bmatrix} f_{1,1} & f_{1,2} \\ f_{2,1} & f_{2,2} \\ f_{3,1} & f_{3,2} \\ \end{bmatrix} f1,1f2,1f3,1f1,2f2,2f3,2
-
-
邻接矩阵 A A A (可以是二进制的或者权重的):
-
( i , j ) (i, j) (i,j) 的元素表示节点 i i i 和节点 j j j 之间的边的权重或存在性。
-
若三个节点中,1和2、2和3之间有边,那么邻接矩阵为:
[ 0 1 0 1 0 1 0 1 0 ] \begin{bmatrix} 0 & 1 & 0 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \\ \end{bmatrix} 010101010
-
-
边特征 (如果有的话):
- 与节点特征类似,但这是为边分配的。
- 比如在分子的图表示中,边可以表示化学键,边的特征可能表示键的类型。
例子:
假设我们有一个简单的图,其中有3个节点和3条边:
- 节点1的特征是 [2, 3]
- 节点2的特征是 [1, 2]
- 节点3的特征是 [4, 5]
- 节点1和节点2之间有一条边
- 节点2和节点3之间有一条边
那么:
节点特征矩阵:
[ 2 3 1 2 4 5 ] \begin{bmatrix} 2 & 3 \\ 1 & 2 \\ 4 & 5 \\ \end{bmatrix} 214325
邻接矩阵:
[ 0 1 0 1 0 1 0 1 0 ] \begin{bmatrix} 0 & 1 & 0 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \\ \end{bmatrix} 010101010
这是一个非常基础的例子。在实际应用中,图可能会有更复杂的特征和结构,包括有向边、多重边、自循环等。而GNN的变种如GCN、GAT、GraphSAGE等则是根据不同的目标和应用场景对基本的GNN进行改进的。
GNNs输入数据的结构
图神经网络(GNNs)的输入数据基于图结构,而图结构本质上是非规则的。与此对比,传统的神经网络,如卷积神经网络(CNNs)和循环神经网络(RNNs),通常处理的是规则数据,例如固定大小的图像(对于CNNs)或固定长度的序列(对于RNNs)。
具体来说,图数据的特点包括:
-
非固定的节点数和边数:不同的图可以有不同数量的节点和边。
-
节点和边的异构性:图中的节点和边可能有多种类型。
-
动态性:图结构随时间变化,例如社交网络中的新朋友关系或交通网络中的实时流量。
-
无向和有向性:图可以是有向的或无向的。
-
节点和边的属性:节点和边可能具有属性,这些属性可以是向量、标量或其他数据类型。
正因为图结构的这些非规则性质,传统的深度学习方法往往难以直接应用。图神经网络被设计为能够处理这种非规则性,从而可以从图结构中捕获复杂的模式。
所以,是的,图神经网络处理的输入数据通常是非规则的。
GNNS中的MaxPooling
“在图神经网络的各个点的特征组合中,对多个点做MaxPooling”这句话是什么意思?
这句话描述了一种在图神经网络(GNNs)中常用的操作,用于汇总或聚合周围节点的信息。分步骤讲解:
-
图神经网络的节点特征:在GNN中,每个节点都有一个或多个特征。例如,在社交网络中,每个节点(用户)可能有一个特征向量,描述该用户的兴趣或属性。
-
特征组合:当我们在GNN中进行信息传递时,一个节点通常会收集其邻居节点的特征,并将其与自己的特征组合起来。这个过程通常是通过某种聚合函数来实现的,例如简单的求和、平均或是本问题中提到的MaxPooling。
-
MaxPooling:这是一种聚合函数,用于从一组值中选取最大值。在图神经网络的上下文中,对于每个节点,MaxPooling 会独立地从其邻居节点的特征向量中选取最大值。假设我们有一个节点和其三个邻居,每个节点的特征向量是[a, b, c],那么MaxPooling 将分别从所有邻居的第一个、第二个和第三个特征中选取最大值。这样,MaxPooling 可以帮助捕捉周围节点中的最显著或最重要的特征。
使用MaxPooling作为聚合函数的好处是,它提供了一种捕捉邻居节点中最显著特征的机制,有时可以增强模型的表示能力。但它也可能丢失邻居节点中的其他有用信息,所以在实际应用中需要根据具体任务来选择合适的聚合函数。
举例说明图神经网络中的MaxPooling
通过一个简单的例子来解释图神经网络中的MaxPooling操作。
假设我们有一个简单的无向图,包含3个节点。我们可以用以下方式表示该图:
- 节点1: 邻居节点 - 节点2和节点3
- 节点2: 邻居节点 - 节点1
- 节点3: 邻居节点 - 节点1
每个节点都有一个特征向量。假设它们的特征如下:
- 节点1: [2, 4]
- 节点2: [5, 1]
- 节点3: [3, 7]
现在,我们想使用MaxPooling来更新节点1的特征。具体步骤如下:
-
对于节点1的每一个特征维度,我们看其邻居节点在该维度的最大值。
-
对于第一个特征维度:
- 节点2的值是5
- 节点3的值是3
- MaxPooling的结果是5
-
对于第二个特征维度:
- 节点2的值是1
- 节点3的值是7
- MaxPooling的结果是7
因此,使用MaxPooling后,节点1的新特征向量将是[5, 7]。
需要注意的是,此处的MaxPooling只考虑了邻居节点的特征,不包括节点本身。在实际应用中,根据需求,你可能也会考虑节点自身的特征。
此外,这只是一个简单的单层图神经网络示例。在实际的图神经网络中,这样的MaxPooling操作可能会在多个层中进行,并且可能与其他操作(如特征转换或非线性激活函数)结合使用。
图的基本组成
解释1:
这段描述是关于图的基本组成的。在图神经网络(GNNs)中,图由节点(或称为顶点,Vertex)、边(或称为连接,Edge)和全局属性组成。这段描述针对这三个组成部分提供了一些具体的属性例子。逐一解释:
-
V Vertex (or node) attributes:这是关于图中节点或顶点的属性。在GNNs中,每个节点都可能有一个或多个属性。
- node identity:每个节点的唯一标识或编号。
- number of neighbors:该节点连接的其他节点的数量。
-
E Edge (or link) attributes and directions:这是关于图中边的属性。边连接两个节点,并且可能具有方向(有向图)或没有方向(无向图)。
- edge identity:每条边的唯一标识或编号。
- edge weight:边的权重,表示两个节点之间连接的强度或重要性。例如,在社交网络中,权重可能表示两个人之间的互动频率;在交通网络中,权重可能表示道路的通行能力。
-
U Global (or master node) attributes:这是关于整个图的全局属性,适用于整个图,而不是单个节点或边。
- number of nodes:图中的节点总数。
- longest path:图中最长的路径,表示在没有重复的节点或边的情况下,从一个节点到另一个节点所经过的最大步数。这在某些问题,如最短路径问题或网络稳定性分析中,是一个重要的特性。
这三个组成部分和它们的属性共同定义了图的结构和信息内容,为图神经网络提供了输入数据。
解释2:
这段描述概述了图的三个主要组成部分及其相关属性。在图神经网络(GNNs)中,理解这些组成部分及其属性是关键的,因为它们为模型提供了输入信息。我将逐个为你解释:
-
V Vertex (or node) attributes:
- 这是指图中的每个节点(或称顶点)所拥有的属性。
- node identity:表示节点的唯一标识符或名称。
- number of neighbors:表示与该节点直接相连的其他节点的数量。例如,在社交网络中,这可能表示某个人的朋友数量。
-
E Edge (or link) attributes and directions:
- 这是指图中的每条边(或称为连接)所拥有的属性。
- 边可能是有方向的(如在有向图中)或无方向的(如在无向图中)。
- edge identity:表示边的唯一标识符或名称。
- edge weight:边的权重,表示两个节点之间连接的强度或重要性。例如,在物流网络中,边的权重可能表示某条路线的运输容量;在社交网络中,它可能表示两人之间的交互强度。
-
U Global (or master node) attributes:
- 这是指整个图的全局属性。
- number of nodes:图中的节点总数。
- longest path:图中的最长路径,表示在不重复经过任何节点或边的情况下,从一个节点到另一个节点所需的最大步数。例如,这在网络连通性或某些最优化问题中可能是一个关键指标。
总的来说,这些组成部分和属性共同定义了一个图的完整结构和特性。在图神经网络中,这些信息被用来训练模型,以捕获图中的复杂模式和关系。
举例说明
当然可以,让我们通过一个实际例子来解释图的这三个组成部分及其属性。
实例:社交网络
在这个社交网络中,有三个用户:Alice, Bob 和 Charlie。他们之间有一些相互的朋友关系和互动。
1. V Vertex (or node) attributes:
-
Alice:
- node identity: Alice
- number of neighbors: 2 (Bob and Charlie)
-
Bob:
- node identity: Bob
- number of neighbors: 1 (Alice)
-
Charlie:
- node identity: Charlie
- number of neighbors: 1 (Alice)
2. E Edge (or link) attributes and directions:
假设这是一个无向图,表示双向的朋友关系。
-
Alice-Bob:
- edge identity: A-B
- edge weight: 5 (表示Alice和Bob在过去一个月内互动了5次)
-
Alice-Charlie:
- edge identity: A-C
- edge weight: 2 (表示Alice和Charlie在过去一个月内互动了2次)
3. U Global (or master node) attributes:
- number of nodes: 3 (Alice, Bob, Charlie)
- longest path: 2 (例如,从Bob到Charlie需要经过Alice,因此需要两步)
在这个简单的例子中,你可以看到如何为图的每个组成部分定义属性。这些属性可以为图神经网络提供关于图结构、节点关系和整体特征的重要信息。在实际应用中,这些属性可能会更加复杂,并且可能会包括更多的信息,例如用户的个人资料信息、互动的具体内容等。
GNN的目的——整合特征
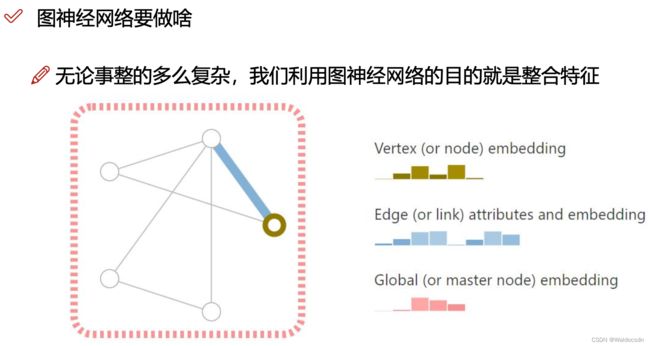
这段PPT的文字内容描述了图神经网络(GNNs)的核心目的及其主要操作。简而言之,GNN的目标是整合或汇总图的特征。以下是详细解释和实际例子:
1. 整合特征
图神经网络的主要目标是整合图中的信息,生成节点、边和全局的嵌入(embeddings)。这些嵌入捕获了图中的结构和属性信息,可以用于各种任务,如节点分类、链接预测和图分类。
2. Vertex (or node) embedding
节点嵌入是指为图中的每个节点生成一个**固定大小的向量表示**。这个表示捕获了节点的属性和其在图中的位置。
实例:社交网络中的推荐系统
假设我们的目标是为社交网络中的用户推荐朋友。为此,我们可以使用GNN为每个用户生成一个节点嵌入。这个嵌入考虑了用户的属性(如兴趣、活跃度)和其社交关系(与哪些用户互动最多)。然后,通过比较这些嵌入,我们可以为用户推荐与其相似的其他用户。
3. Edge (or link) attributes and embedding
边嵌入为图中的每条边生成一个向量表示。它捕获了两个相连节点的关系强度和属性。
实例:货运网络
考虑一个货运网络,其中节点代表城市,边代表运输路线。边的属性可以包括运输成本、运输时间等。GNN可以生成边的嵌入,捕获这些属性和连接城市的重要性。这些嵌入可以帮助优化货物的运输路径。
4. Global (or master node) embedding
全局嵌入为整个图生成一个向量表示。它考虑了图的整体结构和属性。
实例:化学分子
考虑一个任务,要预测一个化学分子的某些属性,如是否有毒。这里,每个原子是一个节点,化学键是边。GNN可以为整个分子生成一个全局嵌入,捕获其整体结构和属性。然后,这个嵌入可以用来预测分子的属性。
综上所述,图神经网络的核心目标是整合图中的特征,为图中的各个组成部分生成向量表示。这些向量表示(或称嵌入)捕获了图的丰富信息,可用于各种下游任务。
全局嵌入、节点嵌入、边嵌入的关系
**全局嵌入、节点嵌入、和边嵌入都是图神经网络(GNN)中生成的向量表示,它们各自捕获了图的不同层面的信息。**下面是这三者的关系和它们分别代表的内容:
-
节点嵌入 (Vertex or Node Embedding):
- 为图中的每个节点生成的向量表示。
- 通常捕获该节点的属性以及与其相邻的节点的信息。
- 例如,在社交网络中,一个用户的节点嵌入可能包含他/她的个人属性(如兴趣、年龄)和与他/她互动过的其他用户的信息。
-
边嵌入 (Edge or Link Embedding):
- 为图中的每条边生成的向量表示。
- 可以捕获连接的两个节点的信息,以及边自己的属性。
- 例如,在货运网络中,一条边的嵌入可能包含表示该运输路线的信息,如运输成本、距离、以及连接的两个城市的重要性。
-
全局嵌入 (Global or Master Node Embedding):
- 为整个图生成的向量表示。
- 捕获图的整体结构和属性,通常包括所有节点和边的综合信息。
- 例如,在分子生物学中,一个分子的全局嵌入可能表示整个分子的性质,如其反应活性、极性等。
关系:
- 节点嵌入和边嵌入通常更关注图的局部信息,而全局嵌入关注的是整体信息。
- 在某些GNN架构中,全局嵌入可以通过汇总所有节点和边的嵌入来生成。
- 在执行某些任务(如图分类)时,全局嵌入特别有用,而在其他任务(如节点分类或链接预测)时,节点和边的嵌入更为关键。
- 这三种嵌入类型提供了不同的视角和信息,可根据特定的应用和任务进行选择和利用。
简而言之,这三种嵌入形式提供了对图数据从局部到全局的不同层面的理解,使得GNN可以灵活地应对各种图相关的任务。
邻接矩阵表达形式为“source, target”

在图论和图神经网络(GNNs)中,邻接矩阵是用来表示图中节点之间关系的主要工具。当我们谈论邻接矩阵,通常我们会想到一个 ( N × N N \times N N×N) 的矩阵,其中 ( N N N) 是图中节点的数量。在这个矩阵中,如果节点 ( i i i) 和节点 ( j j j) 之间有一个边,那么矩阵的第 ( i i i) 行和第 ( j j j) 列的元素值为1,否则为0。
然而,在实际应用和计算中,特别是当我们处理大型图时,这样的完整邻接矩阵可能是非常稀疏的,因此直接存储整个矩阵会浪费大量的内存和计算资源。为了解决这个问题,人们常常采用不同的存储策略,其中一种是仅保存每条边的起始节点(source)和目标节点(target)。
举例说明:
假设我们有以下的小型图:
节点:A, B, C, D
边:(A, B), (A, C), (C, D)
传统的邻接矩阵形式是这样的:
A B C D
A [0 1 1 0]
B [1 0 0 0]
C [1 0 0 1]
D [0 0 1 0]
但是,如果我们只保存source和target,那么我们可以简化为以下的形式:
(A, B)
(A, C)
(C, D)
在这个简化的表示中,我们只列出了图中实际存在的边,省略了大量的0值,从而大大减少了存储和计算的需求。
为了进一步提高效率,很多现代的图处理库和工具,如DGL(Deep Graph Library)和PyTorch Geometric,都支持这种稀疏的边列表表示形式,这样可以更高效地进行计算和存储。
安装PyTorch Geometric
安装工具包
打开链接https://github.com/pyg-team/pytorch_geometric,点击图中箭头处,使用编译好的版本来安装:
使用以下代码片段来查看PyTorch、CUDA和Python的版本:
import torch
# 查看PyTorch版本
print("PyTorch版本:", torch.__version__)
# 查看CUDA版本(如果使用GPU)
if torch.cuda.is_available():
print("CUDA版本:", torch.version.cuda)
else:
print("未找到可用的CUDA")
# 查看Python版本
import sys
print("Python版本:", sys.version)
运行截图:

根据版本点击下图中链接:
再根据python版本选择安装相应的依赖包,安装命令pip install 包名:
最后执行命令pip install torch_geometric便可
在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类
本部分为代码学习,可以将代码放入Jupyter中运行
两个画图函数
%matplotlib inline
import torch
import networkx as nx
import matplotlib.pyplot as plt
def visualize_graph(G, color):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
nx.draw_networkx(G, pos=nx.spring_layout(G, seed=42), with_labels=False,
node_color=color, cmap="Set2")
plt.show()
def visualize_embedding(h, color, epoch=None, loss=None):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
h = h.detach().cpu().numpy()
plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")
if epoch is not None and loss is not None:
plt.xlabel(f'Epoch: {epoch}, Loss: {loss.item():.4f}', fontsize=16)
plt.show()
解析上面代码:
该代码主要包括两部分功能:使用 networkx 和 matplotlib 来可视化图结构(G)和嵌入向量(h)。
首先,我们逐行解析代码:
-
%matplotlib inline: Jupyter Notebook 的魔术命令,它可以确保在 notebook 内部显示绘制的图形。 -
导入所需的库:
torch: 一个开源的深度学习库。networkx as nx: 一个用于创建、操作和研究复杂网络结构和动态的 Python 库。matplotlib.pyplot as plt: 用于绘图的库。
-
visualize_graph(G, color)函数:- 作用:可视化图
G。 - 参数:
G: 要可视化的图。color: 图中节点的颜色。
- 代码解析:
- 设置图形大小为 7x7。
- 删除 x, y 轴的标签。
- 使用
nx.draw_networkx来绘制图。其中nx.spring_layout是一种布局策略,它会模拟节点之间的弹簧效果,使得布局看起来更为平衡。 - 显示图形。
- 作用:可视化图
-
visualize_embedding(h, color, epoch=None, loss=None)函数:- 作用:可视化嵌入向量
h。 - 参数:
h: 要可视化的嵌入向量。color: 向量的颜色。epoch(可选): 当前的训练迭代次数。loss(可选): 当前的损失值。
- 代码解析:
- 设置图形大小为 7x7。
- 删除 x, y 轴的标签。
- 将嵌入从 GPU 转移到 CPU,并从 PyTorch 张量转换为 numpy 数组。
- 使用
plt.scatter函数在二维空间中绘制每个嵌入。 - 如果提供了
epoch和loss,则在图形的 x 轴标签上显示这些值。 - 显示图形。
- 作用:可视化嵌入向量
简而言之,这段代码提供了两个函数,一个用于可视化图结构,另一个用于可视化嵌入。这在图神经网络的背景下尤为有用,例如当需要查看节点嵌入的演化或与原始图结构进行比较时。
Graph Neural Networks
- 致力于解决不规则数据结构(图像和文本相对格式都固定,但是社交网络与化学分子等格式肯定不是固定的)
- GNN模型迭代更新主要基于图中每个节点及其邻居的信息,基本表示如下:
x v ( ℓ + 1 ) = f θ ( ℓ + 1 ) ( x v ( ℓ ) , { x w ( ℓ ) : w ∈ N ( v ) } ) \mathbf{x}_v^{(\ell + 1)} = f^{(\ell + 1)}_{\theta} \left( \mathbf{x}_v^{(\ell)}, \left\{ \mathbf{x}_w^{(\ell)} : w \in \mathcal{N}(v) \right\} \right) xv(ℓ+1)=fθ(ℓ+1)(xv(ℓ),{xw(ℓ):w∈N(v)})
节点的特征: x v ( ℓ ) \mathbf{x}_v^{(\ell)} xv(ℓ) , v ∈ V v \in \mathcal{V} v∈V 在图中 G = ( V , E ) \mathcal{G} = (\mathcal{V}, \mathcal{E}) G=(V,E) 根据其邻居信息进行更新 N ( v ) \mathcal{N}(v) N(v):
数据集:Zachary’s karate club network.
该图描述了一个空手道俱乐部会员的社交关系,以34名会员作为节点,如果两位会员在俱乐部之外仍保持社交关系,则在节点间增加一条边。
每个节点具有一个34维的特征向量,一共有78条边。
在收集数据的过程中,管理人员 John A 和 教练 Mr. Hi(化名)之间产生了冲突,会员们选择了站队,一半会员跟随 Mr. Hi 成立了新俱乐部,剩下一半会员找了新教练或退出了俱乐部。
PyTorch Geometric
- 这个就是咱们的核心了,说白了就是这里实现了各种图神经网络中的方法
- 咱们直接调用就可以了:PyTorch Geometric (PyG) library
数据集介绍
- 可以直接参考其API:https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html#torch_geometric.datasets.KarateClub
from torch_geometric.datasets import KarateClub
dataset = KarateClub()
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print(data)
输出为:
Dataset: KarateClub():
======================
Number of graphs: 1
Number of features: 34
Number of classes: 4
Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])
解析上面代码:
此代码使用 torch_geometric.datasets 中的 KarateClub 数据集,这是一个经常在图神经网络研究中使用的经典数据集。KarateClub 数据集描述了一个学校空手道俱乐部的成员之间的关系,其中成员分为两个派系。
接下来,我们逐步解析代码:
-
导入数据集:
from torch_geometric.datasets import KarateClub -
加载数据集:
dataset = KarateClub()这会实例化
KarateClub数据集,并下载相关数据(如果还没有的话)。 -
打印数据集的一般信息:
print(f'Dataset: {dataset}:'): 打印数据集的描述。print(f'Number of graphs: {len(dataset)}'): 打印数据集中图的数量。输出显示只有一个图。print(f'Number of features: {dataset.num_features}'): 打印每个节点的特征数量。输出显示每个节点有 34 个特征。print(f'Number of classes: {dataset.num_classes}'): 打印数据集中的类别数量。输出显示有 4 个类别(四分类任务)。
-
获取第一个图对象:
data = dataset[0]这会获取数据集中的第一个(也是唯一的)图对象。
torch_geometric中的图数据通常用Data对象表示,它包含节点、边以及其他相关信息。 -
打印图对象的描述:
print(data)输出为
Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])。我们可以从中得知:-
x=[34, 34]: 表示图中有 34 个节点,每个节点有 34 个特征。 -
edge_index=[2, 156]: 描述图的边。它是一个 2x156 的整数张量,其中每列表示一条从源节点到目标节点的边。156 表示图中有 156 条边。 -
y=[34]: 是一个长为 34 的整数张量,表示每个节点的标签。 -
train_mask=[34]: 是一个布尔张量,长度为 34,用于指示哪些节点应该用于训练。这在半监督学习设置中很常见,其中只有一小部分节点的标签是已知的。当我们在图数据中进行学习时,尤其是在半监督学习的情境中,我们可能只有图中部分节点的标签。半监督学习是指我们只有一小部分的数据是带标签的,而大部分数据是不带标签的,目标是使用这少量的标签数据同时学习整个数据的表示。
在图神经网络的上下文中,我们可能只有图中的某些节点是有标签的。因此,为了在训练过程中只考虑这些有标签的节点,我们需要一个方法来区分哪些节点是用于训练的,哪些节点不是。这就是
train_mask的作用。train_mask是一个布尔张量,长度与图中的节点数量相同。如果train_mask中的某个值为True,则表示该位置的节点是用于训练的(即该节点有标签);如果值为False,则表示该节点不用于训练。例如,假设我们有以下
train_mask:train_mask = [True, True, False, False, True]这意味着图中的第一个、第二个和第五个节点有标签,将被用于训练;而第三个和第四个节点没有标签,不会被用于训练。
在图神经网络的训练过程中,我们只会计算并反向传播那些
train_mask值为True的节点的损失,从而使模型能够利用这些已知的标签信息。
-
总的来说,这段代码简单地加载了 KarateClub 数据集并显示了其基本信息。这个数据集是描述一个空手道俱乐部内的关系网络,其中包含 34 个节点(成员)和 156 条边(关系),每个节点有一个 34 维的特征向量和一个类标签。
edge_index
- edge_index:表示图的连接关系(start,end两个序列)
- node features:每个点的特征
- node labels:每个点的标签
- train_mask:有的节点木有标签(用来表示哪些节点要计算损失)
edge_index = data.edge_index
print(edge_index.t())
解析上面代码:
这两行代码主要关注图中的边信息,特别是 edge_index 属性。在 PyTorch Geometric(一个流行的图神经网络库)中,边的信息通常以 edge_index 的形式存储。
-
edge_index = data.edge_index:
这行代码从data对象中取出edge_index属性并将其赋值给一个新的变量edge_index。在 PyTorch Geometric 中,edge_index是一个表示图中所有边的张量。edge_index的维度为[2, E],其中E是图中边的数量。每一列代表一条边,其中第一行的值是边的起始节点,第二行的值是边的终止节点。例如,考虑以下
edge_index:tensor([[0, 2, 2], [1, 0, 3]])这表示图中有三条边:从节点0到节点1、从节点2到节点0、从节点2到节点3。
-
print(edge_index.t()):
这行代码首先使用.t()方法转置edge_index张量,然后打印它。转置操作会将[2, E]维度的张量变成[E, 2]维度。继续上面的例子,转置后的张量为:
tensor([[0, 1], [2, 0], [2, 3]])这使得每一行代表一条边,其中第一个值是边的起始节点,第二个值是边的终止节点。这种表示方式更直观,也更容易阅读,尤其是当边的数量非常多时。
总之,这两行代码从图数据对象中提取边的信息并以更易读的格式打印出来。
使用networkx可视化展示
from torch_geometric.utils import to_networkx
G = to_networkx(data, to_undirected=True)
visualize_graph(G, color=data.y)
输出如下:
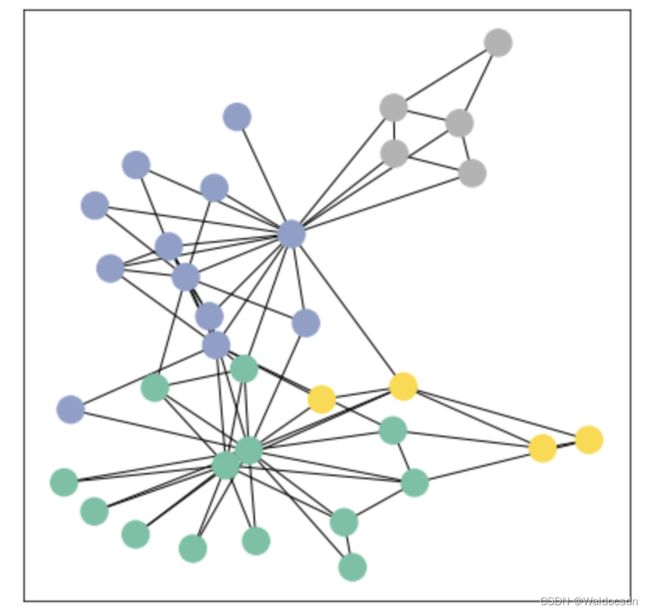
解析上面代码:
这段代码的目的是将 PyTorch Geometric 的图数据转换为 NetworkX 的图格式,并使用前面定义的 visualize_graph 函数将其可视化。以下是对代码的详细解析:
-
导入所需工具:
from torch_geometric.utils import to_networkx这行代码从
torch_geometric.utils中导入了to_networkx函数,这个函数能够将 PyTorch Geometric 的图数据转换为 NetworkX 的图格式。 -
将图数据转换为 NetworkX 格式:
G = to_networkx(data, to_undirected=True)- 这里,
to_networkx(data, to_undirected=True)将 PyTorch Geometric 的图数据data转换为 NetworkX 的图G。参数to_undirected=True表示即使原始图数据可能是有向的,我们也希望得到一个无向图。
- 这里,
-
可视化转换后的图:
visualize_graph(G, color=data.y)- 调用前面定义的
visualize_graph函数来可视化 NetworkX 图G。 - 参数
color=data.y意味着节点的颜色是基于data.y中的标签数据的。这样,不同的节点标签会被赋予不同的颜色,从而在可视化中可以轻松地区分它们。
- 调用前面定义的
综上所述,这段代码首先将 PyTorch Geometric 格式的图数据转换为 NetworkX 格式的图,然后使用给定的节点标签为该图上色并进行可视化。这种可视化通常很有助于理解图的结构和节点间的关系,尤其是当节点标签有意义时(例如,表示不同的社区或类别)。
Graph Neural Networks 网络定义:
- GCN layer (Kipf et al. (2017)) 定义如下:
x v ( ℓ + 1 ) = W ( ℓ + 1 ) ∑ w ∈ N ( v ) ∪ { v } 1 c w , v ⋅ x w ( ℓ ) \mathbf{x}_v^{(\ell + 1)} = \mathbf{W}^{(\ell + 1)} \sum_{w \in \mathcal{N}(v) \, \cup \, \{ v \}} \frac{1}{c_{w,v}} \cdot \mathbf{x}_w^{(\ell)} xv(ℓ+1)=W(ℓ+1)w∈N(v)∪{v}∑cw,v1⋅xw(ℓ)
- PyG 文档
GCNConv
import torch
from torch.nn import Linear
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(1234)
self.conv1 = GCNConv(dataset.num_features, 4) # 只需定义好输入特征和输出特征即可
self.conv2 = GCNConv(4, 4)
self.conv3 = GCNConv(4, 2)
self.classifier = Linear(2, dataset.num_classes)
def forward(self, x, edge_index):
h = self.conv1(x, edge_index) # 输入特征与邻接矩阵(注意格式,上面那种)
h = h.tanh()
h = self.conv2(h, edge_index)
h = h.tanh()
h = self.conv3(h, edge_index)
h = h.tanh()
# 分类层
out = self.classifier(h)
return out, h
model = GCN()
print(model)
输出如下:
GCN(
(conv1): GCNConv(34, 4)
(conv2): GCNConv(4, 4)
(conv3): GCNConv(4, 2)
(classifier): Linear(in_features=2, out_features=4, bias=True)
)
解析上面的代码:
代码定义了一个简单的图卷积网络(GCN)模型。详细分析这段代码:
-
导入必要的库和模块:
import torch from torch.nn import Linear from torch_geometric.nn import GCNConv这些库和模块是构建模型所必需的。
-
定义 GCN 类:
class GCN(torch.nn.Module):通过继承
torch.nn.Module,我们定义了一个新的神经网络模型类GCN。 -
初始化方法:
def __init__(self): super().__init__() torch.manual_seed(1234) ...- 使用
super().__init__()调用父类的初始化方法。 torch.manual_seed(1234)设置随机种子,以确保模型的权重初始化是确定的。
- 使用
-
定义图卷积层和分类器:
self.conv1 = GCNConv(dataset.num_features, 4): 定义第一个图卷积层,它将输入特征(即图中节点的特征数,这里为34)映射到4个特征。- 接下来的两个图卷积层
self.conv2和self.conv3进一步对特征进行转换。 self.classifier = Linear(2, dataset.num_classes): 这是一个线性分类层,用于将最后一个图卷积层的输出(2个特征)映射到目标类别的数量(这里是4)。
-
定义前向传播方法:
def forward(self, x, edge_index): ... return out, h- 这定义了如何对输入数据进行操作以获得模型的输出。
- 数据通过三个图卷积层,并在每层后应用双曲正切激活函数
tanh。 - 输出经过分类器并返回。
-
实例化模型并打印:
model = GCN() print(model)这些行实例化上面定义的
GCN类并打印模型的结构。输出显示了模型包含的各个层及其配置。
输出的解析:
GCN(
(conv1): GCNConv(34, 4)
(conv2): GCNConv(4, 4)
(conv3): GCNConv(4, 2)
(classifier): Linear(in_features=2, out_features=4, bias=True)
)
这个输出描述了 GCN 模型的结构。它有三个图卷积层和一个线性分类器。例如,(conv1): GCNConv(34, 4) 表示第一个图卷积层接受34个特征作为输入并输出4个特征。最后,线性分类器将2个特征映射到4个输出类别。
总体而言,这段代码定义了一个三层的图卷积网络,并为每个节点生成分类分数。
输出特征展示
- 最后不是输出了两维特征嘛,画出来看看长啥样
- 但是,但是,现在咱们的模型还木有开始训练。。。
model = GCN()
_, h = model(data.x, data.edge_index)
print(f'Embedding shape: {list(h.shape)}')
visualize_embedding(h, color=data.y)
输出如下:

解析上面的代码:
这段代码主要关注了两件事:首先,它在一个图上运行定义的 GCN 模型来获取节点嵌入;然后,它使用一个可视化函数来显示这些嵌入。以下是对代码的详细解析:
-
模型实例化:
model = GCN()这行代码创建了
GCN类的一个新实例。该模型已经在前面的代码中被定义,并且它包含了三个图卷积层和一个线性分类器。 -
模型前向传播:
_, h = model(data.x, data.edge_index)这行代码调用了
GCN模型的前向传播方法,传入节点特征data.x和边索引data.edge_index作为参数。这两个参数来源于data,这是一个 PyTorch Geometric 图数据对象。输出是一个元组,其中第一个元素
_是模型的主要输出(分类得分),而第二个元素h是模型的最后一个图卷积层的输出,代表节点的嵌入。 -
打印嵌入的形状:
print(f'Embedding shape: {list(h.shape)}')这行代码将嵌入张量
h的形状打印出来。这有助于我们了解嵌入的维度,通常这是[节点数, 嵌入维度]。 -
可视化嵌入:
visualize_embedding(h, color=data.y)使用之前定义的
visualize_embedding函数,这行代码将嵌入h可视化为一个散点图。这个散点图中的每个点都代表一个节点,位置由其嵌入决定。点的颜色基于data.y,这通常代表节点的标签或类别。
总结:这段代码运行了一个图卷积网络模型,取得了节点的嵌入,并将这些嵌入可视化。这种可视化有助于我们理解模型如何将节点分布在嵌入空间中,以及节点间的相似性和差异性。
训练模型(semi-supervised)
import time
model = GCN()
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Define optimizer.
def train(data):
optimizer.zero_grad()
out, h = model(data.x, data.edge_index) #h是两维向量,主要是为了咱们画个图
loss = criterion(out[data.train_mask], data.y[data.train_mask]) # semi-supervised
loss.backward()
optimizer.step()
return loss, h
for epoch in range(401):
loss, h = train(data)
if epoch % 10 == 0:
visualize_embedding(h, color=data.y, epoch=epoch, loss=loss)
time.sleep(0.3)
解析上面的代码:
这段代码定义了训练流程并执行了400个训练周期。接下来,我们将逐步解析代码的每一部分。
-
初始化模型和工具:
model = GCN() criterion = torch.nn.CrossEntropyLoss() # Define loss criterion. optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Define optimizer.model = GCN(): 创建GCN类的一个新实例,之前已经定义。criterion: 定义了损失函数,这里使用的是交叉熵损失,适用于分类问题。optimizer: 定义了优化器,用于更新模型的权重。这里使用的是Adam优化器,学习率设为0.01。
-
定义训练函数:
def train(data): ... return loss, h这个函数定义了模型的一次训练步骤,并返回损失和节点嵌入。具体步骤如下:
optimizer.zero_grad(): 清除之前梯度的残留。out, h = model(data.x, data.edge_index): 对模型进行前向传播。loss = criterion(out[data.train_mask], data.y[data.train_mask]): 计算损失。由于这是一个半监督学习任务,我们只在具有标签的节点上计算损失,这些节点由train_mask指示。loss.backward(): 基于计算的损失进行反向传播,计算梯度。optimizer.step(): 使用优化器更新模型的权重。
-
训练循环:
for epoch in range(401): loss, h = train(data) ...这个循环执行了401个训练周期。在每个周期,它都会调用上面定义的
train函数,获取损失和嵌入。 -
可视化:
if epoch % 10 == 0: visualize_embedding(h, color=data.y, epoch=epoch, loss=loss) time.sleep(0.3)每10个周期,代码会调用之前定义的
visualize_embedding函数,显示节点的嵌入。time.sleep(0.3)意味着每次可视化之间会有0.3秒的暂停,使得可视化的变化不会过于迅速,这样我们可以更容易地观察节点嵌入的变化情况。
总的来说,这段代码定义了图卷积网络模型的训练过程,并在每10个训练周期后进行嵌入可视化,这样我们可以看到模型是如何逐渐学习将相似的节点放在嵌入空间的相近位置的。
回顾
综述
在训练开始时,嵌入(由h表示)可能是随机的或是在嵌入空间中均匀分布的。这意味着,在散点图中,具有不同标签的节点可能会混在一起,没有明显的聚类。
随着训练的进行,模型会尝试将相似的节点(基于它们的特征和它们在图中的位置)放在嵌入空间中的相近位置,并将不相似的节点分开。这在可视化中表现为:
- 具有相同标签的节点开始聚集在一起。
- 不同的聚类或类别之间形成了明确的边界。
在多次迭代之后,如果模型被成功地训练,我们应该能看到几个清晰的聚类,其中每个聚类代表一种类别的节点。在KarateClub数据集中,由于有4个类,我们期望看到4个聚类。
回顾和总结上面的代码和实践。
1. 目标:
在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类。
2. 数据加载:
首先加载了KarateClub数据集,这是一个经典的小型图数据集。它描述了一个空手道俱乐部中34个成员之间的关系,目标是根据其社交网络关系预测每个成员的团体归属。
3. 数据可视化:
利用networkx库和提供的工具函数,将图数据可视化为网络结构图。
4. 模型定义:
定义了一个简单的GCN模型,它包括三个GCNConv层,用于学习图中节点的嵌入表示,以及一个线性分类器,用于将这些嵌入映射到预测的类别。
5. 嵌入可视化:
在模型定义后,立即进行了一次前向传播,并使用提供的工具函数可视化了初始的节点嵌入。这提供了一个参考点,了解模型训练前节点嵌入的初始状态。
6. 模型训练:
- 设定了交叉熵损失和Adam优化器。
- 定义了一个
train函数来描述单次训练迭代的流程。 - 在400个周期中进行了模型的训练,并每10个周期可视化节点嵌入,以观察模型是如何逐步更新和优化嵌入的。
总结:
我们成功地将图神经网络应用于KarateClub数据集的节点分类任务。首先加载和可视化数据,然后定义了一个GCN模型,之后可视化了初始的节点嵌入。在接下来的训练过程中,观察了随着训练的进行,嵌入如何逐渐形成聚类,以便使具有相同标签的节点更接近。这个实践展示了图神经网络在节点分类任务上的工作方式和其效果。
补充
关于嵌入(由h表示):
嵌入(Embedding)在深度学习和自然语言处理中是一个非常常见的概念。嵌入是将某种类型的数据(如单词、节点、用户或其他实体)转换为固定大小的向量,这样机器学习模型可以更容易地处理它。
代码中,嵌入(由h表示)特指图的节点嵌入。这意味着每个图中的节点都被转换为一个向量。这些向量捕捉了节点的特征和其在图中的结构位置。
以下是关于嵌入的一些详细点:
-
捕捉信息:嵌入向量通常被设计为捕捉关于原始数据的有意义的信息。例如,在词嵌入中,相似的单词会有相似的嵌入。
-
固定大小:不论原始数据的大小或形式如何,嵌入向量都有固定的长度。这对于机器学习模型非常有用,因为它们需要固定大小的输入。
-
图节点嵌入:在图神经网络(如GCN)中,节点嵌入捕捉了节点的特征信息以及其在图中的邻接关系。相邻或相似的节点可能会有相似的嵌入。
-
可视化:由于嵌入是高维数据的向量表示,它们可以用于可视化。在代码中,
h的每个节点嵌入是一个二维向量,这使得它们可以直接在平面上绘制。这种可视化有助于我们理解模型是如何在嵌入空间中组织节点的。
在上下文中,h是图卷积网络(GCN)的输出,它为图中的每个节点提供一个二维嵌入。这些嵌入向量随着模型的训练而更新,以更好地反映节点的特征和其在图中的位置。
在论文引用数据集上使用图卷积网络 (GCN) 进行节点分类
点分类任务学习
Cora dataset(数据集描述:Yang et al. (2016))
- 论文引用数据集,每一个点有1433维向量
- 最终要对每个点进行7分类任务(每个类别只有20个点有标注)
from torch_geometric.datasets import Planetoid#下载数据集用的
from torch_geometric.transforms import NormalizeFeatures
dataset = Planetoid(root='data/Planetoid', name='Cora', transform=NormalizeFeatures())#transform预处理
print()
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print()
print(data)
print('===========================================================================================================')
# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')
输出如下:
Dataset: Cora():
======================
Number of graphs: 1
Number of features: 1433
Number of classes: 7
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
===========================================================================================================
Number of nodes: 2708
Number of edges: 10556
Average node degree: 3.90
Number of training nodes: 140
Training node label rate: 0.05
Has isolated nodes: False
Has self-loops: False
Is undirected: True
解析以上代码:
Planetoid数据集是一个经常用于图神经网络研究的数据集。然后加载了Cora数据,这是一个大型图,主要用于文献分类任务。在Cora数据集中,每个节点代表一篇文献,每个边表示文献之间的引用关系,而节点的特征是文献中单词的存在(或词袋表示)。
以下是代码的详细分析:
数据加载和预处理:
Planetoid:用于下载并加载Planetoid数据集(Cora、CiteSeer和PubMed)。NormalizeFeatures:这是一个预处理步骤,它将节点特征标准化。
数据统计:
接着,打印了关于数据的一些统计信息:
-
数据集信息:
Number of graphs: 数据集中图的数量。Cora只有一个图,所以这个数字是1。Number of features: 每个节点的特征数量。在Cora中,这表示文献的词袋表示。Number of classes: 需要分类的类别数量。这是文献分类任务的类别数量。
-
图数据:
Data(...): 显示了图的主要属性。
这个输出描述了Cora数据集中的一个图结构,其中包含了图的节点特征、边、节点标签和其他信息。下面逐一进行解析:
-
x=[2708, 1433]:
- 这是一个节点特征矩阵,其中包含了2708个节点。
- 每个节点有1433个特征。这些特征是基于文献的词袋表示。换句话说,每篇文献(节点)都用一个1433维的向量表示,每维代表一个词汇表中的单词,其值表示该词在文献中的出现次数或重要性。
-
edge_index=[2, 10556]:
- 这是一个定义图中边的张量。
- “2”表示张量的行数,每行都是一个连接的节点对。这种方式用于定义图中的边。第一行包含源节点的索引,而第二行包含目标节点的索引。
- “10556”表示图中总共有10556条边。
-
y=[2708]:
- 这是节点标签的向量。
- 它包含2708个标签,对应于2708个节点。每个标签可能是一个整数值,表示所属的类别。
-
train_mask=[2708], val_mask=[2708], test_mask=[2708]:
- 这些是布尔掩码,用于分隔数据集中的节点为训练、验证和测试集。
- 这三个掩码都有2708个布尔值。如果
train_mask[i]为True,则表示第i个节点应用于训练;同理,val_mask和test_mask则分别用于验证和测试。 - 这种分隔方法是为了半监督学习设置,其中只有部分节点的标签是已知的,并用于训练,而其余节点的标签则用于验证和测试。
综上所述,Cora数据集包含一个大图,这个图中有2708个节点,10556条边。每个节点有1433个基于词袋模型的特征,并分为7个类别。为了进行机器学习任务(如节点分类),这些节点被分为训练、验证和测试集。
-
图统计:
Number of nodes: 图中的节点数量。Number of edges: 图中的边数量。Average node degree: 平均节点度数,表示每个节点平均连接的边数。Number of training nodes: 用于训练的节点数量。Training node label rate: 用于训练的节点所占的比例。Has isolated nodes: 图中是否有孤立的节点。Has self-loops: 图中是否有自循环,即一个节点是否有指向自己的边。Is undirected: 图是否是无向的。
输出分析:
从输出中,我们可以看到Cora数据集的以下信息:
- 它由一个大型图组成,其中有2708个节点,10556条边。
- 每个节点有1433个特征,这些特征基于文献的词袋表示。
- 需要将文献分类为7个不同的类别。
- 平均每个节点有3.90条边。
- 仅有140个节点的标签用于训练,这意味着大部分节点的标签是隐藏的,这种设置模拟了半监督学习的情景。
- 该图没有孤立节点和自循环,且是无向的。
总的来说,这段代码加载了Cora数据集,进行了预处理,并获取了有关图结构和其属性的详细统计信息。
解释——“每个节点有1433个特征,这些特征基于文献的词袋表示”
“每个节点有1433个特征,这些特征基于文献的词袋表示”这句话涉及到两个重要概念:节点特征和词袋表示法(Bag-of-Words, BoW)。我们逐一解析:
-
节点特征: 在图中,每个节点可以有一个或多个属性或特征。在许多图神经网络任务中,这些特征用于预测节点的标签、分类等。例如,在社交网络中,一个节点可能代表一个人,而节点特征可能包括该人的年龄、性别、职业等。
-
词袋表示法 (BoW): BoW是一种将文本数据(如句子、段落或整篇文档)转化为数值特征的技术。具体来说,它是一种文本模型,其中每个文档表示为一个固定长度的向量。这个向量的长度通常与词汇表(或所有考虑的单词的集合)的大小相同。每个向量的元素表示词汇表中对应单词在文档中出现的次数。
在Cora数据集的上下文中:
-
每个节点代表一篇文献:Cora数据集中的节点代表学术文献。
-
1433个特征:意味着考虑了1433个不同的单词(或可能是由其他文本处理技术,如TF-IDF,提取的1433个特征)。
-
基于文献的词袋表示:每个节点(或文献)的1433个特征值是根据文献内容创建的。特定的特征值表示文献中对应单词的出现次数或其他相关度量。
例如,假设我们的词汇表只有三个词:[“apple”, “banana”, “cherry”]。一个文献中提到"apple" 10次、“banana” 5次,但没有提到"cherry",那么这篇文献的BoW表示将是[10, 5, 0]。
在Cora的实际情境中,每篇文献都被转化为一个1433维的向量,每维代表词汇表中的一个单词,并且数值表示该单词在文献中的重要性或出现次数。
# 可视化部分
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
def visualize(h, color):
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())
plt.figure(figsize=(10,10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")
plt.show()
解析以上代码:
这段代码的目的是为了可视化高维数据。为了方便在二维空间中进行观察,代码使用了t-SNE(t-分布式随机邻域嵌入)算法将高维数据映射到二维空间。下面是对每一部分的详细解析:
-
导入相关的库:
%matplotlib inline import matplotlib.pyplot as plt from sklearn.manifold import TSNE%matplotlib inline: 是一个Jupyter Notebook的特殊指令,使得生成的图像能直接在notebook中显示。import matplotlib.pyplot as plt: 导入matplotlib的绘图模块,常用于数据的可视化。from sklearn.manifold import TSNE: 导入sklearn库中的t-SNE实现。
-
定义可视化函数
visualize:def visualize(h, color): z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy()) ...visualize函数有两个参数:h和color.h是需要可视化的高维数据,而color是一个列表,用于为每一个数据点指定颜色。
-
使用t-SNE进行数据映射:
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())- t-SNE是一种非线性降维方法,经常用于可视化高维数据。这里,我们将数据降到2维。
h.detach().cpu().numpy(): 由于h可能是一个PyTorch的张量,所以先使用detach()分离它,使其不再具有梯度信息;然后用cpu()确保它在CPU上;最后,转换为numpy数组。
-
绘图设置:
plt.figure(figsize=(10,10)) plt.xticks([]) plt.yticks([])plt.figure(figsize=(10,10)): 定义图像的大小为10x10单位。plt.xticks([])和plt.yticks([]): 隐藏x和y轴的刻度。
-
绘制散点图:
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")-
z[:, 0]和z[:, 1]: 表示t-SNE算法映射后的二维数据的x和y坐标。 -
s=70: 指定散点的大小为70。 -
c=color: 指定每个散点的颜色。color是传递给visualize函数的参数,通常是一个与数据点数量相等的列表或数组,表示每个数据点的颜色或类别。 -
cmap="Set2": 定义了一个颜色映射,确保散点图的颜色是从“Set2”调色板中选取的。
-
-
显示图形:
plt.show()- 使用
plt.show()来展示之前定义和配置的图像。在Jupyter Notebook中,这会直接在单元格下方显示图像。
- 使用
总的来说,这段代码定义了一个名为 visualize 的函数,该函数接受高维数据和颜色信息,然后使用t-SNE算法将高维数据降至二维,并在散点图中进行可视化。通过这种可视化,我们可以观察数据点在低维空间中的分布和聚类趋势,从而获得对数据结构和模式的直观了解。
试试直接用传统的全连接层会咋样(Multi-layer Perception Network)
import torch
from torch.nn import Linear
import torch.nn.functional as F
class MLP(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
torch.manual_seed(12345)
self.lin1 = Linear(dataset.num_features, hidden_channels)
self.lin2 = Linear(hidden_channels, dataset.num_classes)
def forward(self, x):
x = self.lin1(x)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin2(x)
return x
model = MLP(hidden_channels=16)
print(model)
输出如下:
MLP(
(lin1): Linear(in_features=1433, out_features=16, bias=True)
(lin2): Linear(in_features=16, out_features=7, bias=True)
)
解析以上代码:
这段代码定义了一个简单的多层感知器(MLP),并基于给定的数据集初始化了它。以下是对代码的详细分析:
-
导入必要的库和模块:
import torch from torch.nn import Linear import torch.nn.functional as Ftorch: PyTorch库,用于张量计算和神经网络。Linear: 一个模块,表示全连接的线性层。F: 这是PyTorch中的功能模块,其中包含了ReLU和dropout等各种神经网络操作。
-
定义MLP类:
class MLP(torch.nn.Module):这个类继承了
torch.nn.Module,表示它是一个PyTorch模型。 -
构造函数 (
__init__):def __init__(self, hidden_channels): super().__init__() torch.manual_seed(12345) self.lin1 = Linear(dataset.num_features, hidden_channels) self.lin2 = Linear(hidden_channels, dataset.num_classes)hidden_channels: 这是MLP的隐藏层的大小。torch.manual_seed(12345): 设置随机种子以确保模型的权重初始化是可重复的。self.lin1和self.lin2: 定义了两个线性层。第一个线性层将输入特征映射到隐藏层,第二个线性层将隐藏层映射到输出层。
-
前向传播 (
forward方法):def forward(self, x): x = self.lin1(x) x = x.relu() x = F.dropout(x, p=0.5, training=self.training) x = self.lin2(x) return x- 输入
x首先通过lin1线性层。 - 然后应用ReLU激活函数。
- 接着应用了50%的dropout。Dropout是一种正则化技术,它在训练期间随机关闭一些神经元以防止过拟合。
- 最后,数据通过
lin2线性层。
- 输入
-
模型实例化:
model = MLP(hidden_channels=16)这里创建了一个新的MLP模型实例,其隐藏层大小为16。
-
打印模型:
print(model)当你打印模型时,PyTorch会显示模型的结构。对于这个特定的模型,输出如下:
MLP( (lin1): Linear(in_features=1433, out_features=16, bias=True) (lin2): Linear(in_features=16, out_features=7, bias=True) )这表示MLP有两个线性层。第一个线性层接受1433个特征作为输入,并输出16个隐藏通道。第二个线性层从16个隐藏通道接受输入并输出7个结果,这7个结果对应于数据集中的7个类别。
model = MLP(hidden_channels=16)
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4) # Define optimizer.
def train():
model.train()
optimizer.zero_grad() # Clear gradients.
out = model(data.x) # Perform a single forward pass.
loss = criterion(out[data.train_mask], data.y[data.train_mask]) # Compute the loss solely based on the training nodes.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
return loss
def test():
model.eval()
out = model(data.x)
pred = out.argmax(dim=1) # Use the class with highest probability.
test_correct = pred[data.test_mask] == data.y[data.test_mask] # Check against ground-truth labels.
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # Derive ratio of correct predictions.
return test_acc
for epoch in range(1, 201):
loss = train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
解析以上代码:
这段代码描述了使用多层感知器(MLP)在图数据上进行训练和测试的过程。以下是代码的详细分析:
-
模型初始化:
model = MLP(hidden_channels=16)这里创建了一个
MLP模型实例,其隐藏层大小为16。 -
损失函数定义:
criterion = torch.nn.CrossEntropyLoss()这定义了交叉熵损失函数,它在多分类任务中常用。
-
优化器定义:
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)使用Adam优化器来训练模型,学习率设置为0.01,同时应用了权重衰减,这有助于防止模型过拟合。
-
训练函数:
def train():这个函数定义了模型的训练步骤:
model.train(): 将模型设置为训练模式。optimizer.zero_grad(): 在每一次的训练迭代开始时清除梯度。out = model(data.x): 通过模型进行一次前向传播。loss = criterion(...): 仅基于训练节点计算损失。loss.backward(): 计算损失的梯度。optimizer.step(): 更新模型的参数。
-
测试函数:
def test():这个函数定义了测试步骤:
model.eval(): 将模型设置为评估模式,这意味着例如dropout和batch normalization等层会在推理模式下运行。pred = out.argmax(dim=1): 对每个节点的输出类概率取最大值,从而得到预测的类别。test_correct = ...: 检查预测值与真实标签是否相等。test_acc = ...: 计算正确预测的比率。
-
训练循环:
for epoch in range(1, 201): loss = train() print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')该循环进行200个训练周期。在每个周期中,模型在训练数据上进行一次训练,并打印出该周期的损失值。
总结:这段代码描述了如何使用一个简单的多层感知器来训练和评估图数据。它首先定义了模型、损失函数和优化器,然后通过训练和测试函数执行模型的训练和评估,最后在200个训练周期中训练模型。
Graph Neural Network (GNN)
将全连接层替换成GCN层
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
torch.manual_seed(1234567)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GCN(hidden_channels=16)
print(model)
输出如下:
GCN(
(conv1): GCNConv(1433, 16)
(conv2): GCNConv(16, 7)
)
解析以上代码:
这段代码描述了使用图卷积网络(GCN)模型在图数据上进行操作的定义。以下是代码的详细分析:
-
模型定义:
class GCN(torch.nn.Module):定义了一个基于
torch.nn.Module的GCN类,这意味着它是一个PyTorch的模型类。 -
构造函数初始化:
def __init__(self, hidden_channels):GCN的构造函数接受一个参数hidden_channels,它定义了隐藏层的大小。 -
层定义:
torch.manual_seed(1234567): 设置随机种子以确保实验的可重复性。self.conv1 = GCNConv(dataset.num_features, hidden_channels): 第一层是一个图卷积层,它将节点特征从原始特征大小(dataset.num_features,在这里是1433)转换为hidden_channels大小(在这里是16)。self.conv2 = GCNConv(hidden_channels, dataset.num_classes): 第二层将隐藏层的输出转换为类别数大小,这在本例中为7。
-
前向传播:
def forward(self, x, edge_index):定义了模型的前向传播过程:
x = self.conv1(x, edge_index): 通过第一层图卷积。x = x.relu(): 对输出应用ReLU激活函数。x = F.dropout(x, p=0.5, training=self.training): 应用dropout以防止过拟合,dropout率为0.5。x = self.conv2(x, edge_index): 通过第二层图卷积。
-
模型初始化:
model = GCN(hidden_channels=16)这行代码创建了一个
GCN模型实例,其隐藏层大小为16。 -
输出:
GCN( (conv1): GCNConv(1433, 16) (conv2): GCNConv(16, 7) )这是模型的打印输出。它显示了模型的两个图卷积层,第一层接受1433个特征并输出16个特征,而第二层接受这16个特征并输出7个类别。
总结:这段代码描述了一个基于图卷积的简单神经网络模型。它由两个图卷积层组成,其中第一个图卷积层负责特征转换,而第二个图卷积层产生最终的类别输出。这个模型为每个节点在图中生成一个类别输出,可以用于图中节点的分类任务。
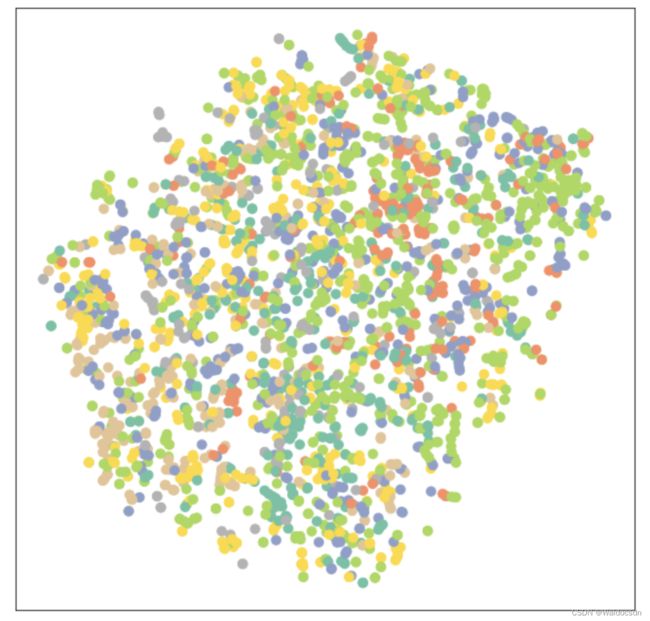
可视化时由于输出是7维向量,所以降维成2维进行展示
model = GCN(hidden_channels=16)
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
输出如下:
训练GCN模型
model = GCN(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
for epoch in range(1, 101):
loss = train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
解析以上代码:
这段代码实现了基于图数据的GCN模型的训练过程,同时还提供了测试函数来评估模型的性能。下面我会详细地解析这段代码:
-
模型初始化:
model = GCN(hidden_channels=16)这里创建了一个新的GCN模型实例,其中隐藏层的大小为16。
-
优化器初始化:
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)使用Adam优化器来更新模型的权重。学习率设置为0.01,权重衰减(用于正则化)为5e-4。
-
定义损失函数:
criterion = torch.nn.CrossEntropyLoss()选择交叉熵损失函数,这在多分类问题中是常用的。
-
定义训练函数:
model.train(): 设置模型为训练模式。optimizer.zero_grad(): 清除所有优化的梯度。out = model(data.x, data.edge_index): 使用模型进行前向传播。loss = criterion(...): 计算使用训练节点的损失。loss.backward(): 进行反向传播以计算梯度。optimizer.step(): 使用优化器更新模型参数。
-
定义测试函数:
model.eval(): 设置模型为评估模式。out = model(...): 进行前向传播。pred = out.argmax(dim=1): 对每个节点的输出获取最大值的索引,这代表预测的类别。test_correct = ...: 检查预测的类别是否与真实类别匹配。test_acc = ...: 计算测试集上的准确率。
-
训练循环:
for epoch in range(1, 101): loss = train() print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')对模型进行100轮的训练,并在每轮结束后打印当前的损失。
总之,这段代码描述了如何使用GCN模型、Adam优化器和交叉熵损失函数进行图数据的训练。定义了train和test两个函数来分别实现训练和测试的逻辑,并在主循环中进行了模型的训练。
# 准确率计算
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
输出如下:
Test Accuracy: 0.8150
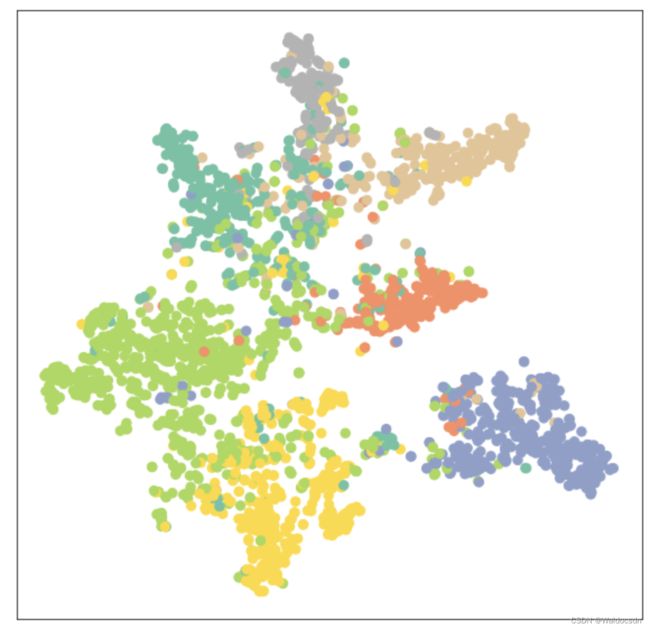
从59%到81%,这个提升还是蛮大的;训练后的可视化展示如下:
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
输出如下: