TensorFlow2实战-系列教程9:RNN文本分类1
TensorFlow2实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Jupyter Notebook中进行
本篇文章配套的代码资源已经上传
1、文本分类任务
1.1 文本分类
- 数据集构建:影评数据集进行情感分析(分类任务)
- 词向量模型:加载训练好的词向量或者自己去训练一个词向量模型都可以
- 序列网络模型:训练RNN模型进行识别

- 数据集构建实际上就是把文本转换为数字组成的向量,因为计算机是不认识文字的,它只认识数字,构建数据集的过程中就是对文本数据进行预处理。
- 词向量模型就是把词映射到向量
- 序列网络模型就是实例化一个模型,去训练出一个结果,用TensorFlow2版本是非常简单的,有很多现成的工具直接去调用
1.2 RNN文本分类
RNN模型所需数据解读: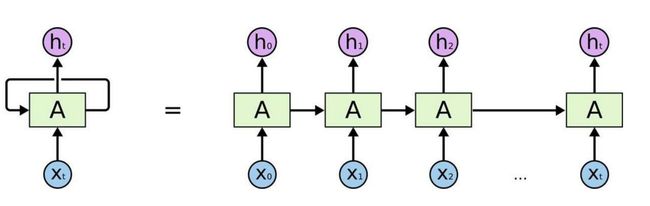
如图所示,RNN输入的是一个序列 X 0 X_0 X0、 X 1 X_1 X1、 X 2 X_2 X2、…、 X t X_t Xt对应的就是一个词解码的向量,一个词对应的向量可能是一个(1,300)的0-1之间的数值,也就是说 X 0 X_0 X0的维度就是(1,300)
RNN模型数据维度:[batch_size,max_length,word2vec]
batch_size:表示模型的输入批次大小
max_length:表示最大句子长度,因为必须安装最长的句子来算长度,短的可以填充0
word2vec:表示一个词对应的向量维度,这里就是300
2、数据介绍

如图所示,这是项目的训练数据,每一条数据就是一段电影的评语,而前面的数字就代表这个文本对应的分类类别,0/1两个类别的意义就是对电影的正面和负面评价。

其中,包含3个文件,train.txt是训练数据一共有25000条数据,test.txt是测试数据一共有25000条数据
3、加载项目数据
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
import numpy as np
import pprint
import logging
import time
from collections import Counter
from pathlib import Path
from tqdm import tqdm
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.imdb.load_data()
第一次执行这段代码,会进行下载:
Downloading data from
https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 2s 0us/step
imdb就是一个影评的数据集,一般下载后的路径会在这个路径中:
C:\Users\admin.keras\datasets
x_train.shape
打印一下shape值:
(25000,)
一共有25000条数据
x_train[0]
将第一条数据打印出来:
[1, 13, 586, 851, 14, 31, 60, 23, 2863, 2364, 314]
因为这里的数据是直接从TensorFlow的keras的datasets工具包中导入下载的,已经直接帮我们将词转换成索引了,也就是说前面的
[1, 13, 586, 851, 14, 31, 60, 23, 2863, 2364, 314]和这句话 i wouldn’t rent this one even on dollar rental night是等价的关系
def sort_by_len(x, y):
x, y = np.asarray(x), np.asarray(y)
idx = sorted(range(len(x)), key=lambda i: len(x[i]))
return x[idx], y[idx]
定义一个将文本数据按照文本长度大小进行排序的函数,最后返回排序后的数据和标签
x_train, y_train = sort_by_len(x_train, y_train)
x_test, y_test = sort_by_len(x_test, y_test)
def write_file(f_path, xs, ys):
with open(f_path, 'w',encoding='utf-8') as f:
for x, y in zip(xs, ys):
f.write(str(y)+'\t'+' '.join([idx2word[i] for i in x][1:])+'\n')
write_file('./data/train.txt', x_train, y_train)
write_file('./data/test.txt', x_test, y_test)
- 应用排序函数,对训练集进行排序
- 对验证集进行排序
- 定义一个将文本数据写入文件的函数
- 以写入模式打开文件
- 遍历 xs 和 ys 中的元素
- 将 y 和通过 idx2word 字典转换的 x 写入文件
- 使用 write_file 函数将处理后的训练集和测试集数据写入文件