完蛋! 我被MySQL索引失效包围了!
前言
一阵熟悉的起床闹钟响起,小菜同学醒来竟发现周围都是导致索引失效的原因:性感迷人的索引使用不当、可爱活泼的存储引擎无法识别索引列、刁蛮任性的优化器不选择索引...
知其然更要知其所以然,一起来看看索引为啥失效了吧~
在阅读文本前,需要知道聚簇索引、二级索引、回表等知识,如果同学不太了解可以去查看往期文章~
什么是索引失效呢?
对于MySQL常使用的索引来说,往往是聚簇索引和二级索引
索引失效指的是在某些场景下,MySQL不使用二级索引,而去使用聚簇索引(全表扫描),从而导致二级索引失效 (索引失效中的索引指的是二级索引)
不够熟悉索引导致使用不当
索引使用不当往往是因为我们不够了解索引
在聚簇索引中,记录按照主键值升序排序
在二级索引中,记录按照索引列、主键的顺序升序排序,当索引列相等时主键才有序

在(age,student_name)联合索引中,当age相等才对student_name排序,当student_name相等才对主键id排序
当我们熟悉索引存储规则之后,就可以有效避免索引使用不当的情况
比如 select * from student where student_name like 'c%' 是用不上(age,student_name)联合索引的
当查找的列不是有序的就可能会扫描整个二级索引,而这种情况下还可能要回表,因此MySQL会放弃使用二级索引,直接扫描聚簇索引,从而导致索引失效
当我们建立student_name索引后,上述SQL即可使用student_name二级索引
如果将SQL改为select * from student where student_name like '%c%' 也会导致无法使用索引
原因与上面说的类似,左模糊查询导致无法预估要扫描的区间,从而造成全表扫描
其他类似的场景还有order by、group by等需要排序场景,使用的二级索引不具备有序从而导致索引失效
当我们熟悉索引后一般场景下是不会犯这种索引使用不当的小错误~
存储引擎层导致索引失效
当执行器携带查询条件向存储引擎层请求数据时,如果存储引擎层无法识别数据也会导致无法使用索引
表达式
比如在查询条件中使用表达式 where age + 2 = 10
存储引擎层的innodb无法识别表达式时也会导致索引失效
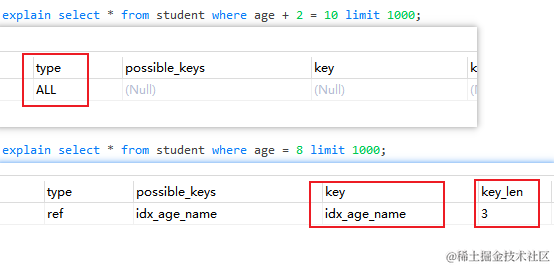
当然我们一般不会采取这种写法(key_len = 3说明只用到联合索引中的age)
函数
当我们对索引列使用函数时,存储引擎层也无法识别
比如 explain select * from student where age = '8' limit 1000 会隐式使用函数将'8'由字符串转换为整形8
等同于该SQL SELECT * FROM student WHERE age = CAST('8' AS UNSIGNED) LIMIT 1000 这种情况下是可以使用索引的
当对索引列age使用函数时如:SELECT * FROM student WHERE CAST(age AS CHAR) = '8' LIMIT 1000
存储引擎层无法识别CAST(age AS CHAR)导致无法使用age相关的索引
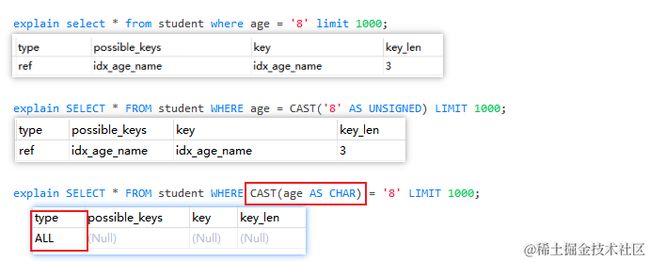
隐式使用函数进行类型转换也是容易导致索引失效的一种场景
即使字段类型相同也有可能发生隐式类型转换,比如 utf8(mb3) 向 utf8mb4 进行转换
在联表查询中,一般会为被驱动表的关联条件建立索引加速查询
select a2,b1 from a
left join b on a.a2 = b.b2比如在这个SQL中b为被驱动表,为关联条件需要的b2建立索引可以加快查询

正常情况下会使用索引(上图)
但是同样的SQL,你知道什么情况下会变成下图这样吗?

虽然用上了索引但没完全用上,还是使用了join buffer,从前后的key_len也可以知道没完全用上
原因就是当a2字段的字符集为uft8mb4、b2为utf8时,从驱动表a获取记录去被驱动表b中获取,b2字段隐式使用函数转换为utf8mb4导致存储引擎无法识别
菜菜就因为这种情况在本地没问题,结果生产上字符集不同导致索引失效
Server层导致索引失效
另一种索引失效的场景发生在server层:当优化器认为使用该索引成本太大则会偏向使用全表扫描
回表太多
那么啥情况会让优化器认为使用二级索引成本大呢?
使用二级索引时往往是需要回表导致成本大
因为回表不止需要多查询一个聚簇索引,由于二级索引的主键值可能无序查询聚簇索引时还会导致随机IO
回表成本大的场景一般发生在查询数据量较大的情况下,因为回表的数据增多成本也就变大
MySQL认为使用二级索引成本太大从而导致索引失效
比如or、is null、is not null等查询条件并不一定会导致索引失效,当MySQL预估它们的数据量太大回表开销太高时才会放弃使用二级索引
又或者是深分页问题 limit 10000000,10,由于MySQL要在server层进行limit,那就会导致先查前一千万条数据,而使用查的数据量太大,如果需要回表成本就会非常高,从而导致深分页问题的索引失效
估算误差用错索引
当MySQL估算成本估算错误时也可能导致索引失效
当需要扫描的记录数量超过一定限制(show variables like 'eq_range_index_dive_limit')时,会使用统计的方式预估成本容易有误差(空闲时使用analyze table 重新统计cardinality)
cardinality用于判断重复值,越小说明重复值越多,如果重复值太多(cardinality太小),也会让MySQL不偏向使用索引
总结
索引失效大致分为3种场景:索引使用不当、存储引擎层导致索引失效、Server层导致索引失效
不熟悉索引存储规则,在使用时就容易造成索引使用不当,如:左模糊匹配、联合索引最左匹配原则、order by、group by排序等
当存储引擎层无法识别查询条件中的索引列时会导致索引失效,如:索引列使用表达式、显示/隐式使用函数等
当Server层优化器认为使用二级索引成本太大时会导致索引失效,成本的主要来源是回表,回表数据量太大就会导致成本高而不偏向使用索引,如深分页问题等(重复值太多也会导致不偏向使用索引)
当需要扫描的记录数量超过一定限制,使用统计预估成本会造成误差,误差过大也会造成索引失效
最后(不要白嫖,一键三连求求拉~)
小菜同学熟悉各种场景导致的索引失效后,准备将周围的索引失效场景一一攻略
一阵熟悉的起床闹钟响起,小菜同学满头大汗的爬起:原来只是一场梦,还好项目里没有这么多索引失效的场景
本篇文章被收入专栏 由点到线,由线到面,构建MySQL知识体系,感兴趣的同学可以持续关注喔
本篇文章笔记以及案例被收入 gitee-StudyJava、 github-StudyJava 感兴趣的同学可以stat下持续关注喔~
有什么问题可以在评论区交流,如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
关注菜菜,分享更多干货,公众号:菜菜的后端私房菜
本文由博客一文多发平台 OpenWrite 发布!