论文阅读,Domain Specific ML Prefetcher for Accelerating Graph Analytics(一)
目录
一、Article:文献出处(方便再次搜索)
(1)作者
(2)文献题目
(3)文献时间
(4)引用
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
(2)目的
(3)预置知识
(4)主要实现手段
4.1 overview
4.2 MPGraph的工作流程
4.3 阶段转换检测器 Phase Transition Detector
4.4 多模态访存预测器Phase-Specific Multi-Modality Predictors
4.5 链式时空预取策略
(5)实验结果
5.1 实验设置
5.2 Phase Transition Detection评估
5.3 Multi-Modality Predictors 评估
5.4 预取评估
5.5 实际应用
(6)问题记录
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
四、Why:为什么看这篇文献 (方便再次搜索)
五、Summary:文献方向归纳 (方便分类管理)
一、Article:文献出处(方便再次搜索)
(1)作者
- Pengmiao Zhang,Viktor K. Prasanna (南加州大学)
- Rajgopal Kannan(DEVCOM Army Research Lab)
(2)文献题目
-
Phases, Modalities, Spatial and Temporal Locality: Domain Specific ML Prefetcher for Accelerating Graph Analytics
(3)文献时间
- International Conference for High Performance Computing, Networking, Storage and Analysis (SC2023)
(4)引用
-
Pengmiao Zhang, Rajgopal Kannan, and Viktor K. Prasanna. 2023. Phases, Modalities, Spatial and Temporal Locality: Domain Specific ML Prefetcher for Accelerating Graph Analytics. In The International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’23), November 12–17, 2023, Denver, CO, USA. ACM, New York, NY, USA, 13 pages. https: //doi.org/10.1145/3581784.3607043
二、Data:文献数据(总结归纳,方便理解)
(1)背景介绍
- 图分析被广泛用于分析图中的复杂结构关系。然而,the enormous size of Big Data graphs and attendant complexity of the analytics algorithms 往往导致性能下降,因为内存利用效率低(低数据重用率,高缓存缺失率等);
- 在图分析应用中,主要有2种预取技术,一种是传统的基于规则的预取器,它的硬件实现较为简单性,具有一定的性能加速效果,但受限于adaptablity,无法处理图分析中复杂的内存访问模式。相比之下,基于机器学习算法的预取器展现出高度的adaptablity和generalization(用于内存访问预测和预取)。
(2)目的
- 因为图分析具有自身独特的特点(复杂的内存访问模式,随机性和不规则性,多页存储的节点处理等等),所以特定领域的上下文非常重要(特定领域的上下文可以作为先验知识输入到ML模型中,提高模型的性能),作者通过分析目标硬件的架构上下文和目标应用程序的计算上下文来将先验知识集成到ML模型中;
- 此外,图分析领域非常重要,开发高性能的数据预取器势在必行,但据作者所知,目前并不存在这种特定于领域的ML预取器。
(3)预置知识
预取的特定领域特征:
Context of architecture
- 平台:执行计算的目标架构,例如多核平台、多CPU集群、异构架构等。
- 内存层次结构:每个缓存级别、主内存、持久内存、闪存等的参数。
- 内存地址配置:内存地址的位长度、缓存行大小、页面大小等。
Contex of Computation
- 计算范式:特定应用程序所遵循的编程模型,例如图分析中的MapReduce、Scatter-Gather和GAS。
- 阶段:领域计算中的一个step或super step,例如分布式计算范式中的本地计算步骤和值通信步骤。
- 模态:用于描述计算的一种模式或一组特征。对于内存访问,模态包括程序计数器、内存地址、线程ID等。
- 局部性:计算中的数据访问模式,如空间局部性和时间局部性。
- 线程:进程内的执行单元。多个线程可以在多核CPU上并行运行并共享相同的内存空间,这对于内存访问预测是一个挑战。
- 协调:并行计算应用程序定义多个核心或系统节点如何协同工作的方式,包括同步和异步协调。
(4)主要实现手段
4.1 overview
在体系结构的上下文中,目标平台是一个多核共享内存体系结构,如图1所示,它可以作为HPC的一个节点。内存层次结构由私有L1缓存(包括数据缓存L1D和指令缓存L1I)、私有L2缓存、共享末级缓存(LLC)和共享主存组成。这导致了来自于来自不同核心的交错指令的LLC数据请求。作者考虑了系统的内存地址配置,预取在块级别,虚实地址转换在页面级别。在此基础上,训练了数据预取的页面和块索引预测模型。
在计算的上下文中,文中提到了使用各种计算范式的图处理框架,如MapReduce、Scatter-Gather和GAS(Gather-Apply-Scatter),作者的目标是针对具有迭代屏障同步阶段的图分析框架进行优化。作者以GPOP框架为例,展示了如何将领域特定的特征应用于领域特定的ML模型。GPOP是一个基于Scatter-Gather范式的图分析框架,该框架由两个阶段组成:Scatter和Gather。其中,Scatter阶段将当前顶点的值沿边传播到其邻居顶点,而Gather阶段则累积来自邻居顶点的值来更新顶点的值。作者在模型开发中特别考虑了领域特定的特征,如阶段、模态和局部性(phase, modality, and locality)。简单来说:
-
阶段的纳入:
- 作者通过分析Connected Component和PageRank应用程序在GPOP框架中的内存访问序列,并进行主成分分析(PCA)。
- PCA的结果显示了不同阶段之间和同一阶段内的内存访问模式的多样性。
- 由于每个阶段内的模式数量不固定,但阶段数量较少且恒定,因此作者决定为每个阶段训练一个单独的模型,以提高内存访问预测性能。
- 此外,作者观察到不同阶段的PC形成簇状,表明可以使用PC来检测阶段转换。

-
模态的纳入:
- 多线程应用程序的并行执行导致指令交错和内存访问的高度不规则性。
- 例如,GPOP在每个核心上并行地处理输入图的分区,内存地址序列不能完全揭示这一特征。
- 相反,从指令的角度来看,多线程进程具有多个PC,每个指向给定线程的下一条要执行的指令。
- 因此,作者将PC序列视为与地址序列同等重要的输入模态,并开发了一个多模态网络来融合这两个输入,以进行内存访问预测。
-
局部性的纳入:
- 大规模图处理往往涉及对存储在不同内存页中的图节点进行高度不规则的内存访问。例如,在GPOP的案例中,存在频繁大量的内存访问页面跳转。
- 作者除了预测空间局部性后的delta外,还预测内存访问页面。考虑到图处理是迭代的,作者遵循时间局部性来预测页面。

4.2 MPGraph的工作流程
MPGraph的整体设计和工作流程如下图所示:

预取过程从一个阶段转换检测器开始,该检测器读取PC序列并检测阶段转换(详见第4.3节,阶段转换检测器)。对于每个阶段,都有特定于该阶段的多模态预测器,用于空间增量预测和时间页预测,这两者都使用地址序列和PC序列作为输入的两种模态(详见第4.4节,多模态访存预测器)。为了选择特定于阶段的预测器并管理增量和页预测,作者开发了一个预取控制器,该控制器采用一种新颖的链式时空预取策略并生成预取请求(详见第4.5节,链式时空预取策略)。这些模型将用于执行内存访问预测和预取,以改进每个周期的指令(IPC)。
4.3 阶段转换检测器 Phase Transition Detector
阶段是由软件定义的,提取阶段标签需要访问源代码和软件接口。基于这一考虑,作者根据阶段标签的可访问性,为两种情况开发了阶段转换检测器。
4.3.1 Phase label Inaccessible.
在无法访问到阶段标签的情况下,使用无监督学习模型来检测阶段转换。

这里将阶段转换描述为机器学习环境中的概念漂移(concept drift),当模型学到的模式不再成立时,就会发生概念漂移,如果要对概念漂移下定义的话,概念漂移是一种现象,即目标领域的统计属性随着时间的推移以一种任意的方式变化。
Kolmogorov–Smirnov Windowing (KSWIN) 是一种最先进的数据流概念漂移检测模型。它是基于两个样本柯尔莫戈罗夫-Smirnov(K-S)检验,它估计了从相同的分布中抽取两组样本的概率。KSWIN通过比较两个窗口的分布来检测概念漂移:一个包含ℎ历史样本,另一个包含最近的样本。显著性水平决定了KSWIN模型中漂移检测的阈值,其选择也至关重要。该模型对的选择非常敏感。值越大可能会增加假阳性检测率,而值越小可能会导致模型检测漂移失败。
Kolmogorov-Smirnov检验(KS检验):
1.基本原理: KS检验的基本原理是比较观察到的数据分布(经验分布函数)与理论分布(通常是正态分布或其他特定分布)的累积分布函数(CDF)之间的最大差异。KS检验使用了样本中的最大绝对偏差(最大的绝对差异),该偏差被称为KS统计量。
2. 用途:主要用途是检验一个样本的分布是否与一个已知的理论分布相符。它通常用于整体拟合度检验,即确定样本是否来自某个特定的分布。Eg:你可以使用KS检验来检查一个数据集是否符合正态分布。如果KS检验的p值低于显著性水平,那么我们不能拒绝样本与理论分布相符的原假设。
计算方法参考链接:Kolmogorov-Smirnov test (K-S 检验) - 知乎 (zhihu.com)
需要注意的是,这种“硬”检测过程忽略了阶段内部脉冲模式的变化,可能导致误报检测。(这个没明白,如下图所示)

Soft-KSWIN,它是KSWIN的一个特定领域变体,专门用于检测图处理阶段转换。它利用领域知识,即phase在数百万条指令内是稳定的,以避免误报。Soft-KSWIN算法通过使用从动态历史数据点集中采样的软历史窗口'来设计软检测过程,如图5(b)所示,算法流程如下。

4.3.2 Phase label Accessible.
处理阶段可以使用源代码、程序员注释和Intel Pin]等仪器工具进行离线标记。然后,可以使用PC trace和phase标签来训练一个有监督的模型。常用的2种方法:
- Decision Tree (DT):使用简单的决策树分类器来根据PC跟踪序列预测当前处理阶段。当两个连续的预测结果不同时,我们检测到一个阶段转换。
- Soft Decision Tree (Soft-DT):观察到当决策树在预测不同阶段时立即报告阶段转换时,可能会产生误报。这包括阶段内的短期模式变化和错误的预测。为了降低误报率,使用类似于第4.2.1节的软检测方法。我们将过去的阶段推理结果存储在结果队列中,并比较其头部和尾部一半的模式(列表中最频繁出现的元素)。当两个模式不同时,我们报告一个转换检测,以避免突发的模式变化。
4.4 多模态访存预测器Phase-Specific Multi-Modality Predictors
为了预测图处理的每个阶段,作者训练了特定于阶段的预测器。为了充分利用空间和时间的局部性,作者设计了两个领域特定的模型:空间增量预测器和时间页预测器。为了实现这些预测器,我们开发了一个名为AMMA的基于注意力机制的网络,用于提取特征。注意力机制在预测中具有高适应性,并且在实现中具有高并行性。
4.4.1 预测器训练和推理的工作流程

MPGraph中的预测器被离线训练,然后部署起来进行在线推理。简而言之,MPGraph预测器的训练和推断的工作流程如下:首先,通过监视应用程序对共享最后一级缓存的访问来提取内存访问trace。然后,使用提取的trace数据,设置扫描窗口来获取过去的访问和未来的访问标签。接下来,使用这些标签和内存访问trace数据,离线训练特定于阶段的模型。最后,将训练好的模型部署到MPGraph预取器中,以加速应用程序的未来执行。
4.4.2 AMMA
由三种基于注意的层组成:自注意层、多模态注意融合层和变压器层。(简单来说,其实就是Transformer的流程)




空间增量预测器:图7(a) 展示了空间增量预测器的模型。它使用地址序列和PC序列作为输入,其中AMMA作为backbone特征提取器,而多层感知器(MLP)作为分类头部,使用Sigmoid函数。输入预处理使用地址分段方法将输入内存地址划分为一系列段,以便ML模型能够处理,并避免对地址空间(数百万级别)进行标记化处理。PC被哈希和归一化以供模型处理。模型预测空间范围内(即1页大小)的多个未来增量,当前地址与预测增量之和是未来访问的预测值。模型使用未来增量的标签进行训练,以多标签分类的形式表示,使用二元交叉熵作为损失函数。
时间页预测器:图7(b)展示了时间页预测器的模型。它以内存地址的页面部分作为一个模态,并使用PC作为另一个模态。AMMA作为特征提取器,MLP使用Softmax激活函数作为分类头部。输入的页面序列被标记化,因为其词汇表较小(数千个),可以被ML模型处理。模型输出下一个未来页的概率,由Softmax函数确定。模型使用未来页标记作为标签进行训练,使用分类交叉熵作为损失函数。
这两个预测器都使用AMMA作为特征提取器,并使用MLP作为分类头部,训练过程分别使用未来增量和未来页作为标签。
4.5 链式时空预取策略
预取控制器的两个功能:切换特定阶段的预测器(Phase-Specific Multi-Modality Predictors)和指定预取请求。同时,介绍了一种称为Chain Spatio-Temporal Prefetching (CSTP)的新策略来确定预取内容。
- 切换预测器:预取控制器从阶段转换检测器接收信号。一旦检测到转换,它会激活所有个阶段特定的预测器以并行工作。控制器随后监视这些预测器在少量访问中的性能,并选择表现最好的预测器。
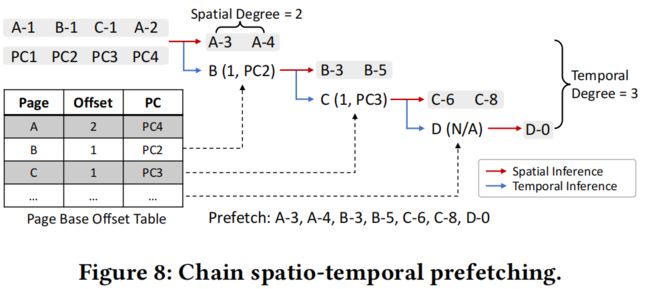
- Chain Spatio-Temporal Prefetching (CSTP):图8说明了CSTP策略。给定一个以"页面偏移"表示的内存块地址的输入序列和一个PC序列(例如,A-1表示页面A的偏移1),空间增量预测器和时间页预测器并行工作。一个页面基准偏移表(PBOT)记录了过去页面的最新偏移和PC。对于一个预测的页面,可以从PBOT中检索到最新的偏移和PC,进行进一步的空间和时间推断。这个过程以链式方式继续,直到达到时间度或者PBOT中缺少页面偏移。给定空间度和时间度,总的预取度范围为: + 1 ≤ ≤ ( + 1)。
(5)实验结果
5.1 实验设置
benchmark:使用三种流行的图形处理框架来评估MPGraph: GPOP、XPStream 和 PowerGraph 。使用该框架的内置应用程序进行评估,包括:Breadth-First Search (BFS), Connected Components (CC), PageRank (PR), Single Source Shortest Path (SSSP), and Triangle Counting (TC),见表1。

dataset:使用6个真实世界的图数据集和一个基于R-MAT的随机生成的合成图来评估MPGraph和baseline,如表2所示。

simulator:使用ChampSim 行物理地址的trace生成和预取器评估。模拟器参数详见表3。需要注意的是,虽然实验中的图形数据集可以存储在DRAM中,但它们不适合LLC。

trace generation:使用Intel Pin工具从运行在4个核心上的基准应用程序中提取指令trace。然后,使用ChampSim工具从共享的最后一级缓存(LLC)中提取内存访问trace。对于模型的训练,使用来自框架计算的第一次迭代的追踪trace。对于模型的测试和预取仿真,使用接下来的10次迭代的追踪trace。
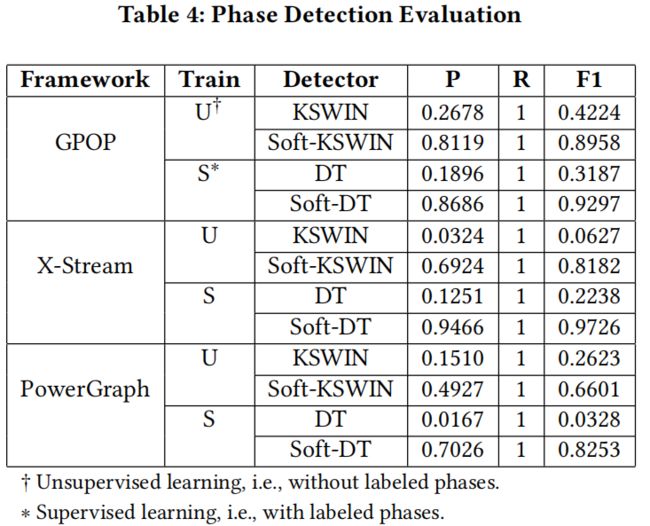
5.2 Phase Transition Detection评估

5.3 Multi-Modality Predictors 评估

表6和表7展示了空间增量预测和时间页面预测性能。在空间增量预测方面,AMMA-PS在所有应用程序中展现出最高的F1分数,相比于LSTM,性能提升了11.15%到24.01%,相比于Attention,性能提升了4.52%到11.83%,相比于AMMA,性能提升了2.46%到5.9%,相比于AMMA-PI,性能提升了1.79%到5.2%。
在时间页面预测方面,AMMA-PS同样展现出最佳的accuracy@10性能,相比于LSTM,性能提升了8.23%到25.5%,相比于Attention,性能提升了4.67%到22.6%,相比于AMMA,性能提升了2.03%到21.15%,相比于AMMA-PI,性能提升了1.36%到21.24%。
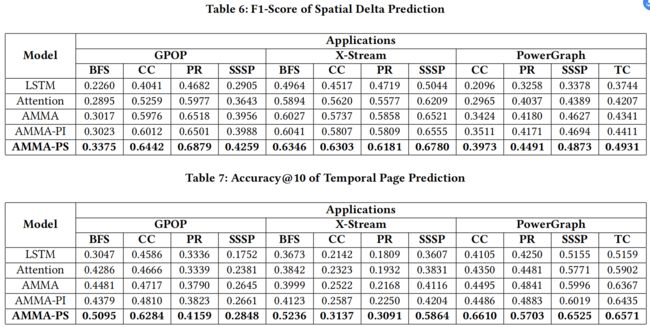
由于每个阶段中存在独特的时间模式,相较于其他模型,针对具体阶段的模型在页面预测方面表现得更加优越。
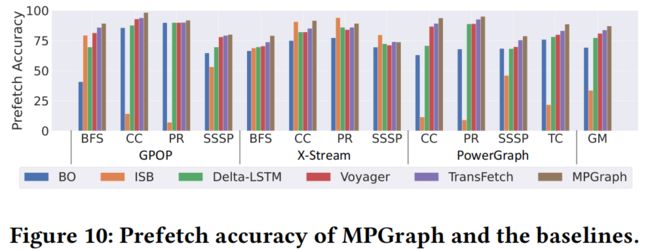
5.4 预取评估
- Best-Offset prefetcher (BO):基于规则的空间预取器,用于预测页面内的增量模式。
- Irregular Stream Buffer (ISB):基于规则的时序预取器,基于record和replay来进行预取。
- Delta-LSTM:使用增量输入和增量输出的基于机器学习的预取器。
- Voyager:使用地址和PC作为输入,利用两个基于LSTM的模型来对下一个页面和偏移进行时间上的预测的基于机器学习的预取器。
- TransFetch:使用地址和PC作为输入,利用基于注意力机制的模型在页面范围之外预测空间增量的基于机器学习的预取器。


5.5 实际应用
1. 二进制编码(Binary Encoding):使用二进制编码压缩来减少时间页面预测器的词汇表和输出维度。通过用一个16维的二进制向量表示2^16个类(页面标记),可以将模型的输出维度减少到16,输入标记的词汇表减少到2。这样,在表5中具有2^16个类的模型中,可以将参数从13M减少到397K,达到高达33倍的压缩比。可以进一步使用知识蒸馏(Knowledge Distillation)进行模型的压缩。
2. 知识蒸馏(Knowledge Distillation):知识蒸馏是指将大型教师模型的知识传递给较小的学生模型。通过调整表5中描述的AMMA配置并将其作为学生模型进行训练,可以将空间预测器的大小从419.6K减少到7.5K参数,将时间预测器的大小从397K减少到1.9K参数,实现了总体上的87倍压缩。当压缩模型时,图13显示知识蒸馏显著提高了模型性能。通过使用个特定阶段的教师模型训练单个学生模型,可以进一步将预测器压缩倍(每次迭代的阶段数)。虽然压缩会导致性能下降,但与最佳的非机器学习预取器BO相比,MPGraph仍然显示出比其更高的IPC改进(5.47%)。
3. 量化(Quantization):通过使用8位表示模型中的权重,并应用上述优化方法,可以将空间模型的存储成本减少到7.5KB,将时间模型的存储成本减少到1.9KB。通过执行此优化,我们的模型的需求与基准规则型预取器(如BO的4KB存储)和ISB(8KB存储)相似。

1. 并行实现(Parallel Implementation):神经网络的硬件加速已经得到广泛研究。MPGraph基于注意力机制,该机制可以高度并行化。通过完全并行化AMMA模型的实现,可以使用基于图7的关键路径估算延迟。

公式(12)中的各项表示不同部分的计算时间,包括嵌入层、自注意力层、多模态注意力融合层、Transformer层、输入处理和输出层等。假设完全并行,可以估计整体延迟。对于原始模型(=128),整体延迟估计约为123个处理器周期,对于压缩模型(=8),整体延迟估计约为79个处理器周期。
2. 查找表近似(Approximation as a Look-Up Table):通过使用查找表(Look-Up Tables,LUT)来加速模型推理过程,避免复杂的计算。最近的研究已经探索了使用查找表来近似矩阵乘法和激活函数,以及使用基于查找表的内存中处理方法来加速神经网络推理。通过实现基于层的查找表,对于图7中具有融合层和Transformer层内的两个子层的模型,模型推理延迟可以减少到约8个周期,而不考虑模型的维度。
3. 距离预取(Distance Prefetching):除了减少内存访问预测模型的推理延迟外,距离预取提供了一种通过跳过推理槽位并预测未来的内存访问来隐藏或抵消延迟的替代方法。图14显示,距离预取(DP)有效地避免了由于模型推理延迟引起的性能损失。在模拟过程中引入200个周期的延迟后,未压缩的和87倍压缩的MPGraph相对于BO分别提高了8.77%和3.58%的IPC改进。

(6)问题记录
基于机器学习的模型,没有说明超参数是如何设置的?
特定领域的特征是如何选取的?文中提到包括:compuation和architecture的上下文特征。
作者的目标是针对具有迭代屏障同步阶段的图分析框架进行优化,但是没有说为啥,conclusion中又提到文中的方法可以拓展到异步框架的每个线程?(菜菜懵懵)
三、Comments对文献的想法 (强迫自己思考,结合自己的学科)
简而言之,这篇论文提出了一种基于机器学习的图分析预取器MPGraph,它利用领域特定的模型和策略来提高性能。该方法可以应用于异步框架和图机器学习等领域,并具有扩展到其他场景的潜力。行文流畅,逻辑严密,让我这个小白也能较快的读下来。但是读下来脑子里只有一个大概模糊的轮廓,这篇论文的工作量还是很大的,有大量的实验评估。
四、Why:为什么看这篇文献 (方便再次搜索)
任务需要
五、Summary:文献方向归纳 (方便分类管理)
数据预取 ML Prefetcher
- Domain Specific
-
Accelerating Graph Analytics
-
Phases, Modalities, Spatial and Temporal Locality