蓝桥杯训练1
1 找哪个深度的节点权值最大

暴力
#includedfs
从根节点开始遍历,遍历途中记录每层的值,然后要注意权值可为负数并且数组越界的情况
#include2.外卖店优先级

这题用vector数组会舒服清晰很多(同样能够sort排序),然后对每一家店进行判断,判断过程非常容易出错!首先怎么选择开始是个问题,我这里选择i=1开始,以外卖店now=2开局(如果只有一个订单不会执行循环,后续代码也能解决),然后每次把间隔时间求出来,now减去这个时间,当对now进行减操作,立即判断有没有踢出队列,最后加操作的时候也是立即判断有没有加入队列。最后就是把t减去最后的订单时间判定要不要T。总之,这题思路不清晰就非常容易出错
#include3.修改数组

思路是用并查集,一开始所有结点的父亲都设为自己,要保持的是,父亲节点的值代表没有出现过的值。
然后对输入的数组进行遍历,每做一次遍历,先让该值等于父亲结点的值,更新完之后,令这个节点的父亲的值进行加1.也就是这个节点的父亲的值被取了之后,要对其进行更新
总结一下:每次更新完一个结点后,他输出的值必定是他父亲的值,这个父亲的值之前没有被用过,但是现在被用了,就要+1,虽然+1不能保证+1的后的结果也未使用,但是即使被使用(f[i]!=i),下次遇到相同的x,通过find(x),能够找到祖先,这个祖先是一定未被使用的
#include4.糖果(状态压缩+dp)

状态压缩很好理解,dp这一块我看别人看了好久才弄懂,还是菜0.0,本质上是用已有的状态进行排列组合。
#include5.全球变暖dfs
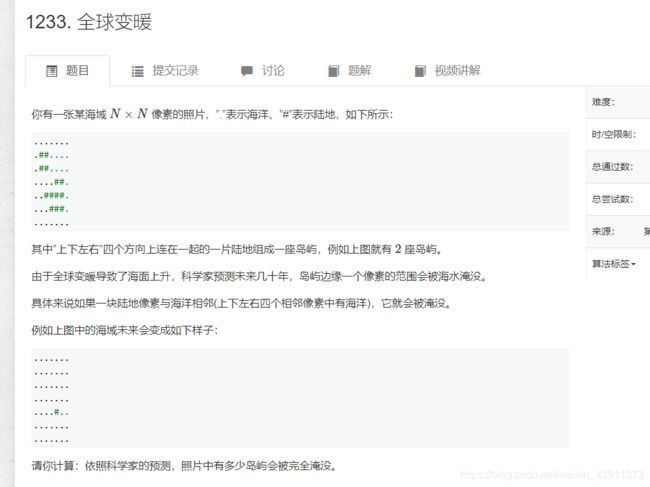
首先题目给的数据应该是外面一圈全是海,我是依照这个标准来写的。还有一块岛屿可能变化后会成为两块小岛,但是按照题目的意思好像它们还是算一块。所以我用a数组来记录岛屿的情况。每遇到一块未访问的陆地,就dfs遍历该陆地的整个连通分量,如果遇到符合情况的陆地,将该数组标记为1,即便遇到多块,还是1(根据题意以及样例)。最后连通分量数减去数组中为1的个数就是消失的岛屿数目
#include6.倍数问题
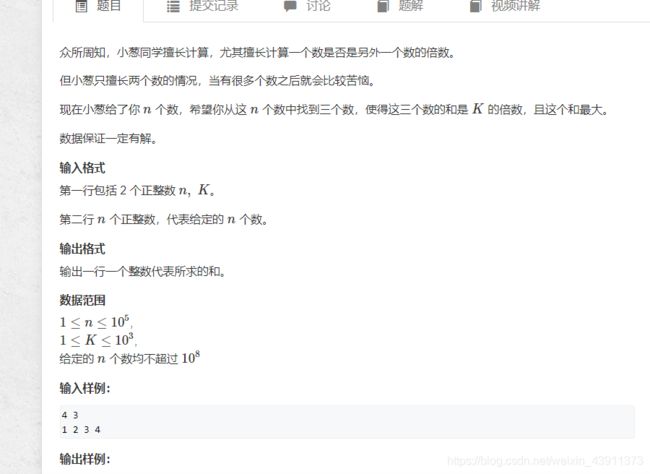
法一(dfs->tle)套用组合数的板子,n=1000的时候就T了
#include7.付账问题

主要思路就是贪心,先排序,从最小的开始,如果最小的都能付,那么结果是是0。否则,当前面的少付,后面就要多付,后面的平均值就会提高,要让它们的值尽量接近这个变化的平均值。
我这里用了两个数组,我看了别人的,更简单的可以边判断边计算方差,如果不够就是avg-a[i],如果够了就是avg-curavg。
#include8.迷宫(标记dfs)

分别测试这100个点即可,每次测试后要情况要把数据清空。这题本来不想记的,UDLR的时候我判断错了,i是行坐标判断上下而且U应该是-1,没想到自己会错在这个地方
#include9.跳蚱蜢(bfs+set判重)

这题判断最小步数我居然没想到bfs,判断最优解一定是BFS!!第一次用set集合来判重,然后判断的时候犯了一个大忌,直接把出队的节点进行修改,正确做法应该是赋值给另外一个节点再做操作。
#include9.方格分割

从中间左边(3,3)开始往两边同时dfs,然后遇到边就结束,ans++。可以验证,图中有4个方向dfs导致的结果是一样的,所以最后ans/=4.
这题我一开始认为要走到底角才结束,判定走到一个角才停止dfs。属实白痴,这样算出来的会多多于结果,因为相同的图案可能有多种走到同一个角的方式。
#include10.方格问题(递归)

遇到左括号就一层dfs,并把结果返回给当前的记录值,遇到或和右括号就判断当前最大值。最后while循环结束时候不能忘记再算一遍最大值。
#include11.包子凑数

首先如果公约数不为1,直接INF。否则,进行递推,对每个点都加上数组里边的数进行标记,标记到了就是可访问的。若a,b互素,ax+by=c,若x,y>0,无解的C中最大取a*b-a-b,所以这里数组开1w。然后为了在遍历中防止越界还要记得加限定条件。
#include12.分巧克力(二分)

涉及到整数的二分,为了避免死循环,可以使用该模板
while l
if l=mid
else r=mid-1
#include下面这种方式也行,思路不一样
首先r-l>1已经避免死循环,其次,r=mid的情况仅当mid非正解,所以r永远不能取。反观l,l仅当mid为解才能取,while结束之后,l的值就是答案,而r的值不是答案。
while(r-l>1){
mid=(r+l)>>1;
if(f(mid))l=mid;
else r=mid;
}
13.方格填数(暴力+next_permutation)

#include14.寒假作业

用全排列会T。转而用dfs,过程中要注意两点,一点是剪枝的时候要加上step判定,另外就是结尾的除法转换成乘法,除法太容易错!
#include15.剪邮票(双重dfs)

思路是先用dfs求出组合数,然后把组合数映射到二维数组里求连通分量个数。卡了很久的一道题,值得一刷。我在solve里面的双重for循环用了break退出导致错误,应该用return。
而且貌似求连通分量个数的dfs跟一般的dfs不一样,前者不需要还原状态,只需要进行清除标记即可。
#include16.四平方和

思路:一开始就是枚举,4层for循环,然后可以用n/4,n/2等等优化,没什么用,铁T。随后可以用三层for循环,最后一层进行计算,还是T。最后用的是哈希的思想,把c,d的平方和存起来,然后用map的find函数找,优化很多,但是由于find函数是on,所以还是t。最后把map改成数组就能过了!
#include