opencv学习 特征提取
内容来源于《opencv4应用开发入门、进阶与工程化实践》
图像金字塔
略
拉普拉斯金字塔
对输入图像进行reduce操作会生成不同分辨率的图像,对这些图像进行expand操作,然后使用reduce减去expand之后的结果,就会得到拉普拉斯金字塔图像。
详情可查看https://zhuanlan.zhihu.com/p/80362140
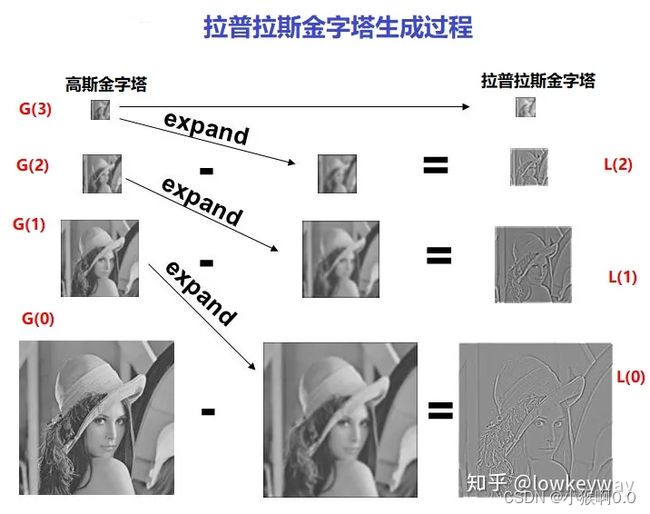
图像金字塔融合
拉普拉斯金字塔通过源图像减去先缩小再放大的图像构成,保留的是残差,为图像还原做准备。
根据拉普拉斯金字塔的定义可以知道,拉普拉斯金字塔的每一层都是一个高斯差分图像。:
原图 = 拉普拉斯金字塔图L0层 + expand(高斯金字塔G1层),也就是说,可以基于低分辨率的图像与它的高斯差分图像,重建生成一个高分辨率的图像。
详情参考https://zhuanlan.zhihu.com/p/454085730的图像融合部分,讲的很好。
步骤:
- 生成苹果、橘子的高斯金字塔
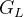 和
和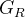
- 求苹果、橘子的的拉普拉斯金字塔
 和
和
- 求mask的高斯金字塔

- 在每个尺度(分辨率)下,用拼接和,最终得到拼接的拉普拉斯金字塔
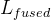
- 生成最低分辨率的起始图(都选取最低分辨率下的和 根据同分辨率下 进行拼接,得到最低分辨率下的拼接结果

- 从开始,利用得到最高分辨率的拼接结果
示例代码:
int level = 3;
Mat smallestLevel;
Mat blend(Mat &a, Mat &b, Mat &m) {
int width = a.cols;
int height = a.rows;
Mat dst = Mat::zeros(a.size(), a.type());
Vec3b rgb1;
Vec3b rgb2;
int r1 = 0, g1 = 0, b1 = 0;
int r2 = 0, g2 = 0, b2 = 0;
int red = 0, green = 0, blue = 0;
int w = 0;
float w1 = 0, w2 = 0;
for (int row = 0; row(row, col);
rgb2 = b.at(row, col);
w = m.at(row, col);
w2 = w / 255.0f;
w1 = 1.0f - w2;
b1 = rgb1[0] & 0xff;
g1 = rgb1[1] & 0xff;
r1 = rgb1[2] & 0xff;
b2 = rgb2[0] & 0xff;
g2 = rgb2[1] & 0xff;
r2 = rgb2[2] & 0xff;
red = (int)(r1*w1 + r2*w2);
green = (int)(g1*w1 + g2*w2);
blue = (int)(b1*w1 + b2*w2);
// output
dst.at(row, col)[0] = blue;
dst.at(row, col)[1] = green;
dst.at(row, col)[2] = red;
}
}
return dst;
}
vector buildGaussianPyramid(Mat &image) {
vector pyramid;
Mat copy = image.clone();
pyramid.push_back(image.clone());
Mat dst;
for (int i = 0; i buildLapacianPyramid(Mat &image) {
vector lp;
Mat temp;
Mat copy = image.clone();
Mat dst;
for (int i = 0; i la = buildLapacianPyramid(apple);
Mat leftsmallestLevel;
smallestLevel.copyTo(leftsmallestLevel);
vector lb = buildLapacianPyramid(orange);
Mat rightsmallestLevel;
smallestLevel.copyTo(rightsmallestLevel);
Mat mask;
cvtColor(mc, mask, COLOR_BGR2GRAY);
vector maskPyramid = buildGaussianPyramid(mask);
Mat samllmask;
smallestLevel.copyTo(samllmask);
Mat currentImage = blend(leftsmallestLevel, rightsmallestLevel, samllmask);
imwrite("D:/samll.png", currentImage);
// 重建拉普拉斯金字塔
vector ls;
for (int i = 0; i= 0; i--) {
pyrUp(currentImage, temp, ls[i].size());
add(temp, ls[i], currentImage);
}
imshow("高斯金子图像融合重建-图像", currentImage);
}
Harris角点检测
角点是图像中亮度变化最强的地方,反映了图像的本质特征。
图像的角点在各个方向上都有很强的梯度变化。
亚像素级别的角点检测
详细请参考https://www.cnblogs.com/qq21497936/p/13096048.html
大概理解是角点一般在边缘上,边缘的梯度与沿边缘方向的的向量正交,也就是内积为0,根据内积为零,角点周围能列出一个方程组,方程组的解就是角点坐标。
opencv亚像素级别定位函数API:
void cv::cornerSubPix(
InputArray image
InputOutputArray corners //输入整数角点坐标,输出浮点数角点坐标
Size winSize //搜索窗口
Size zeroZone
TermCriteria criteria //停止条件
)示例代码
void FeatureVectorOps::corners_sub_pixels_demo(Mat &image) {
Mat gray;
cvtColor(image, gray, COLOR_BGR2GRAY);
int maxCorners = 400;
double qualityLevel = 0.01;
std::vector corners;
goodFeaturesToTrack(gray, corners, maxCorners, qualityLevel, 5, Mat(), 3, false, 0.04);
Size winSize = Size(5, 5);
Size zeroZone = Size(-1, -1);
//opencv迭代终止条件类
TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.001);
cornerSubPix(gray, corners, winSize, zeroZone, criteria);
for (size_t t = 0; t < corners.size(); t++) {
printf("refined Corner: %d, x:%.2f, y:%.2f\n", t, corners[t].x, corners[t].y);
}
} HOG特征描述子
详细请参考:https://baijiahao.baidu.com/s?id=1646997581304332534&wfr=spider&for=pc&searchword=HOG%E7%89%B9%E5%BE%81%E6%8F%8F%E8%BF%B0%E5%AD%90
讲的很好。
大概就是以一种特殊的直方图来表示图像特征,直方图存储的是梯度的方向和幅值(x轴是方向,y轴是幅值且加权)。
示例代码:
virtual void cv::HOGDescriptor::compute(
InputArray img
std::vector & descriptors
Size winStride=Size()
Size padding=Size()
const std::vector &locations = std::vector()
)
void FeatureVectorOps::hog_feature_demo(Mat &image) {
Mat gray;
cvtColor(image, gray, COLOR_BGR2GRAY);
HOGDescriptor hogDetector;
std::vector hog_descriptors;
hogDetector.compute(gray, hog_descriptors, Size(8, 8), Size(0, 0));
std::cout << hog_descriptors.size() << std::endl;
for (size_t t = 0; t < hog_descriptors.size(); t++) {
std::cout << hog_descriptors[t] << std::endl;
}
} HOG特征行人检测
opencv基于HOG行人特征描述子的检测函数:
void HOGDescriptor::detectMultiScale(
InputArray img,
vector& foundLocations,
double hitThreshold=0,
Size winStride=Size(),
Size padding=Size(),
double scale=1.05,
double finalThreshold=2.0,
bool useMeanshiftGrouping=false
)
//示例代码
void FeatureVectorOps::hog_detect_demo(Mat &image) {
HOGDescriptor *hog = new HOGDescriptor();
hog->setSVMDetector(hog->getDefaultPeopleDetector());
vector objects;
hog->detectMultiScale(image, objects, 0.0, Size(4, 4), Size(8, 8), 1.25);
for (int i = 0; i < objects.size(); i++) {
rectangle(image, objects[i], Scalar(0, 0, 255), 2, 8, 0);
}
imshow("HOG行人检测", image);
} ORB特征描述子
没看懂。
描述子匹配
暴力匹配:
再使用暴力匹配之前先创建暴力匹配器:
static Ptr cv::BFMatcher::create(
int normType=NORM_L2 //计算描述子暴力匹配时采用的计算方法
bool crossCheck=false //是否使用交叉验证
) 调用暴力匹配的匹配方法,有两种,最佳匹配和KNN匹配
void cv::DescriptorMatch::match(
InputArray queryDescriptors
InputArray trainDescriptors
std::vector & matches
InputArray mask=noArray
)
void cv::DescriptorMatch::knnMatch(
InputArray queryDescriptors
InputArray trainDescriptors
std::vector & matches
int k
InputArray mask=noArray
bool compactResult =false
) FLANN匹配:
cv::FlannBasedMatcher::FlannBasedMatcher(
const Ptr & indexParams=makePtr()
const Ptr & searchParams=makePtr()
) 示例代码:
void FeatureVectorOps::orb_match_demo(Mat &box, Mat &box_in_scene) {
// ORB特征提取
auto orb_detector = ORB::create();
std::vector box_kpts;
std::vector scene_kpts;
Mat box_descriptors, scene_descriptors;
orb_detector->detectAndCompute(box, Mat(), box_kpts, box_descriptors);
orb_detector->detectAndCompute(box_in_scene, Mat(), scene_kpts, scene_descriptors);
// 暴力匹配
auto bfMatcher = BFMatcher::create(NORM_HAMMING, false);
std::vector matches;
bfMatcher->match(box_descriptors, scene_descriptors, matches);
Mat img_orb_matches;
drawMatches(box, box_kpts, box_in_scene, scene_kpts, matches, img_orb_matches);
imshow("ORB暴力匹配演示", img_orb_matches);
// FLANN匹配
auto flannMatcher = FlannBasedMatcher(new flann::LshIndexParams(6, 12, 2));
flannMatcher.match(box_descriptors, scene_descriptors, matches);
Mat img_flann_matches;
drawMatches(box, box_kpts, box_in_scene, scene_kpts, matches, img_flann_matches);
namedWindow("FLANN匹配演示", WINDOW_FREERATIO);
cv::namedWindow("FLANN匹配演示", cv::WINDOW_NORMAL);
imshow("FLANN匹配演示", img_flann_matches);
} 基于特征的对象检测
特征描述子匹配之后,可以根据返回的各个DMatch中的索引得到关键点对,然后拟合生成从对象到场景的变换矩阵H。根据矩阵H可以求得对象在场景中的位置,从而完成基于特征的对象检测。
opencv中求得单应性矩阵的API:
Mat cv::findHomograph(
InputArray srcPoints
OutputArray dstPoints
int method=0
double ransacReprojThreshold=3
OutputArray mask=noArray()
const int maxIters=2000;
const double confidence=0.995
)有了变换矩阵H ,可以运用透视变换函数求得场景中对象的四个点坐标并绘制出来。
透视变换函数:
void cv::perspectiveTransform(
InputArray src
OutputArray dst
InputArray m
)示例代码:
void FeatureVectorOps::find_known_object(Mat &book, Mat &book_on_desk) {
// ORB特征提取
auto orb_detector = ORB::create();
std::vector box_kpts;
std::vector scene_kpts;
Mat box_descriptors, scene_descriptors;
orb_detector->detectAndCompute(book, Mat(), box_kpts, box_descriptors);
orb_detector->detectAndCompute(book_on_desk, Mat(), scene_kpts, scene_descriptors);
// 暴力匹配
auto bfMatcher = BFMatcher::create(NORM_HAMMING, false);
std::vector matches;
bfMatcher->match(box_descriptors, scene_descriptors, matches);
// 好的匹配
std::sort(matches.begin(), matches.end());
const int numGoodMatches = matches.size() * 0.15;
matches.erase(matches.begin() + numGoodMatches, matches.end());
Mat img_bf_matches;
drawMatches(book, box_kpts, book_on_desk, scene_kpts, matches, img_bf_matches);
imshow("ORB暴力匹配演示", img_bf_matches);
// 单应性求H
std::vector obj_pts;
std::vector scene_pts;
for (size_t i = 0; i < matches.size(); i++)
{
//-- Get the keypoints from the good matches
obj_pts.push_back(box_kpts[matches[i].queryIdx].pt);
scene_pts.push_back(scene_kpts[matches[i].trainIdx].pt);
}
Mat H = findHomography(obj_pts, scene_pts, RANSAC);
std::cout << "RANSAC estimation parameters: \n" << H << std::endl;
std::cout << std::endl;
H = findHomography(obj_pts, scene_pts, RHO);
std::cout << "RHO estimation parameters: \n" << H << std::endl;
std::cout << std::endl;
H = findHomography(obj_pts, scene_pts, LMEDS);
std::cout << "LMEDS estimation parameters: \n" << H << std::endl;
// 变换矩阵得到目标点
std::vector obj_corners(4);
obj_corners[0] = Point(0, 0); obj_corners[1] = Point(book.cols, 0);
obj_corners[2] = Point(book.cols, book.rows); obj_corners[3] = Point(0, book.rows);
std::vector scene_corners(4);
perspectiveTransform(obj_corners, scene_corners, H);
// 绘制结果
Mat dst;
line(img_bf_matches, scene_corners[0] + Point2f(book.cols, 0), scene_corners[1] + Point2f(book.cols, 0), Scalar(0, 255, 0), 4);
line(img_bf_matches, scene_corners[1] + Point2f(book.cols, 0), scene_corners[2] + Point2f(book.cols, 0), Scalar(0, 255, 0), 4);
line(img_bf_matches, scene_corners[2] + Point2f(book.cols, 0), scene_corners[3] + Point2f(book.cols, 0), Scalar(0, 255, 0), 4);
line(img_bf_matches, scene_corners[3] + Point2f(book.cols, 0), scene_corners[0] + Point2f(book.cols, 0), Scalar(0, 255, 0), 4);
//-- Show detected matches
namedWindow("基于特征的对象检测", cv::WINDOW_NORMAL);
imshow("基于特征的对象检测", img_bf_matches);
}