【数据结构】双链表实现
双链表实现
- 双链表
- LinkedList的使用
- ArrayList 和 LinkedList的区别
双链表
双链表的结点其实就是在单链表结点的基础上多了一个存储前一个节点地址的域,例如:

接下来就实现双链表的各种操作,首先定义好双链表的结构:
public class MyLinkedList {
static class ListNode {
public int val;
public ListNode prev; //前驱
public ListNode next; //后继
public ListNode(int val) {
this.val = val;
}
}
public ListNode head; //指向第一个节点
public ListNode last; //指向最后一个节点
}
其中打印双链表、求双链表长度以及判断双链表是否包含某一关键字的方法和在单链表中的实现是一样的。
//打印双链表
public void display() {
ListNode cur = head;
while (cur != null){
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();
}
//求双链表的长度
public int size() {
int len = 0;
ListNode cur = head;
while (cur != null){
len++;
cur = cur.next;
}
return len;
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
ListNode cur = head;
while (cur != null){
if (cur.val == key){
return true;
}
cur = cur.next;
}
return false;
}
头插法:
在链表头部插入数据时,需要考虑链表中是否有节点,没有结点只需将 head 和 last 都指向这个新结点即可,有节点就需要改动三个地方了(原来 head 的 prev,新结点的 next,head 的指向)。

头插代码:
//头插法
public void addFirst(int data) {
ListNode node = new ListNode(data);
if (head == null){
head = node;
last = node;
}else {
//将新结点的next指向head
node.next = head;
//head的prev存储新结点的地址
head.prev = node;
//head重新指向新结点
head = node;
}
}
实现效果:
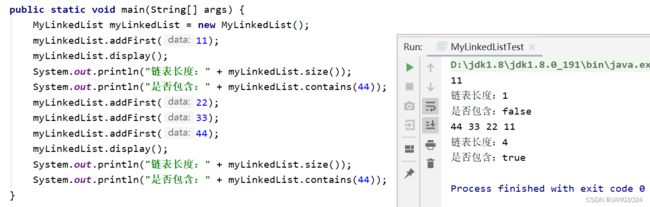
尾插法:
在单链表中,尾插需要找到最后一个节点,而在双链表中,last 记录了链表中的最后一个节点,不需要遍历查找最后一个节点。

尾插代码:
//尾插法
public void addLast(int data) {
ListNode node = new ListNode(data);
if (head == null){
head = node;
last = node;
}else {
//原来last的next指向新结点node
last.next = node;
//新结点的prev指向原来的last
node.prev = last;
//last指向新结点node
last = node;
}
}
实现效果:

任意位置插:
任意位置插也要注意位置是否合法。

存储 cur 的地址并修改新结点 node 的 next:

存储下标1节点地址:

修改 cur 节点的 prev 和下标1节点的 next:

尾插代码:
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index, int data){
//插入位置不合法,抛出异常
if (index < 0 || index > size()){
throw new ListIndexOutOfException();
}
//在0位置插入为头插
if (index == 0){
addFirst(data);
return;
}
//最后位置插入为尾插
if (index == size()){
addLast(data);
return;
}
//其他位置插入,则需要找到这个位置
ListNode cur = head;
while(index != 0){
cur = cur.next;
index--;
}
//找到插入位置后,修改指向
ListNode node = new ListNode(data);
node.next =cur;
node.prev = cur.prev;
cur.prev = node;
node.prev.next = node;
尾插效果:

删除第一次关键字为 key :
删除关键字需要考虑多种情况,避免造成错误。

删除第一次关键字为 key 的代码:
//删除第一次出现关键字为key的节点
public void remove(int key) {
ListNode cur = head;
while (cur != null) {
//如果结点的值等于key就删除
if (cur.val == key) {
//先判断删除的结点是否为第一个节点
if (cur == head) {
//是头就采用删除头的方式
head = head.next;
//head等于空,说明只有一个节点并且被删了,如果不判断就会空指针异常
if (head != null) {
//head不等于空才能使用
head.prev = null;
}
} else {
//不是头就是中间和结尾的结点,再根据next判断一下是中间的还是尾巴
if (cur.next == null) {
//这里是尾巴,使用删除尾巴的方式
last = last.prev;
last.next = null;
} else {
//这里就是中间结点
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
}
//删除后返回
return;
}
//不等于就指向下一个
cur = cur.next;
}
}
删除效果:
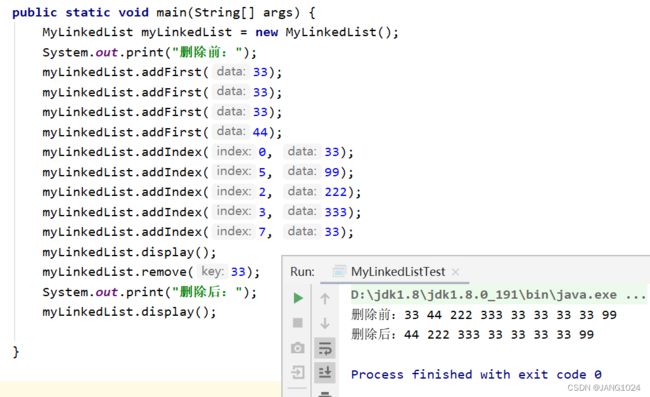
删除所有值为 key 的节点
我们只需将上面方法中的 return 语句删除,cur 就会继续向链表后面移动并删除。
代码:
public void removeAllKey(int key) {
//上面的删除关键字后会返回,只需取消返回,cur就会继续向后走,并删除所有关键字
ListNode cur = head;
while (cur != null) {
//如果结点的值等于key就删除
if (cur.val == key) {
//先判断删除的结点是否为第一个节点
if (cur == head) {
//是头就采用删除头的方式
head = head.next;
//head等于空,说明只有一个节点并且被删了,如果不判断就会空指针异常
if (head != null) {
//head不等于空才能使用
head.prev = null;
}
} else {
//不是头就是中间和结尾的结点,再根据next判断一下是中间的还是尾巴
if (cur.next == null) {
//这里是尾巴,使用删除尾巴的方式
last = last.prev;
last.next = null;
} else {
//这里就是中间结点
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
}
//取消return后,cur就会继续向后走
//return;
}
//不等于就指向下一个
cur = cur.next;
}
}
实现效果:
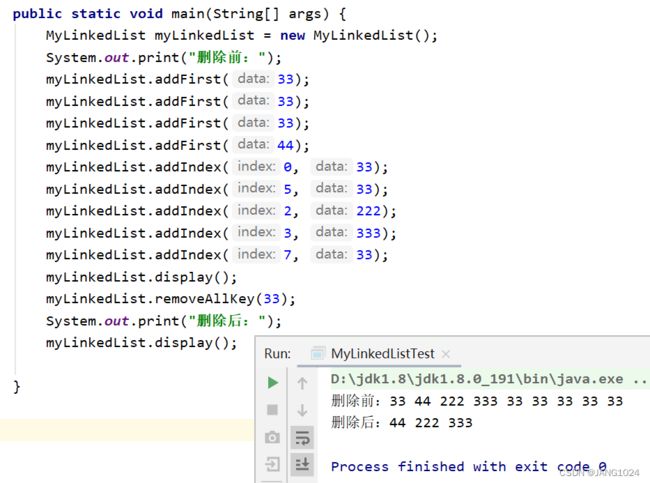
清空链表:
双链表中清空链表方法就不像单链表那样,只需将 head 和 last 置为 null,因为在双链表中,head 的下一个结点还可以通过 prev 找到 head 结点。
我们只需在遍历链表的同时,将链表中的 next 和 prev 都置为 null,最后再让 head 和 last 都置为 null 即可。
代码:
public void clear() {
ListNode cur = head;
while (cur != null) {
//记录下一结点
ListNode curNext = cur.next;
cur.next = null;
cur.prev = null;
cur = curNext;
}
head = null;
last = null;
}
LinkedList的使用
LinkedList 的底层是双向链表结构,由于链表没有将元素存储在连续的空间中,元素存储在单独的节点中,然后通过引用将节点连接起来了,因此在任意位置插入或删除元素时,不需要移动元素,只需要修改指向,效率较高。LinkedList 的官方文档。
LinkedList 的构造:
LinkedList 既可以无参构造,也可以使用其他集合容器中元素构造,例如:

LinkedList 的常用方法:
添加:

删除:

其他常用方法:
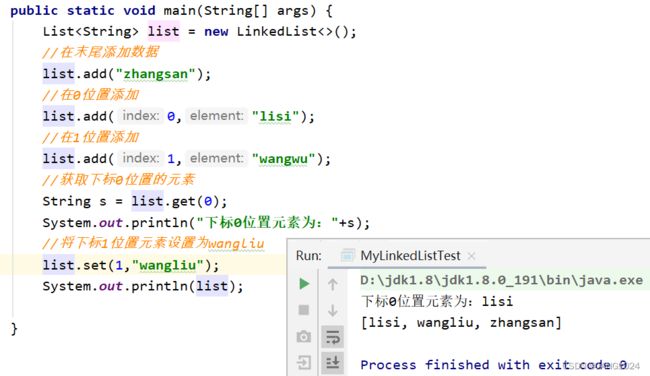
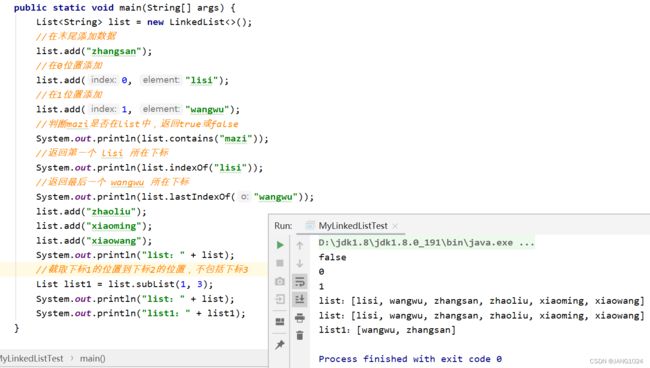
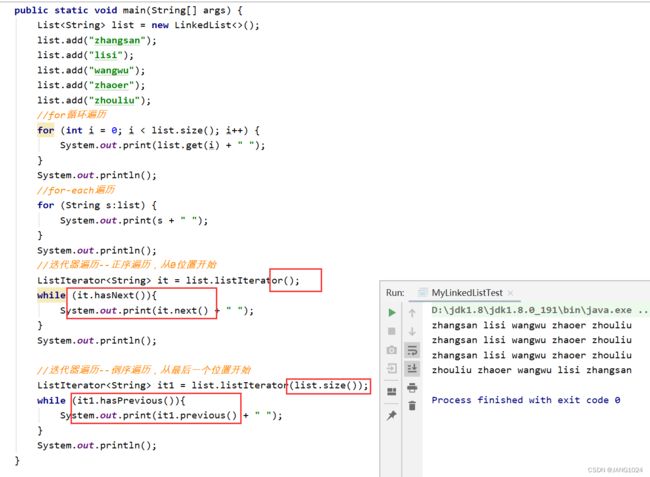
遍历:
ArrayList 和 LinkedList的区别
存储上空间上:ArrayList 物理上连续。LinkedList 逻辑上连续,但物理上不一定连续。
头插法:ArrayList 头插涉及元素的移动,效率较低。LinkedList 只需修改引用的指向,不用移动元素,效率高。
插入时:ArrayList 空间不够时,需要扩容。而 LinkedList 则没有这个说法。
总的来说就是,只需要对元素进行大量查询但不需要插入或删除时,建议使用 ArrayList,如果需要对元素进行大量插入或删除时,建议使用 LinkedList。