小红书论文刷新 SOTA:人体动作预测再升级,能精准到指尖
想象一下,你在玩一款 VR 游戏,准备伸手拿起一个虚拟杯子喝水。
在传统的交互系统中,这通常需要你按下控制器上的特定按钮。但如果游戏集成了 EAI 框架,这一过程将变得无比自然。当你的手缓缓接近虚拟杯子时,系统会敏锐地预测出你的未来手部动作,无需任何操作,游戏中的“你”便会流畅地模拟出精细的手部抓取动作,游戏引擎也会提前对你的动作行为做出响应。
这种无缝的交互体验,将会提升游戏中人-人、人- NPC 交互的实时性和准确性,极大地提升游戏沉浸感。
什么是 EAI 框架?全称是编码-对齐-交互(Encoding-Alignment-Interaction)框架,由小红书创作发布团队在 AAAI 2024 上创新提出。该框架用于预测未来全身人体动作,尤其擅长手部细微动作的预测。
EAI 框架的应用远不止于此。它能够理解并预测用户的动作意图,无论是在艺术表演中同步舞者的动作,创造出与音乐和视觉效果和谐融合的动态艺术,还是在智能家居中自动响应你的需求,或是在医疗康复领域指导患者正确执行运动,避免潜在伤害。它甚至能够预测潜在的安全威胁,如在拥挤场所避免踩踏事件。
实验结果表明:EAI 框架在多个大规模基准数据集上取得了最先进的预测性能(SOTA)。它有效地处理了身体和手部动作之间的异质性和交互性,实现了全身动作预测的高质量输出。这一突破性的技术,预示着未来在人机交互、虚拟现实以及更广泛的智能系统中,将有无限的可能性等待着被探索。

人体动作预测(Human Motion Forecasting),即预估未来一段时间内的人类行为,正成为连接人类行为与智能系统的关键桥梁。在人机交互(HRI)、虚拟现实(VR)和游戏动画(GA)等领域,这一任务至关重要。然而,现有研究通常集中在预测人体主要关节的运动,却忽略了手部精细动作,而这些动作在沟通和交互中至关重要。
在人机交互场景中,机器人需要准确预测人类未来动作以实现有效协作,但现有模型未能充分捕捉手部精细动作,这直接影响了对人类意图和行为的理解。此外,人体各部分间的协作和交付,如喝水、鼓掌等复杂交互模式,也未被现有预测模型充分捕捉,这限制了预测的准确性和表达性。

为解决上述挑战,我们首先提出了一种全新范式:全身人体动作预测任务,即同时预测身体和手部所有关节的未来活动。通过这种联合预测,可以更准确地捕捉人类行为的全貌,从而在人机交互等应用中提供更自然的交互体验。这种全身运动预测不仅包括身体的主要动作,还细致地考虑了手部的精细运动,以理解人类行为的意图和情感表达。
进一步地,为实现面向全身人体关节的细粒度动作预测的目标,我们重点提出了编码-对齐-交互(Encoding-Alignment-Interaction,EAI)框架。EAI 框架主要包括以下两个核心组成部分:
- 跨上下文对齐(cross-context-alignment,XCA):用于对齐不同人体组件的潜在特征,消除异质性
- 跨上下文交互(cross-context-interaction,XCI):专注于捕捉人体组件间的上下文交互,提高动作预测的准确性
通过在新引入的大型数据集上的广泛实验,EAI 框架在 3D 全身人体动作预测方面取得了最先进的性能,证明了其在捕捉人类动作细微差别方面的有效性。这些实验结果不仅展示了 EAI 框架在预测复杂人类动作方面的优越性,还为未来的人机交互和虚拟现实等领域的应用提供了新的视角和可能性。


EAI 算法流程图
如图所示,EAI 框架主要涉及以下三个核心步骤:
- Encoding :通过离散余弦变换(DCT) 和动态图卷积神经网络(GCNs)提取运动序列的时空相关性,并将其编码为高维隐藏特征;
- Alignment:通过提出的跨上下文对齐(XCA)来调整不同身体部分的潜在特征,使其更加一致;
- Interaction:利用提出的跨上下文交互(XCI)来捕捉身体各部分之间的语义和物理互动。
这种方法通过联合预测身体和手部动作,能够提高预测运动的准确性和表达性,特别是在捕捉不同人体部分动作的细微差别方面具有较强的性能。
2.1内部上下文编码(Intra-context Encoding)

a. DCT 编码:在时间域,使用离散余弦变换(Discrete Cosine Transform,DCT)来捕捉动作序列的时序平滑性,将观察到的动作序列转换到轨迹空间:
b. GCN 表示学习:在空间域,利用图卷积网络(Graph Convolutional Networks,GCNs)将骨骼表示为一个全连接图,通过邻接矩阵来捕捉空间关系:



2.2 跨上下文对齐(Cross-context Alignment)
跨上下文对齐(Cross-context Alignment,XCA) 目的是对齐不同身体部分(如身体、左手和右手)的潜在特征,以消除它们之间的异质性,从而方便后续的跨上下文特征交互。该模块通过以下步骤实现特征对齐:
a. 特征中立化:引入可学习的因子来中和不同特征分布之间的差异,通过最小化最大均值差异(Maximum Mean Discrepancy,MMD)来调整特征分布,使其更加接近一致:
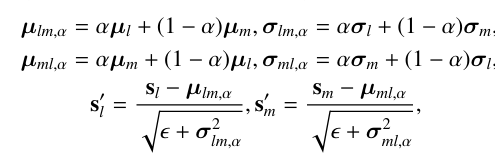
b. 环形中立化:为了进一步实现 part-to-part 的对齐,我们将中立化扩展到环形版本,通过身体到手腕的链路来实现身体和手部之间的对齐,确保每个部分的特征对齐都会考虑到其他两个部分的特征属性。

c. 不一致性约束:接着,我们应用差异约束来减少部分到部分的差异,通过计算特征的平均值和方差,然后应用中立化和差异约束来调整特征,使其分布更加一致。

通过 XCA,EAI 框架能够有效地处理身体各部分之间的异质性,为后续的 XCI 提供了更加一致和协调的特征表示,从而有助于提高全身动作预测的准确性和表达性。
2.3 跨上下文交互(Cross-context Interaction)
跨上下文交互(Cross-context Interaction,XCI)是 EAI 框架中的另一个核心模块,它专注于捕捉全身不同部分之间的交互性,包括语义和物理层面的互动。这个模块通过以下步骤实现交互:
a. 语义交互:通过交叉注意力机制,模型学习不同身体部分之间的语义依赖性。例如,对于吃饭这个动作,手指和头部关节之间存在强相关性。XCI 通过计算注意力图来融合这些语义交互信息。

b. 物理交互:作为身体和手部之间的桥梁,手腕提供了直接的链式相关性。XCI 采用“分割和融合”策略,首先独立地复制手腕关节以包含它,然后进行动态特征融合,以更好地模拟身体部分之间的物理连接。

通过最小化分布差异误差,XCI 将不同身体部分的特征融合在一起,生成表达性特征。这些特征随后用于预测器,以回归到预测的序列。通过 XCI,EAI 框架能够捕捉到全身动作中微妙的交互细节,这对于理解和预测复杂的人类行为至关重要。这种交互性的理解有助于提高预测的准确性,特别是在涉及精细手部动作的场景中。
2.4 损失函数(Training Loss)
损失函数(Training Loss)主要包含四个部分:关节损失、物理损失、骨头长度损失和对齐损失,具体如下:


![]()



![]()

最终损失是所有损失函数的加权和,综合了预测损失、物理损失和对齐损失。通过调整权重参数(λ1、λ2、λ3)来平衡这些损失,以确保模型在训练过程中能够同时优化预测准确性和特征的一致性。


3.1 实验设置

评估指标:为了评估模型的性能,我们使用了平均每个关节位置误差 MPJPE、手腕对齐后的 MPJPE-AW。MPJPE 用于衡量预测的 3D 坐标的准确性,而MPJPE-AW 则用于评估手部动作的精细预测,通过将手势与手腕对齐来减少手腕运动对预测的影响。
实验设置:我们采用了两种训练策略来评估不同方法的性能:
(1)分隔(D)训练策略,分别针对每个人体组件的训练基线方法,这种独立策略缺乏组件之间的交互,可以用来说明 XCI 的有效性。

3.2 指标对比结果
我们首先统计了 GRAB 数据集上的平均预测性能(表 1),针对每种动作类型统计了预测性能(表 2)。我们分别展示了使用分割策略(标注为 D)和联合策略(标注为 U)的预测结果。另外,每个表格中分别展示了身体关节的预测结果(major body)、左手关节的预测结果(left hand)、右手关节的预测结果(right hand),以及使用腕关节对齐后的左手对齐误差(left hand AW)、右手对齐误差(right hand AW),以及全身所有关节的预测结果(whole body)。

表1:GRAB 数据集上采用分隔(D)和联合(U)训练的平均预测结果

表2:采用统一训练策略,GRAB 数据集上每一个动作类别下的预测结果
3.3 可视化对比结果
可视化对比结果部分提供了一种直观的方式来评估和理解模型在预测全身动作方面的性能。通过展示「play」动作的全身骨骼形式,我们可以分析模型的预测性能。这些可视化结果可以帮助我们直观地理解模型在预测精细动作和粗略动作方面的表现。可以清晰地看出,提出的 EAI 方法不仅在预测躯干姿态方面取得了最优的性能,而且对于细粒度的手部动作具有更好的预测结果。

「play」动作下的全身关节预测结果对比
3.4 消融实验
消融实验(Ablation Study)旨在评估 EAI 框架中不同组件对最终性能的贡献程度。这些实验通过单独移除或修改框架中的某些部分来观察模型性能的变化。具体来说,消融实验包括以下几个方面:
- 移除 XCA 和 XCI :首先,实验移除了跨上下文对齐(XCA)和跨上下文交互(XCI)模块,以观察这些核心组件对模型性能的影响。通过比较移除这些组件前后的平均预测误差,可以评估它们在提高预测准确性方面的重要性。
- 移除 XCA 的子模块:进一步地,实验移除了 XCA 中的交叉中性化(CN)和差异约束(DC)子模块,以单独评估这些技术在对齐不同身体部分特征分布中的作用。
- 移除 XCI 的子模块:类似地,实验移除了 XCI 中的语义交互(SI)和物理交互(PI)子模块,以分析这些交互在捕捉身体部分之间相互作用中的效果。
- 全模型与消融模型比较:通过比较包含所有组件的全模型与经过消融的模型,可以直观地看到每个组件对整体性能的具体贡献。

移除不同组件时对于算法性能影响的分析

在本研究中,小红书创作发布团队提出了一种创新的全身人体动作预测框架——编码-对齐-交互(EAI),该框架旨在同时预测身体主要关节和手部的精细动作。我们通过引入跨上下文对齐(XCA)和跨上下文交互(XCI)机制,有效地处理了全身动作预测中的异质性和交互性问题。在新引入的 GRAB 数据集上的广泛实验表明,EAI 框架在 3D 全身人体动作预测方面取得了最先进的性能(SOTA),显著提升了预测的准确性和表达性。
我们的工作不仅在理论上提出了新的预测框架,而且在实际应用中也展示了其潜力,尤其是在需要精细手部动作预测的场景中。这些技术能够支撑小红书媒体技术中面向细粒度人体动作生成、分析、建模的需求。不过这项工作仍有待进一步探索,例如,如何将与物体的交互纳入模型,以提供更准确的运动预测。随着未来研究的深入,我们期待 EAI 框架将为人体运动预测领域带来更多的创新和突破。
论文地址:https://arxiv.org/pdf/2312.11972.pdf
代码地址:https://github.com/Dingpx/EAI

- @丁鹏翔(实习)
硕士毕业于北京邮电大学,目前为西湖大学博士生,该工作完成于在小红书实习期间。发表多篇期刊和会议论文,主要研究方向为人体动作分析,3D 计算机视觉。
- @崔琼杰(实习)
博士毕业于南京理工大学,该工作完成于在小红书实习期间。在 CVPR、ICCV、ECCV、IJCAI、AAAI 等国际会议上发表多篇论文,担任多个国际顶级计算机视觉,人工智能会议的审稿人。目前主要研究方向为人体运动分析与合成。
- @炎真(王浩帆)
小红书创作发布组- AIGC 方向算法工程师,硕士毕业于卡内基梅隆大学,在 CVPR、ICCV、NeurIPS、3DV、AAAI、TPAMI 等国际会议和学术期刊上发表多篇论文。目前主要研究方向为图像、视频、3D 生成。

创作发布团队-算法实习生(AIGC方向)
岗位职责:
1. 负责 AIGC 生成业务在小红书平台的落地和上线。
2. 负责调研前沿技术,参与创新性算法的研究以及开发工作;如有较好成果,可支持论文发表。
任职资格:
1. 熟悉目前 AIGC 常用技术链并有实际项目或论文经验,如 LoRA、ControlNet 的训练,了解近期图像、视频生成领域的最新进展。
2. 具有良好的沟通、编程、合作能力。在知名赛事有获奖名次或在顶级会议上已发表过至少一篇论文的优先。
3. 现场入职,北京、上海均可,实习至少三个月以上;如有科研意向,至少半年以上。
欢迎感兴趣的同学发送简历至[email protected],并抄送至[email protected]。