#RAG|NLP|Jieba|PDF2WORD# pdf转word-换行问题
文档在生成PDF时,文宁都发生了什么。本文讲解了配置对象、resources对象和content对象的作用,以及字体、宇号、坐标、文本摆放等过程。同时,还解释了为什么PDF转word或转文字都是一行一行的以及为什么页眉页脚的问题会加大识别难度。最后提到了文本的编码和PDF中缺少文档结构标记的问题。PDF转word更像是一种逆向工程。
第三方库pdf转word的痛点-格式不保留
本文着力解决换行问题:
- 源文本正常输入,pdf解析第三方库识别出来多余换行符
如
原文:“你好”
识别:“你\n好” - 源文本出现多个换行符,pdf解析第三方库识别出一个换行符
如
原文:“你好\n\n\n\n\n\n我是向日葵花子”
识别:“你好\n我是向日葵花子”
word 转 pdf 经历了什么
文本转换为PDF时,记录的信息
包括:
- 位置和大小信息:记录每个文本在页面上的位置和大小。
- 字体信息:记录文本所使用的字体名称、大小和样式。
- 颜色信息:记录文本的颜色。
- 行间距和段落间距:记录文本之间的行间距和段落之间的间距。
- 文本属性:记录文本的对齐方式、装饰等其他属性。
- 超链接和书签:记录文本中的超链接和书签信息,以实现交互功能。
这些信息的记录旨在确保在PDF中正确呈现文本内容,并保持文档的原始格式和布局。
pdf文本信息
pdf文本是由文本空间组成的,其中包含:
文本矩阵,定义下一个字形的当前转换。它由文本定位和显示运算符的文本改变。
文本行矩阵,它是当前行开头的文本矩阵的状态。因此,通过使用操作员移动到下一行,可以垂直对齐文本行,而无需手动跟踪行的开始位置。
这些矩阵不会从文本部分持续到文本部分,而是在每个文本部分的开头重置为单位矩阵。 结合字体大小,水平缩放和文本上升,这两个矩阵定义了从文本空间到用户空间的转换。
如何获得pdf信息
大段处理
可以在调用第三方库的过程中加一些小算法,我这里给一点点提示
- 读取pdf基本信息
- 逐行获取pdf信息
- 根据每行的行宽来判断是不是多输出了换行符
- 每行即使没有文字只有换行符也要加入到获取的信息中
这一步可以完成百分之八十的换行格式还原。
获取每行信息的代码:
with pdfplumber.open(file_path) as pdf:
for p in pdf.pages:
# print(p.bbox)
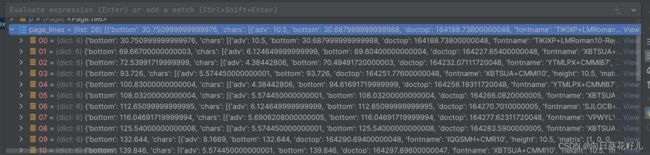
page_lines = p.extract_text_lines()
接下来就要去分析文档每行的信息,然后利用坐标去处理了,大家可以自己思考下代码怎么写。
页眉页脚、大小标题
识别处理思路和大段处理一致
小段处理

通过坐标处理不了两行的小段,特别是开头没有缩进的unstructured文本,这里我们需要加上其他算法。
我使用的是nlp的文本分析进行兜底。
处理流程:
- 分析上下文关系优化结构算法: 在获取到文本内容后,可以编写一个分析句子上下文关系的算法来处理文本,对于出现问题的地方进行修正。
主要用到:
词性标注(Part-of-Speech Tagging): 词性标注是将句子中的每个词汇标记为其对应的词性(如名词、动词、形容词等)的过程。通过词性标注可以识别句子中各个词汇的语法角色,从而帮助理解句子的结构和含义。
句法分析(Syntax Parsing): 句法分析是分析句子中各个词汇之间的语法关系,如主谓关系、动宾关系等。通过句法分析可以构建句子的语法树,从而帮助理解句子的结构和语义。 - 合并文本: 根据分析结果,将需要合并的部分合并到一起。
- 输出结果:输出处理后的文本。
这一步可以完成到90%的换行格式还原,通过不断优化句法分析的规则,可以逐渐接近100%。
清洗文本
nlp句法分析是分析句子中各个词汇之间的语法关系,因此,像emoji或者其他特殊、对于计算机语义处理无意义的符号保留下来必定对结果产生很大影响,最终合并的效果大打折扣,所以我们需要先对文本进行一个清洗,去掉无意义的符号。
由于我的文档只涉及到emoji这种特殊符号,所以我只进行了emoji的清洗
def remove_emoji(text):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002600-\U000027BF" # miscellaneous symbols
u"\U0001F300-\U0001FAD6" # additional emoticons
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', text)
句子拆分
按照逗号拆分就可以,然后找到带有换行符号的句子进行进一步的词性标注
注意只取带有换行符的小句,这样可以提高工作效率减少无意义的算法调用
使用split函数即可
词性标注
为了分析句子语法关系、上下文关系,我们必须先进行词性标注,构建语法树,然后再进行句子分析
这里我直接用的中文nlp库jieba,其他好用的库可以直接替换使用,如果是英文词性标注可以使用ntlk,ntlk也有中文词性标注,但是我中文标注我更喜欢用jieba
jieba的jieba词性标注表我也给大家整理好了
词性标注的代码:
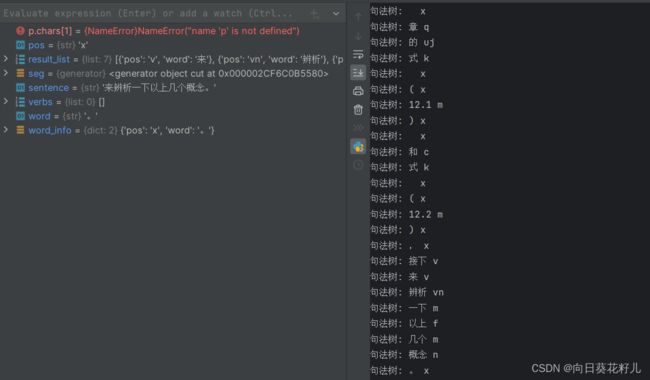
import jieba.posseg as psg
# 分词和词性标注
seg = psg.cut(sentence)
# 定义语法规则
result_list = []
verbs = []
for word, pos in seg:
# 对句法树进行处理,这里只是简单打印出来,你可以根据需要处理
print("句法树:", word, pos)
word_info = {'word': word, 'pos': pos}
# 将字典添加到列表中
result_list.append(word_info)
if pos == 'v':
verbs.append(word_info)
verbs = [word for word, pos in seg if pos == 'v']
分析上下文关系
词性标注结束后,我们就可以根据语法树分析上下文关系了
merged_sentences = []
for i, sentence in enumerate(sentences):
if i > 0:
# 分析上下文关系
verbs_prev, seg_prev = analyze_context(sentences[i - 1])
verbs_curr, seg_curr = analyze_context(sentence)
x = list(seg_prev)
# 如果前一个句子或当前句子至少有一个含有动词,则进行合并
if (len(verbs_prev) == 1 and len(verbs_curr) == 0) or (len(verbs_prev) == 0 and len(verbs_curr) == 1):
merged_sentences[-1] += sentence
# 如果上一句的最后一个词和下一句的第一个词都是动词,则进行合并
elif seg_prev[-1] and seg_curr[0] and seg_prev[-1]["pos"] in ['r', 'v'] and seg_curr[0]["pos"] == 'v':
merged_sentences[-1] += sentence
# 代词和指示词:如果后一个句子以代词或指示词开头,这可能表明它是对前一个句子的补充。
elif seg_curr[0]["pos"] in ['r', 'z', 'c'] or seg_curr[0]["word"] in ['这', '那', '其', ...]:
merged_sentences[-1] += sentence
# 时间+n
elif seg_curr[0]["pos"] in ['n'] or seg_prev[0]["pos"] in ['t', 'm', ...]:
merged_sentences[-1] += sentence
# 句号和分号:虽然句号和分号通常表示句子的结束,但如果它们后面紧跟的是小写字母或标点符号,可能意味着这是同一句话的一部分。
elif seg_prev[-1]["word"] in ['。', ';'] and not seg_curr[0]["word"].istitle():
merged_sentences[-1] += sentence
# 如果后一个句子的第一个词是“的”并且前一个句子的最后一个词是动词,则进行合并
elif seg_curr[0] and seg_curr[0]["pos"] == 'm' and seg_prev[-1] and seg_prev[-1]["pos"] == 'v':
merged_sentences[-1] += sentences[i]
# 如果后一个句子的第一个词是“的”并且前一个句子的最后一个词是动词,则进行合并
elif seg_curr[0] and seg_curr[0]["pos"] == 'p' and seg_prev[-1] and seg_prev[-1]["pos"] == 'd':
merged_sentences[-1] += sentences[i]
# 3. 如果上一句的最后一个词是标点符号,且下一句的第一个词不是句首发语词,则进行合并
elif seg_prev[-1]["pos"] == 'x' and seg_curr[0]["pos"] not in ['c', 'r', 'u', 'p', 'm', 'e']:
merged_sentences[-1] += sentence
# 4. 如果上一句的最后一个词是名词或动词,且下一句以时间状语或条件状语开头,则进行合并
elif (seg_prev[-1]["pos"] in {'n', 'vg', 'v'}) and (seg_curr[0]["pos"] in {'f', 'c'}):
merged_sentences[-1] += sentence
else:
merged_sentences.append(sentence)
else:
merged_sentences.append(sentence)
我在判断规则的同时,进行了是否合并的判断,这样 我们就得到了合并后的文本merged_sentences

参考文献
https://www.bilibili.com/video/BV1Vi4y1C71M/?spm_id_from=333.788&vd_source=8c9777cd5733f7f447f766cd5105041b