1、八大排序
八大排序参考:https://www.jianshu.com/p/7d037c332a9d
1. 直接插入排序
核心思想:将数组中的所有元素(从第二个元素开始,第一个默认已排好序)依次跟前面已经排好的所有元素相比较,如果选择的元素比已排序的元素小,则交换位置,直到全部元素都比较过。
因此,直接插入排序可以用两个循环完成:
- 第一层循环:遍历待比较的所有数组元素(从第二个元素开始)
- 第二层循环:将上层循环选择的元素(selected)与已经排好序的所有元素(ordered)相比较,从选择元素的前面一个开始直到数组的起始位置。如果selected < ordered,那么将二者交换位置,继续遍历;反之,留在原地,选择下一个元素。
代码实现:
# 直接插入排序
def insert_sort(nums):
# 遍历数组中的所有元素,其中0号索引元素默认已排序,因此从1开始
for i in range(1, len(nums)):
# 将该元素与已排序好的前序数组依次比较,如果该元素小,则交换
# range(x,-1,0):从x倒序循环到0,依次比较,
# 每次比较如果小于会交换位置,正好按递减的顺序
for j in range(i, 0, -1):
# 判断:如果符合条件则交换
if nums[j] < nums[j-1]:
temp = nums[j]
nums[j] = nums[j-1]
nums[j-1] = temp
else:
break
return nums
2. 希尔(Shell)排序
算法思想:将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;每次将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
从上面的描述中我们可以发现希尔排序的总体实现应该由三个循环完成:
- 第一层循环:将gap依次折半,对序列进行分组,直到gap=1
- 第二、三层循环:也即直接插入排序所需要的两次循环。对第一个gap进行排序时,实际只循环了序列长度的一半,最内层不会循环。gap值减小后,最内层也需要循环,利用直接插入的思想,只是间隔变为gap。
代码实现:
# 希尔排序
def insert_shell(nums):
# 初始化gap值,此处利用序列长度的一半为其赋值
gap = len(nums) // 2
# 第一层循环:依次改变gap值对列表进行分组
while gap >= 1:
# 下面:利用直接插入排序的思想对分组数据进行排序
# range(gap, len(L)):从gap开始
for i in range(gap, len(nums)):
# range(i, 0, -gap):从i开始与选定元素开始倒序比较
# 每个比较元素之间间隔gap
for j in range(i, 0, -gap):
# 如果该组当中两个元素满足交换条件,则进行交换
if nums[j] < nums[j-gap]:
temp = nums[j-gap]
nums[j-gap] = nums[j]
nums[j] = temp
else:
break
gap = gap // 2
return nums
3. 简单选择排序
基本思想:比较+交换。从待排序序列中,找到最小的元素;如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;从余下的 N - 1 个元素中,找出最小的元素,重复,直到排序结束。
简单选择排序也是通过两层循环实现:
- 第一层循环:依次遍历序列当中的每一个元素
- 第二层循环:将遍历得到的当前元素依次与余下的元素进行比较,符合最小元素的条件,则交换。
代码如下:
# 简单选择排序
def select_sort(nums):
# 依次遍历序列中的每一个元素
for i in range(len(nums)):
# 将当前位置的元素定义此轮循环当中的最小值
min_idx = i
# 将该元素与剩下的元素依次比较寻找最小元素
for j in range(i+1, len(nums)):
if nums[j] < nums[min_idx]:
min_idx = j
# 将比较后得到的真正的最小值赋值给当前位置
if i != min_idx:
temp = nums[i]
nums[i] = nums[min_idx]
nums[min_idx] = temp
return nums
4. 堆排序
堆:本质是一种数组对象。特别重要的一点性质:任意的叶子节点小于(或大于)它所有的父节点。对此,又分为大顶堆和小顶堆,大顶堆要求节点的元素都要大于其孩子,小顶堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求。利用堆排序,就是基于大顶堆或者小顶堆的一种排序方法。下面,我们通过大顶堆来实现。
基本思想
堆排序可以按照以下步骤来完成:
- 首先将序列构建成为大顶堆;
(这样满足了大顶堆那条性质:位于根节点的元素一定是当前序列的最大值)
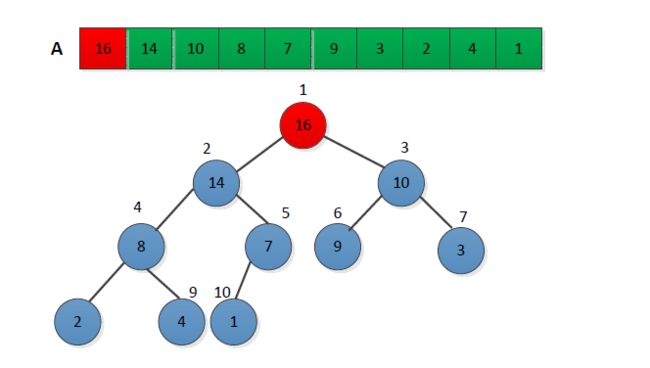
取出当前大顶堆的根节点,将其与序列末尾元素进行交换;
(此时:序列末尾的元素为已排序的最大值;由于交换了元素,当前位于根节点的堆并不一定满足大顶堆的性质)对交换后的n-1个序列元素进行调整,使其满足大顶堆的性质;

- 重复2.3步骤,直至堆中只有1个元素为止
代码如下:
# -------------------------堆排序--------------------------------
# **********获取左右叶子节点**********
def LEFT(i):
return 2*i + 1
def RIGHT(i):
return 2*i + 2
# ********** 调整大顶堆 **********
# nums:待调整序列 length: 序列长度 i:需要调整的结点
def adjust_max_heap(nums, length, i):
# 定义一个int值保存当前序列最大值的下标
largest = i
# 执行循环操作:两个任务:1 寻找最大值的下标;2.最大值与父节点交换
while True:
# 获得序列左右叶子节点的下标
left, right = LEFT(i), RIGHT(i)
# 当左叶子节点的下标小于序列长度 并且左叶子节点的值大于父节点时,
# 将左叶子节点的下标赋值给largest
if (left < length) and (nums[left] > nums[i]):
largest = left
# 当右叶子节点的下标小于序列长度 并且右叶子节点的值大于父节点时,
# 将右叶子节点的下标值赋值给largest
if (right < length) and (nums[right] > nums[largest]):
largest = right
# 如果largest不等于i 说明当前的父节点不是最大值,需要交换值
if largest != i:
temp = nums[i]
nums[i] = nums[largest]
nums[largest] = temp
i = largest
else:
break
#********** 建立大顶堆 **********
def build_max_heap(nums):
length = len(nums)
for x in range(length//2, -1, -1):
adjust_max_heap(nums, length, x)
#********** 堆排序 **********
def heap_sort(nums):
# 先建立大顶堆,保证最大值位于根节点;并且父节点的值大于叶子结点
build_max_heap(nums)
# i:当前堆中序列的长度.初始化为序列的长度
length = len(nums)
# 执行循环:1. 每次取出堆顶元素置于序列的最后(len-1,len-2,len-3...)
# 2. 调整堆,使其继续满足大顶堆的性质,注意实时修改堆中序列的长度
while length > 0:
temp = nums[length-1]
nums[length-1] = nums[0]
nums[0] = temp
# 堆中序列长度减1
length -= 1
# 调整大顶堆
adjust_max_heap(nums, length, 0)
return nums
5. 冒泡排序
冒泡排序思路比较简单:
- 将序列当中的左右元素,依次比较,保证右边的元素始终大于左边的元素;
( 第一轮结束后,序列最后一个元素一定是当前序列的最大值;) - 对序列当中剩下的n-1个元素再次执行步骤1。
- 对于长度为n的序列,一共需要执行n-1轮比较
(利用while循环可以减少执行次数)
代码实现:
# 冒泡排序
def bubble_sort(nums):
length = len(nums)
# 序列长度为length,需要执行length-1轮交换
for i in range(1, length):
# 对于每一轮交换,都将序列当中的左右元素进行比较
# 每轮交换当中,由于序列最后的元素一定是最大的,
# 因此每轮循环到序列未排序的位置即可
for j in range(length-i):
if nums[j] > nums[j+1]:
temp = nums[j]
nums[j] = nums[j+1]
nums[j+1] = temp
return nums
6. 快速排序
基本思想:挖坑填数+分治法
- 从序列当中选择一个基准数(pivot)。在这里我们选择序列当中第一个数最为基准数;
- 将序列当中的所有数依次遍历,比基准数大的位于其右侧,比基准数小的位于其左侧;
- 重复步骤1.2,直到所有子集当中只有一个元素为止。
用伪代码描述如下:
1.i = 序列最左侧; j = 序列最右侧; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中
代码实现:
# 快速排序
# nums:待排序的序列;start排序的开始index,end序列末尾的index
# 对于长度为length的序列:start = 0;end = length-1
def quick_sort(nums, start=0, end=None):
if end is None:
end = len(nums) - 1
if start < end:
i, j, pivot = start, end, nums[start]
while i < j:
# 从右开始向左寻找第一个小于pivot的值
while (i < j) and (nums[j] >= pivot):
j -= 1
# 将小于pivot的值移到左边
if i < j:
nums[i] = nums[j]
i += 1
# 从左开始向右寻找第一个大于pivot的值
while (i < j) and (nums[i] <= pivot):
i += 1
# 将大于pivot的值移到右边
if i < j:
nums[j] = nums[i]
j -= 1
# 循环结束后,说明 i=j,此时左边的值全都小于pivot,右边的值全都大于pivot
# pivot的位置移动正确,那么此时只需对左右两侧的序列调用此函数进一步排序即可
# 递归调用函数:依次对左侧序列:从0 ~ i-1//右侧序列:从i+1 ~ end
nums[i] = pivot
# 左侧序列继续排序
quick_sort(nums, start, i-1)
# 右侧序列继续排序
quick_sort(nums, i+1, end)
return nums
7. 归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个典型的应用。它的基本操作是:将已有的子序列合并,达到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
归并排序其实要做两件事:
- 分解----将序列每次折半拆分
- 合并----将划分后的序列段两两排序合并
因此,归并排序实际上就是两个操作,拆分+合并
如何合并?
nums[:mid]为第一段,nums[mid:]为第二段,并且两端已经有序,现在我们要将两端合成达到nums[]并且也有序。
- 首先依次从第一段与第二段中取出元素比较,将较小的元素赋值给result[]
- 重复执行上一步,当某一段赋值结束,则将另一段剩下的元素赋值给result[]
- 返回result[]即可。
如何分解?
在这里,我们采用递归的方法,首先将待排序列分成A,B两组;然后重复对A、B序列
分组;直到分组后组内只有一个元素,此时我们认为组内所有元素有序,则分组结束。
代码实现:
# 归并排序
# 这是合并的函数
def merge(left, right):
result = []
# 从两个有顺序的列表里边依次取数据比较后放入result
# 每次我们分别拿出两个列表中最小的数比较,把较小的放入result
while (len(left) > 0) and (len(right) > 0):
# 为了保持稳定性,当遇到相等的时候优先把
# 左侧的数放进结果列表,因为left本来也是大数列中比较靠左的
if left[0] <= right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
result += left
result += right
# while循环出来之后 说明其中一个数组没有数据了,
# 我们把另一个数组添加到结果数组后面
return result
# 归并排序的函数
def merge_sort(nums):
# 不断递归调用自己一直到拆分成成单个元素的
# 时候就返回这个元素,不再拆分了
if len(nums) == 1:
return nums
# 取拆分的中间位置
mid = len(nums) // 2
# 拆分过后左右两侧子串
left = nums[:mid]
rigt = nums[mid:]
# 对拆分过后的左右再拆分 一直到只有一个元素为止
# 最后一次递归时候ll和lr都会接到一个元素的列表
ll = merge_sort(left)
# ll一定会得到已经排好序的左序列
lr = merge_sort(rigt)
# lr得到排好序的右序列
# 我们对返回的两个拆分结果进行排序后合并再返回正确顺序的子列表
# 这里我们调用另一个函数帮助我们按顺序合并ll和lr
return merge(ll, lr)
8. 基数排序
核心思想:通过序列中各个元素的值,对排序的N个元素进行若干趟的“分配”与“收集”来实现排序。
- 分配:我们将L[i]中的元素取出,首先确定其个位上的数字,根据该数字分配到与之序号相同的桶中
- 收集:当序列中所有的元素都分配到对应的桶中,再按照顺序依次将桶中的元素收集形成新的一个待排序列L[ ]
对新形成的序列L[]重复执行分配和收集元素中的十位、百位...直到分配完该序列中的最高位,则排序结束
“基数排序”的展示,我们可以清楚的看到整个实现的过程:
代码实现:
#************************基数排序****************************
# 基数排序
def radix_sort(nums):
max_num = max(nums)
pos = len(str(max_num)) # 获取最大数的位数
buckets = [[] for i in range(10)] # 构建10个桶
# 从低位到高位依次执行循环
for i in range(pos):
# 对序列的每一个数字进行操作
for num in nums:
# 获取每个数字的基数
radix = (num // (10 ** i)) % 10
# 将数字放到基数对应的桶中
buckets[radix].append(num)
# 将桶中的元素按顺序放回原数列
idx = 0
for bt in range(10):
while len(buckets[bt]) > 0:
nums[idx] = buckets[bt].pop(0)
idx += 1
return nums
性能测试
运行时间对比(以sort()函数为参照):
- 1W个数据
sort:0.0019979476928710938
直接插入排序:9.216700553894043
希尔排序:0.13592171669006348
简单选择排序:4.676285028457642
堆排序:0.0939633846282959
冒泡排序:12.259912252426147
快速排序:0.03697681427001953
归并排序:0.0799551010131836
基数排序:0.0559844970703125
- 10W个数据
sort:0.041976213455200195
直接插入排序:1056.8331136703491
希尔排序:2.1497597694396973
简单选择排序:614.0669178962708
堆排序:1.3172402381896973
冒泡排序:1398.4518978595734
快速排序:0.448758602142334
归并排序:2.179725408554077
基数排序:0.9644415378570557
从运行结果上来看:
- sort 是真的快:先快速排序,超过递归层数阈值后堆排序,剩余的插入。
- 快速排序、堆排序、归并排序、基数排序也非常快。
2、三大查找
三大查找参考:https://www.cnblogs.com/lsqin/p/9342929.html
1. 二分查找
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
其基本思想是:首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则要找的元素一定在左子表中,则继续对左子表进行折半查找;若中间位置记录的关键字小于查找关键字,则要找的元素一定在右子表中,则继续对右子表进行折半查找。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
最优时间复杂度:O(1),最坏时间复杂度:O(logn)
代码实现:
# 递归解决二分查找
def binary_search_rec(nums, data):
length = len(nums)
if length < 1:
return False
mid = length // 2
if nums[mid] > data:
return binary_search_rec(nums[0:mid], data)
elif nums[mid] < data:
return binary_search_rec(nums[mid+1:], data)
else:
return mid
# 非递归解决二分查找
def binary_search(nums, data):
length = len(nums)
first = 0
last = length - 1
while first <= last:
mid = (last + first) // 2
if nums[mid] > data:
last = mid - 1
elif nums[mid] < data:
first = mid + 1
else:
return mid
return False
2. 分块查找/索引查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。要求是顺序表,将待查的元素均匀地分成块,块间按大小排序,块内不排序,必须满足分在第一块中的任意数都小于第二块中的所有数。先顺序查找已在已建好的索引表中查出key所在的块中,再在块中顺序查找key。所以要建立一个块的最大关键字表,成为索引表。
算法思想:
- 将n个数据元素"按块有序"划分为m块(m ≤ n);
- 每一块中的结点不必有序,但块与块之间必须"按块有序";
- 即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;
- 而第2块中任一元素又都必须小于第3块中的任一元素,……
算法流程:
- 先选取各块中的最大关键字构成一个索引表;
- 先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;
- 然后在已确定的块中用顺序法进行查找
时间复杂度:O(log(m)+N/m)
3. 哈希查找
哈希表就是一种以键-值(key-indexed) 存储数据的结构,只要输入待查找的值即key,即可查找到其对应的值。
算法思想
哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:把键处理后作为索引,值即为原键值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。简单的讲,就是对原数组的所有数据进行一个编码,存放到原数组中的编码位置,查找时只需将查找值编码后找到对应的值即可。
算法流程
1)用给定的哈希函数构造哈希表;
2)根据选择的冲突处理方法解决地址冲突;常见的解决冲突的方法:拉链法和线性探测法。
3)在哈希表的基础上执行哈希查找。
复杂度分析
单纯论查找复杂度:对于无冲突的Hash表而言,查找复杂度为O(1)(注意,在查找之前我们需要构建相应的Hash表)。
算法实现:
class HashTable:
def __init__(self):
self.elem = [] # 使用list数据结构作为哈希表元素保存方法
self.count = 0 # 最大表长
def insert_hash(self, key):
"""插入关键字到哈希表内"""
address = key % self.count # 求散列地址,散列函数采用除留余数法,
# 数组有多长就对应最大有多少种索引值,刚好可以存放所有数据
while self.elem[address]: # 当前位置已经有数据了,发生冲突。
address = (address + 1) % self.count # 线性探测下一地址是否可用
self.elem[address] = key # 没有冲突则直接保存。
def search_hash(self, nums, key):
# 创建hash表
self.count = len(nums)
self.elem = [None for i in range(len(nums))]
for num in nums:
self.insert_hash(num)
"""查找关键字,返回布尔值"""
star = address = key % self.count
while self.elem[address] != key:
address = (address + 1) % self.count
if not self.elem[address] or address == star: # 说明没找到或者循环到了开始的位置
return False
return True