YOLOv5改进系列(29)——添加DilateFormer(MSDA)注意力机制(中科院一区顶刊|即插即用的多尺度全局注意力机制)


 【YOLOv5改进系列】前期回顾:
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
YOLOv5改进系列(2)——添加CBAM注意力机制
YOLOv5改进系列(3)——添加CA注意力机制
YOLOv5改进系列(4)——添加ECA注意力机制
YOLOv5改进系列(5)——替换主干网络之 MobileNetV3
YOLOv5改进系列(6)——替换主干网络之 ShuffleNetV2
YOLOv5改进系列(7)——添加SimAM注意力机制
YOLOv5改进系列(8)——添加SOCA注意力机制
YOLOv5改进系列(9)——替换主干网络之EfficientNetv2
YOLOv5改进系列(10)——替换主干网络之GhostNet
YOLOv5改进系列(11)——添加损失函数之EIoU、AlphaIoU、SIoU、WIoU
YOLOv5改进系列(12)——更换Neck之BiFPN
YOLOv5改进系列(13)——更换激活函数之SiLU,ReLU,ELU,Hardswish,Mish,Softplus,AconC系列等
YOLOv5改进系列(14)——更换NMS(非极大抑制)之 DIoU-NMS、CIoU-NMS、EIoU-NMS、GIoU-NMS 、SIoU-NMS、Soft-NMS
YOLOv5改进系列(15)——增加小目标检测层
YOLOv5改进系列(16)——添加EMA注意力机制(ICASSP2023|实测涨点)
YOLOv5改进系列(17)——更换IoU之MPDIoU(ELSEVIER 2023|超越WIoU、EIoU等|实测涨点)
YOLOv5改进系列(18)——更换Neck之AFPN(全新渐进特征金字塔|超越PAFPN|实测涨点)
YOLOv5改进系列(19)——替换主干网络之Swin TransformerV1(参数量更小的ViT模型)
YOLOv5改进系列(21)——替换主干网络之RepViT(清华 ICCV 2023|最新开源移动端ViT)
YOLOv5改进系列(22)——替换主干网络之MobileViTv1(一种轻量级的、通用的移动设备 ViT)
YOLOv5改进系列(23)——替换主干网络之MobileViTv2(移动视觉 Transformer 的高效可分离自注意力机制)
YOLOv5改进系列(24)——替换主干网络之MobileViTv3(移动端轻量化网络的进一步升级)
YOLOv5改进系列(25)——添加LSKNet注意力机制(大选择性卷积核的领域首次探索)
YOLOv5改进系列(26)——添加RFAConv注意力卷积(感受野注意力卷积运算)
YOLOv5改进系列(27)——添加SCConv注意力卷积(CVPR 2023|即插即用的高效卷积模块)
YOLOv5改进系列(28)——添加DSConv注意力卷积(ICCV 2023|用于管状结构分割的动态蛇形卷积)

目录
一、DilateFormer介绍
1.1 DilateFormer简介
1.2 DilateFormer网络结构
① DilateFormer
② MSDA
二、具体添加方法
2.1 添加顺序
2.2 具体添加步骤
第①步:在common.py中添加DilateFormer模块
第②步:修改yolo.py文件
第③步:创建自定义的yaml文件
第④步:验证是否加入成功
本人YOLOv5系列导航

一、DilateFormer介绍
学习资料:
- 论文题目:《DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition》
- 论文地址:https://arxiv.org/abs/2302.01791
- 源码地址:https://github.com/abhinavsagar/mssa
1.1 DilateFormer简介
背景
ViT 模型在计算复杂性和感受野大小之间的权衡上存在矛盾:
- 具体来说,ViT 模型使用全局注意力机制,能够在任意图像块之间建立长远距离上下文依赖关系,但是全局感受野带来的是平方级别的计算代价。
- 同时,在浅层特征上,直接进行全局依赖性建模可能存在冗余,因此是没必要的。
本文方法
(1)多尺度空洞注意力(MSDA)
- MSDA 能够模拟小范围内的局部和稀疏的图像块交互
- 在浅层次上,注意力矩阵具有局部性和稀疏性两个关键属性
- 这表明在浅层次的语义建模中,远离查询块的块大部分无关
- 因此,全局注意力模块中存在大量的冗余。
(2)DilateFormer
- 在底层阶段堆叠 MSDA 块
- 在高层阶段使用全局多头自注意力块
- 这样的设计使得模型能够在处理低级信息时,充分利用局部性和稀疏性,而在处理高级信息时,又能模拟远距离依赖
实现效果
- 论文通过在不同的视觉任务上进行实验,发现 DilateFormer 模型取得了很好的效果。
- 在 ImageNet-1K 分类任务上,与现有最优秀的模型相比,DilateFormer 模型的性能相当,但所需的FLOPs(浮点运算次数)减少了70%。
- 在其它的视觉任务,如 COCO 对象检测/实例分割任务和 ADE20K 语义分割任务,DilateFormer 模型同样取得了优秀的表现。
1.2 DilateFormer网络结构
① DilateFormer

如上图所示,DilateFormer的整体架构主要由四个阶段构成:
- 在第一阶段和第二阶段,使用 MSDA
- 在第三阶段和第四阶段,使用普通的多头自注意力(MHSA)
对于图像输入:DilateFormer 首先使用重叠的分词器进行 patch 嵌入,然后通过交替控制卷积核的步长大小(1或2)来调整输出特征图的分辨率。
对于前一阶段的 patches,采用了一个重叠的下采样器,具有重叠的内核大小为 3,步长为 2。
整个模型的每一部分都使用了条件位置嵌入(CPE)来使位置编码适应不同分辨率的输入。
代码:
class DilateBlock(nn.Module):
"Implementation of Dilate-attention block"
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,
drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, dilation=[1, 2, 3],
cpe_per_block=False):
super().__init__()
self.dim = dim # 表示输入特征的维度
self.num_heads = num_heads # 表示多头注意力机制中的注意力头数
self.mlp_ratio = mlp_ratio # MLP(多层感知机)隐藏层维度与输入维度之比
self.kernel_size = kernel_size
self.dilation = dilation # 卷积核的膨胀率,指定每一层的膨胀率
self.cpe_per_block = cpe_per_block # 是否在每个块中使用位置嵌入
if self.cpe_per_block:
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = MultiDilatelocalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, kernel_size=kernel_size, dilation=dilation)
'''
: qkv_bias:是否允许注意力机制中的查询、键、值的偏置。
: qk_scale:注意力机制中查询和键的缩放因子。
: drop:MLP中的dropout概率。
: attn_drop:注意力机制中的dropout概率。
'''
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
def forward(self, x):
if self.cpe_per_block:
x = x + self.pos_embed(x)
x = x.permute(0, 2, 3, 1)
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.permute(0, 3, 1, 2)
#B, C, H, W
return x
过程如下:
- 首先,如果启用了位置嵌入(
cpe_per_block为true),则将输入张量与通过nn.Conv2d实现的位置嵌入相加。 - 接着,将输入张量维度进行调整,将通道维度放到最后。
- 然后,通过多头膨胀局部注意力机制处理输入,再通过MLP处理上一步的输出。
- 最后,再次调整张量维度,并返回处理后的结果。
② MSDA
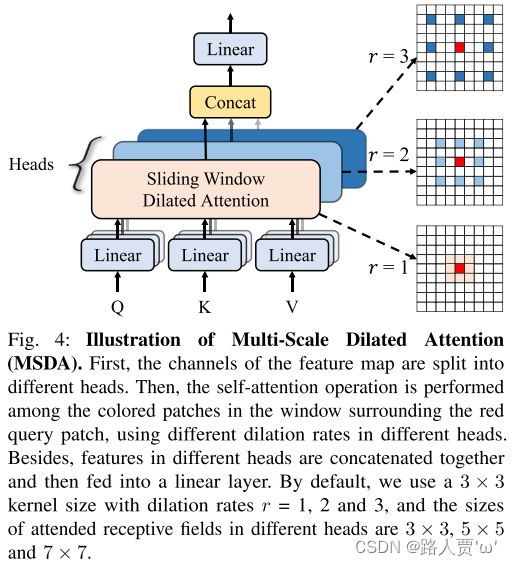
MSAD 模块是DilateFormer 的核心部分。
如上图所示,MSDA 模块同样采用多头的设计:将特征图的通道分为 n 个不同的头部,并在不同的头部使用不同的空洞率执行滑动窗口膨胀注意力(SWDA)。
目的:这样可以在被关注的感受野内的各个尺度上聚合语义信息,并有效地减少自注意力机制的冗余,无需复杂的操作和额外的计算成本。
具体的操作如下:
- 对于每个头部,都会有一个独立的膨胀率

- 从特征图中获取切片
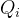 ,
, ,
, ,执行 SWDA,得到输出
,执行 SWDA,得到输出
- 将所有头部的输出连接在一起,然后通过一个线性层进行特征聚合
代码:
class DilateAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):
super().__init__()
self.head_dim = head_dim # 注意力头的维度
self.scale = qk_scale or head_dim ** -0.5 # 查询和键的缩放因子,默认为 head_dim ** -0.5。
self.kernel_size=kernel_size
self.unfold = nn.Unfold(kernel_size, dilation, dilation*(kernel_size-1)//2, 1)
self.attn_drop = nn.Dropout(attn_drop) # 注意力机制中的dropout概率
def forward(self,q,k,v):
#B, C//3, H, W
B,d,H,W = q.shape
q = q.reshape([B, d//self.head_dim, self.head_dim, 1 ,H*W]).permute(0, 1, 4, 3, 2) # B,h,N,1,d
k = self.unfold(k).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 2, 3) #B,h,N,d,k*k
attn = (q @ k) * self.scale # B,h,N,1,k*k
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
v = self.unfold(v).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 3, 2) # B,h,N,k*k,d
x = (attn @ v).transpose(1, 2).reshape(B, H, W, d)
return x
class MultiDilatelocalAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0.,proj_drop=0., kernel_size=3, dilation=[1, 2, 3]):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.dilation = dilation
self.kernel_size = kernel_size
self.scale = qk_scale or head_dim ** -0.5
self.num_dilation = len(dilation)
assert num_heads % self.num_dilation == 0, f"num_heads{num_heads} must be the times of num_dilation{self.num_dilation}!!"
self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)
self.dilate_attention = nn.ModuleList(
[DilateAttention(head_dim, qk_scale, attn_drop, kernel_size, dilation[i])
for i in range(self.num_dilation)])
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
x = x.permute(0, 3, 1, 2)# B, C, H, W
qkv = self.qkv(x).reshape(B, 3, self.num_dilation, C//self.num_dilation, H, W).permute(2, 1, 0, 3, 4, 5)
#num_dilation,3,B,C//num_dilation,H,W
x = x.reshape(B, self.num_dilation, C//self.num_dilation, H, W).permute(1, 0, 3, 4, 2 )
# num_dilation, B, H, W, C//num_dilation
for i in range(self.num_dilation):
x[i] = self.dilate_attention[i](qkv[i][0], qkv[i][1], qkv[i][2])# B, H, W,C//num_dilation
x = x.permute(1, 2, 3, 0, 4).reshape(B, H, W, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class DilateAttention
- 首先,对输入的
q、k、v进行一些预处理。 - 然后,将
q和k进行矩阵乘法,并使用缩放因子进行缩放,得到的矩阵表示注意力分布。 - 接着,对注意力分布进行 softmax、dropout 操作,将注意力分布与
v进行矩阵乘法。 - 最后,通过一系列的维度调整得到输出张量
x。
class MultiDilatelocalAttention
- 首先,对输入张量进行维度调整,将通道维度放到第二个位置。
- 然后,使用一个卷积层
self.qkv对输入张量进行处理,得到包含查询、键、值的张量,再进行维度调整。 - 接着,使用一个
nn.ModuleList包含多个DilateAttention模块,每个模块对输入进行多头膨胀局部注意力机制的处理。 - 最后,将处理后的张量经过全连接层和dropout层,得到最终的输出。
二、具体添加方法
2.1 添加顺序
(1)models/common.py --> 加入新增的网络结构
(2) models/yolo.py --> 设定网络结构的传参细节,将DilateFormer类名加入其中。(当新的自定义模块中存在输入输出维度时,要使用qw调整输出维度)
(3) models/yolov5*.yaml --> 新建一个文件夹,如yolov5s_DilateFormer.yaml,修改现有模型结构配置文件。(当引入新的层时,要修改后续的结构中的from参数)
(4) train.py --> 修改‘--cfg’默认参数,训练时指定模型结构配置文件
2.2 具体添加步骤
第①步:在common.py中添加DilateFormer模块
将下面的DilateFormer代码复制粘贴到common.py文件的末尾。
import torch
import torch.nn as nn
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DilateAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):
super().__init__()
self.head_dim = head_dim
self.scale = qk_scale or head_dim ** -0.5
self.kernel_size=kernel_size
self.unfold = nn.Unfold(kernel_size, dilation, dilation*(kernel_size-1)//2, 1)
self.attn_drop = nn.Dropout(attn_drop)
def forward(self,q,k,v):
#B, C//3, H, W
B,d,H,W = q.shape
q = q.reshape([B, d//self.head_dim, self.head_dim, 1 ,H*W]).permute(0, 1, 4, 3, 2) # B,h,N,1,d
k = self.unfold(k).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 2, 3) #B,h,N,d,k*k
attn = (q @ k) * self.scale # B,h,N,1,k*k
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
v = self.unfold(v).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 3, 2) # B,h,N,k*k,d
x = (attn @ v).transpose(1, 2).reshape(B, H, W, d)
return x
class MultiDilatelocalAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, dim, num_heads=4, qkv_bias=False, qk_scale=None,
attn_drop=0.,proj_drop=0., kernel_size=3, dilation=[1, 2]):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.dilation = dilation
self.kernel_size = kernel_size
self.scale = qk_scale or head_dim ** -0.5
self.num_dilation = len(dilation)
assert num_heads % self.num_dilation == 0, f"num_heads{num_heads} must be the times of num_dilation{self.num_dilation}!!"
self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)
self.dilate_attention = nn.ModuleList(
[DilateAttention(head_dim, qk_scale, attn_drop, kernel_size, dilation[i])
for i in range(self.num_dilation)])
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
x = x.permute(0, 3, 1, 2) # B, C, H, W
B, C, H, W = x.shape
qkv = self.qkv(x).reshape(B, 3, self.num_dilation, C //self.num_dilation, H, W).permute(2, 1, 0, 3, 4, 5)
#num_dilation,3,B,C//num_dilation,H,W
x = x.reshape(B, self.num_dilation, C//self.num_dilation, H, W).permute(1, 0, 3, 4, 2 )
# num_dilation, B, H, W, C//num_dilation
for i in range(self.num_dilation):
x[i] = self.dilate_attention[i](qkv[i][0], qkv[i][1], qkv[i][2])# B, H, W,C//num_dilation
x = x.permute(1, 2, 3, 0, 4).reshape(B, H, W, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class DilateBlock(nn.Module):
"Implementation of Dilate-attention block"
def __init__(self, dim, num_heads=4, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,
drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, dilation=[1, 2],
cpe_per_block=False):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.kernel_size = kernel_size
self.dilation = dilation
self.cpe_per_block = cpe_per_block
if self.cpe_per_block:
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = MultiDilatelocalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, kernel_size=kernel_size, dilation=dilation)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
x = x.permute(0, 3, 2, 1)
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x.permute(0, 3, 2, 1)
#B, C, H, W
return x
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class C3_DilateBlock(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(DilateBlock(c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))第②步:修改yolo.py文件
首先找到yolo.py里面parse_model函数的这一行
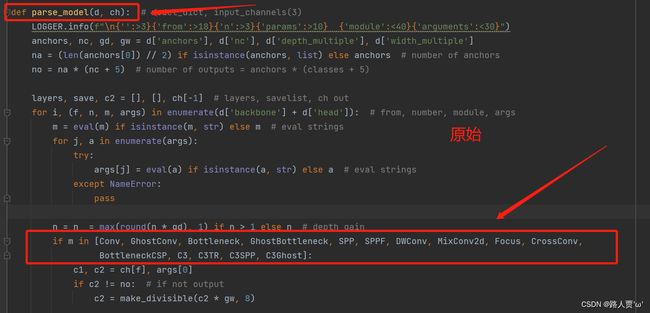
加入 DilateBlock、C3_DilateBlock 这两个模块
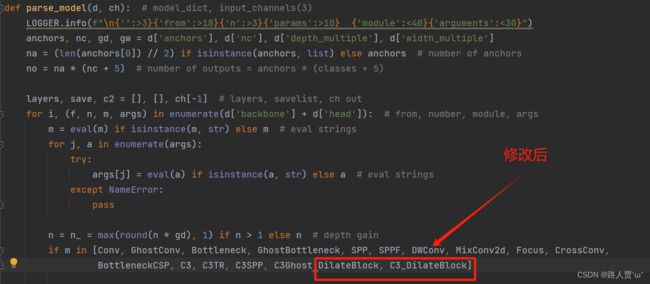
第③步:创建自定义的yaml文件
第1种,在SPPF前单独加一层
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 3, DilateBlock, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第2种,替换C3模块
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_DilateBlock, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_DilateBlock, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_DilateBlock, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_DilateBlock, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第④步:验证是否加入成功
运行yolo.py
第1种
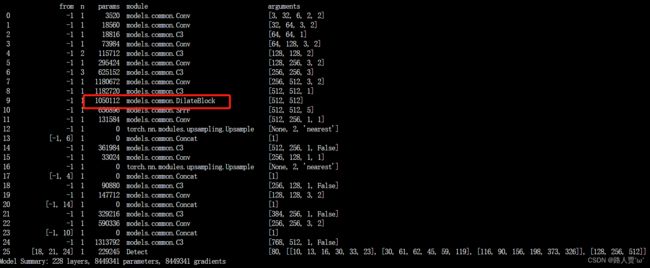 第2种
第2种
 这样就OK啦!
这样就OK啦!
本人YOLOv5系列导航
YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
YOLOv5入门实践系列:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(3)——手把手教你划分自己的数据集
YOLOv5入门实践(4)——手把手教你训练自己的数据集
YOLOv5入门实践(5)——从零开始,手把手教你训练自己的目标检测模型(包含pyqt5界面)
