MyBatis映射文件
一、映射文件的SQL标签
再映射文件中存在9大顶层的sql标签:
SQL拼接与操作:select、delete、update、insert、sql (include)
缓存:cache、cache-ref
参数映射:parameterMap (该标签已被废除,关于参数的映射可以使用行内参数映射)
解决映射:resultMap
1、OGNL表达式与#{}、${}
OGNL表达式的使用
它是 apache 提供的一种表达式语言,全称是: Object Graphic Navigation Language 对象图导航语言 。
它是按照一定的语法格式来获取数据的。 语法格式就是使用 #{对象.对象}的方式。
#{user.username}它会先去找 user 对象,然后在 user 对象中找到 username 属性,并调用getUsername()方法把值取出来。
但是我们在 parameterType 属性上指定了实体类名称,所以可以省略 user. 而直接写 username。
#{}、${}区别
#{}表示一个占位符:通过#{}占位符实现想propreStatements填充占位符,可以自动进行JDBC类型和Java类型的转换,可以有效防止sql注入, {}里的值可以是简单类型值或pojo类型值,parameterType是简单类型值且只有一个参数,则#{xxx},xxx可以是value或任意值。
${}表示一个sql拼接:可以将传入的内容拼接在sql中且不进行jdbc类型的转换,{}里的值可以是简单类型值或pojo类型值,parameterType是简单类型值且只有一个参数,则${xxx},xxx只能是Value。
使用${}会产生sql注入的风险,但可以实现动态表与动态列名的替换:
@Select("select * from user where ${column} = #{value}")
User findByColumn(@Param("column") String column, @Param("value") String value);
特别注意的是,${xxx} 最终拼接的值并不会带 '' ,此时如果你插入元素类型为String,对应的数据库类型为varchar,此时会报错,因为该字符串没带''
2、获取参数值
单参数情况:
1、#{xxxx}:由于只有一个参数,因此可以xxx里面的内容可以是随便值
2、MyBatis在3.4.2版本之前,传递参数支持使用#{0} - #{n};在3.4.2及之后版本,没有使用@param注解的情况下,传递参数需要使用#{arg0}-#{argn}或者#{param1}-#{paramn},按照顺序拿
3、使用@param(“xxx”)指定参数名称,通过#{xxx}取值
多参数情况:
参考情况2、3.
3、select
标签属性如下:
id |
在命名空间中唯一的标识符,可以被用来引用这条语句。 |
|---|---|
parameterType |
将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
| 用于引用外部 parameterMap 的属性,目前已被废弃。请使用行内参数映射和 parameterType 属性。 | |
resultType |
期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。 |
resultMap |
对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。 |
flushCache |
将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。 |
useCache |
将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true。 |
timeout |
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
fetchSize |
这是一个给驱动的建议值,尝试让驱动程序每次批量返回的结果行数等于这个设置值。 默认值为未设置(unset)(依赖驱动)。 |
statementType |
可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
resultSetType |
FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖数据库驱动)。 |
databaseId |
如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
resultOrdered |
这个设置仅针对嵌套结果 select 语句:如果为 true,将会假设包含了嵌套结果集或是分组,当返回一个主结果行时,就不会产生对前面结果集的引用。 这就使得在获取嵌套结果集的时候不至于内存不够用。默认值:false。 |
resultSets |
这个设置仅适用于多结果集的情况。它将列出语句执行后返回的结果集并赋予每个结果集一个名称,多个名称之间以逗号分隔。 |
行内参数映射
行内参数映射指的是在#{xxx}里面定义的参数,比如,指定某个属性使用特定的typehandler,具体可查看示例。
几乎总是可以根据参数对象的类型确定 javaType,除非该对象是一个 HashMap。这个时候,你需要显式指定 javaType 来确保正确的类型处理器(TypeHandler)被使用。
JDBC 要求,如果一个列允许使用 null 值,并且会使用值为 null 的参数,就必须要指定 JDBC 类型(jdbcType)---- 一个例子是,当插入一条数据时,如果你插入了一条数据时,数据库中某一列允许为null值,但该列对应的参数为null值时,不指定jdbcType就会报错。
MyBatis官方
示例:
更新Phone信息,type字段存储enum的ordinal值,使用EnumOrdinalTypeHandler处理器来处理,而不是使用默认的EnumTypeHandler来存储name值。
1、实体类
public enum PhoneTypeEnum {
TYPE1("中国移动"),
TYPE2("中国联通");
private String name;
PhoneTypeEnum(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Phone {
private String id;
private String phone;
private PhoneTypeEnum type;
}
2、映射文件:
<update id="updateById" parameterType="phone">
UPDATE phone
SET phone = #{phone}, type = #{type, typeHandler = org.apache.ibatis.type.EnumOrdinalTypeHandler,
javaType = com.bihai.mybatis_study.bean.PhoneTypeEnum, jdbcType = VARCHAR}
WHERE id = #{id}
update>
说明:
#{type, xxx}里面指定的就是行内参数,具体可以使用那些行内参数可以参考#parameterMap的子标签parameter可设置的属性
<parameterMap id="" type="">
<parameter property="" typeHandler="" javaType="" jdbcType="" resultMap="" mode="" scale="">parameter>
parameterMap>
注意:
由于在数据库中存储的是ordinal值,因此你查询的时候也要使用对应的typeHandler,代码如下:
<resultMap id="resultMap" type="phone">
<id property="id" column="id"></id>
<result property="phone" column="phone"></result>
<result property="type" column="type"
jdbcType="VARCHAR"
javaType="com.bihai.mybatis_study.bean.PhoneTypeEnum"
typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"></result>
</resultMap>
<select id="selectById" resultMap="resultMap">
SELECT * FROM phone WHERE id = ${id}
</select>
小技巧:
jdbcType可设置的类型在org.apache.ibatis.type.JdbcType中定义。
resultSetType
属性值可以为下面三种:
- FORWARD_ONLY,只允许游标向前访问;
- SCROLL_SENSITIVE,允许游标双向滚动,但不会及时更新数据,也就是说如果数据库中的数据被修改过,并不会在 resultSet 中及时更新出来;
- SCROLL_INSENSITIVE ,允许游标双向滚动,如果数据库中的数据被修改过,会及时更新到 resultSet;
常见的JDBC 见过的结果集读取:
// 允许滚动游标索引结果集
while( rs.next() ){
rs.getString("name");
}
// 当然也支持游标定位到最后一个位置
rs.last();
// 向后滚动
rs.previous();
4、update、insert、delete
属性列表如下:
<insert
id="insertUser"
parameterType="domain.vo.User"
flushCache="true"
statementType="PREPARED"
keyProperty=""
keyColumn=""
useGeneratedKeys=""
timeout="20">
<update
id="updateUser"
parameterType="domain.vo.User"
flushCache="true"
statementType="PREPARED"
timeout="20">
<delete
id="deleteUser"
parameterType="domain.vo.User"
flushCache="true"
statementType="PREPARED"
timeout="20">
| 属性 | 描述 |
|---|---|
id |
在命名空间中唯一的标识符,可以被用来引用这条语句。 |
parameterType |
将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
parameterMap |
用于引用外部 parameterMap 的属性,目前已被废弃。请使用行内参数映射和 parameterType 属性。 |
flushCache |
将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:(对 insert、update 和 delete 语句)true。 |
timeout |
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
statementType |
可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
useGeneratedKeys |
(仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false。 |
keyProperty |
(仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
keyColumn |
(仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号,分隔多个属性名称。 |
databaseId |
如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
useGeneratedKeys、keyProperty、keyColumn
自动生成主键值:
方式一:
对于MySQL、SQL Server等支持自增主键,此时只需要设置useGeneratedKeys,并keyColumn 设置为目标属性即可:
<insert id="insertUser" useGeneratedKeys="true"
keyColumn="id">
insert into t_user (name) values (#{name})
</insert>
方式二:
对于不支持自动生成主键列的数据库和可能不支持自动生成主键的 JDBC 驱动,MyBatis 有另外一种方法来生成主键:
<insert id="insertUser">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
</selectKey>
insert into t_user (id, name)
values (#{id}, #{name})
</insert>
selectKey 元素描述如下:
<selectKey keyProperty="id" resultType="int" order="BEFORE" statementType="PREPARED">
selectKey 中的 order 属性有 2 个选择:BEFORE 和 AFTER 。
- BEFORE:表示先执行 selectKey 的语句,然后将查询到的值设置到 JavaBean 对应属性上,然后再执行 insert 语句。
- AFTER:表示先执行 AFTER 语句,然后再执行 selectKey 语句,并将 selectKey 得到的值设置到 JavaBean 中的属性。上面示例中如果改成 AFTER,那么插入的 id 就会是空值,但是返回的 JavaBean 属性内会有值。
主键回填:
MyBatis支持主键的回填,可以是JavaBean,也可以是JavaBean的集合 (List)
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
insert into t_user (name) values (#{name})
insert>
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
insert into t_user (name) values
<foreach item="item" collection="list" separator="," open = "(" close = ")">
#{item.name}
foreach>
insert>
5、cache 与 cache-ref
MyBatis中的缓存分为一级缓存与二级缓存,其中一级缓存是SqlSession级别的缓存,而二级缓存是Mapper级别的缓存,多个sqlSession共享二级缓存。当读取数据时遵循一下顺序:二级缓存 -> 一级缓存 -> 数据库。
一级缓存清空:
sqlSession 去执行 commit 操作(执行插入、更新、删除),清空 SqlSession 中的一级缓存,这样 做的目的为了让缓存中存储的是最新的信息,避免脏读。
二级缓存清空:
二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
使用二级缓存需要开启一下配置:
1、
<settings>
<setting name="cacheEnabled" value="true"/>
settings>
2、
<cache xxx>
....
cache>
cache
<cache
type = "xxx.xxx.xxxCache"
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
eviction:缓存的清楚策略,
- LRU – 最近最少使用:移除最长时间不被使用的对象。(默认值)
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
flushInterval:刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size:(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly:(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
自定义缓存
MyBatis运行实现你自己的缓存,或为其他第三方缓存方案创建适配器,来完全覆盖缓存行为。实现 org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器
public interface Cache {
String getId();
int getSize();
void putObject(Object key, Object value);
Object getObject(Object key);
boolean hasKey(Object key);
Object removeObject(Object key);
void clear();
}
设置属性,比如在Cache中需要设置属性,并提供了setxx方法,使用外部传值可以这样,并且支持${xxx},以便替换成在配置文件属性中定义的值(此处指的是mybatis-config中的properties设置的值):
<cache type="com.domain.something.MyCustomCache">
<property name="cacheFile" value="/tmp/my-custom-cache.tmp"/>
cache>
-----------
<cache type="com.domain.something.MyCustomCache">
<property name="cacheFile" value="${cache.file}"/>
cache>
从版本 3.4.2 开始,MyBatis 已经支持在所有属性设置完毕之后,调用一个初始化方法。需要实现org.apache.ibatis.builder.InitializingObject 接口
public interface InitializingObject {
void initialize() throws Exception;
}
注意:
对缓存的配置(如清除策略、可读或可读写等),不能应用于自定义缓存。
cache-ref
对某一命名空间的语句,只会使用该命名空间的缓存进行缓存或刷新。 通过cache-ref可以实现多个命名空间中共享相同的缓存配置和实例。
<cache-ref namespace="com.vo.UserMapper"/>
6、resultMap - 结果集映射
resultMap
<resultMap id="" type="" autoMapping="" extends="">
...
<resultMap/>
| 属性 | 描述 |
|---|---|
id |
当前命名空间中的一个唯一标识,用于标识一个结果映射。 |
type |
类的完全限定名, 或者一个类型别名(关于内置的类型别名,可以参考上面的表格)。 |
autoMapping |
如果设置这个属性,MyBatis 将会为本结果映射开启或者关闭自动映射。 这个属性会覆盖全局的属性 autoMappingBehavior。默认值:未设置(unset)。 |
extends |
支持继承,但很少用到 |
resultMap与constructor
构造方法注入允许你在初始化时为类设置属性的值,而不用暴露出公有方法。MyBatis 也支持私有属性和私有 JavaBean 属性来完成注入,但有一些人更青睐于通过构造方法进行注入。 constructor 元素就是为此而生的。
<resultMap id = "" type = "">
<constructor>
<idArg resultMap="" column="" jdbcType="" typeHandler="" javaType="" select="" columnPrefix="" name="">idArg>
<arg ...>arg>
constructor>
<resultMap/>
| 属性 | 描述 |
|---|---|
column |
数据库中的列名,或者是列的别名。一般情况下,这和传递给 resultSet.getString(columnName) 方法的参数一样。 |
javaType |
一个 Java 类的完全限定名,或一个类型别名(关于内置的类型别名,可以参考上面的表格)。 如果你映射到一个 JavaBean,MyBatis 通常可以推断类型。然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证行为与期望的相一致。 |
jdbcType |
JDBC 类型,所支持的 JDBC 类型参见这个表格之前的“支持的 JDBC 类型”。 只需要在可能执行插入、更新和删除的且允许空值的列上指定 JDBC 类型。这是 JDBC 的要求而非 MyBatis 的要求。如果你直接面向 JDBC 编程,你需要对可能存在空值的列指定这个类型。 |
typeHandler |
我们在前面讨论过默认的类型处理器。使用这个属性,你可以覆盖默认的类型处理器。 这个属性值是一个类型处理器实现类的完全限定名,或者是类型别名。 |
select |
用于加载复杂类型属性的映射语句的 ID,它会从 column 属性中指定的列检索数据,作为参数传递给此 select 语句。具体请参考关联元素。 |
resultMap |
结果映射的 ID,可以将嵌套的结果集映射到一个合适的对象树中。 它可以作为使用额外 select 语句的替代方案。它可以将多表连接操作的结果映射成一个单一的 ResultSet。这样的 ResultSet 将会将包含重复或部分数据重复的结果集。为了将结果集正确地映射到嵌套的对象树中,MyBatis 允许你 “串联”结果映射,以便解决嵌套结果集的问题。想了解更多内容,请参考下面的关联元素。 |
name |
构造方法形参的名字。从 3.4.3 版本开始,通过指定具体的参数名,你可以以任意顺序写入 arg 元素。参看上面的解释。 |
columnPrefix |
指定列名前缀 |
resultMap与id、result
属性字段的映射
<resultMap id = "" type = "">
<id property="" column="" javaType="" typeHandler="" jdbcType="">id>
<result ....>result>
<resultMap id = "" type = "">
resultMap与association、collection
延迟加载
即在需要用到数据时才加载,不需要用到数据时不加载,也称之为懒加载(按需加载)
例如:在加载用户信息时不一定要加载其所有的账户信息。
- 好处:
先从单表查询,在需要加载数据时再从与之相关联的表查询,与多表查询相比,速度有所提升。
- 坏处:
当有大批量的数据查询时,速度会变慢,会影响用户的体验。
- association和Collection自带延迟加载功能。
通常一对多,多对多采用延迟加载;多对一,一对一采用立即加载。
参考association的fetchType属性
entity
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Phone {
private String id;
private String phone;
private PhoneTypeEnum type;
private User user;
}
-------------------
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String id;
private String phoneId;
private String name;
private Integer age;
private List<Phone> phone;
}
N - 1、1 - 1
方式一:
查询phone对应的user,通过phoneId
<resultMap id="userPhoneListResultMap" type="phone">
<id column="id" property="id">id>
<result column="phone" property="phone">result>
<result property="type" column="type"
jdbcType="VARCHAR"
javaType="com.bihai.mybatis_study.bean.PhoneTypeEnum"
typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler">result>
<association property="user" column="id" select="selectUser" javaType="user" fetchType="lazy">association>
-----------------------------------------------------------------------
<select id="selectUser" resultType="user">
select * from user where phoneId = #{value};
select>
<select id="getUserPhoneList" resultMap="userPhoneListResultMap">
select * from phone;
select>
| 属性 | 描述 |
|---|---|
column |
数据库中的列名,或者是列的别名。一般情况下,这和传递给 resultSet.getString(columnName) 方法的参数一样。 注意:在使用复合主键的时候,你可以使用 column="{prop1=col1,prop2=col2}" 这样的语法来指定多个传递给嵌套 Select 查询语句的列名。这会使得 prop1 和 prop2 作为参数对象,被设置为对应嵌套 Select 语句的参数。 |
select |
用于加载复杂类型属性的映射语句的 ID,它会从 column 属性指定的列中检索数据,作为参数传递给目标 select 语句。 具体请参考下面的例子。注意:在使用复合主键的时候,你可以使用 column="{prop1=col1,prop2=col2}" 这样的语法来指定多个传递给嵌套 Select 查询语句的列名。这会使得 prop1 和 prop2 作为参数对象,被设置为对应嵌套 Select 语句的参数。 |
fetchType |
可选的。有效值为 lazy 和 eager。 指定属性后,将在映射中忽略全局配置参数 lazyLoadingEnabled,使用属性的值。 |
特别注意多参数情况,可以通过column="{prop1=col1,prop2=col2}指定。
缺点:尽管这样的查询进行延迟加载,当加载记录列表之后立刻就遍历列表以获取嵌套的数据,就会触发所有的延迟加载查询,性能可能会变得很糟糕。
方式二:
存储过程执行下面的查询并返回两个结果集。
select * from user where phoneId = #{id};
select * from phone where id = #{id};
<select id="getUserPhoneList" resultSets="phones,users" resultMap="userPhoneListResultMap" statementType="CALLABLE">
{call getPhoneAndUsers(#{id,jdbcType=VARCHAR,mode=IN})}
select>
<resultMap id="userPhoneListResultMap" type="phone">
<id column="id" property="id"></id>
<result column="phone" property="phone"></result>
<result property="type" column="type"
jdbcType="VARCHAR"
javaType="com.bihai.mybatis_study.bean.PhoneTypeEnum"
typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"></result>
<association javaType="user" property="user" resultSet = "users" column="id" foreignColumn = "phoneId"></association>
| 属性 | 描述 |
|---|---|
column |
当使用多个结果集时,该属性指定结果集中用于与 foreignColumn 匹配的列(多个列名以逗号隔开),以识别关系中的父类型与子类型。 |
foreignColumn |
指定外键对应的列名,指定的列将与父类型中 column 的给出的列进行匹配。 |
resultSet |
指定用于加载复杂类型的结果集名字。 |
方式三:
级联查询出结果,并使用resultMap来完成映射
<select id="getUserPhoneById" resultMap="userPhoneByIdResultMap">
SELECT p.id as phone_id,
phone,
type,
u.id as user_id,
name,
phoneId,
age
FROM phone p
LEFT JOIN user u
ON p.id = u.phoneId
WHERE p.id = #{value}
select>
-------------------------------------------------------
<resultMap id="userPhoneByIdResultMap" type="phone">
<id column="id" property="phone_id">id>
<result column="phone" property="phone">result>
<result property="type" column="type"
jdbcType="VARCHAR"
javaType="com.bihai.mybatis_study.bean.PhoneTypeEnum"
typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler">result>
<association property="user" column="id" javaType="user" resultMap="userResultMap">
association>
resultMap>
<resultMap id="userResultMap" type="user">
<id property="id" column="user_id">id>
<result property="name" column="name">result>
<result property="phoneId" column="phoneId">result>
<result property="age" column="age">result>
resultMap>
| 属性 | 描述 |
|---|---|
resultMap |
结果映射的 ID,可以将此关联的嵌套结果集映射到一个合适的对象树中。 它可以作为使用额外 select 语句的替代方案。它可以将多表连接操作的结果映射成一个单一的 ResultSet。这样的 ResultSet 有部分数据是重复的。 为了将结果集正确地映射到嵌套的对象树中, MyBatis 允许你“串联”结果映射,以便解决嵌套结果集的问题。使用嵌套结果映射的一个例子在表格以后。 |
columnPrefix |
当连接多个表时,你可能会不得不使用列别名来避免在 ResultSet 中产生重复的列名。指定 columnPrefix 列名前缀允许你将带有这些前缀的列映射到一个外部的结果映射中。 详细说明请参考后面的例子。 |
notNullColumn |
默认情况下,在至少一个被映射到属性的列不为空时,子对象才会被创建。 你可以在这个属性上指定非空的列来改变默认行为,指定后,Mybatis 将只在这些列非空时才创建一个子对象。可以使用逗号分隔来指定多个列。默认值:未设置(unset)。 |
autoMapping |
如果设置这个属性,MyBatis 将会为本结果映射开启或者关闭自动映射。 这个属性会覆盖全局的属性 autoMappingBehavior。注意,本属性对外部的结果映射无效,所以不能搭配 select 或 resultMap 元素使用。默认值:未设置(unset)。 |
方式四
依旧使用级联查询,并通过resultMap来建立映射关系,但并不分为两个resultMap
<select id="getUserPhoneById" resultMap="userPhoneByIdResultMap">
SELECT p.id as phone_id,
phone,
type,
u.id as user_id,
name,
phoneId,
age
FROM phone p
LEFT JOIN user u
ON p.id = u.phoneId
WHERE p.id = #{value}
select>
---------------------------------------------------
<resultMap id="userPhoneByIdResultMap" type="phone">
<id column="id" property="phone_id">id>
<result column="phone" property="phone">result>
<result property="type" column="type"
jdbcType="VARCHAR"
javaType="com.bihai.mybatis_study.bean.PhoneTypeEnum"
typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler">result>
<association property="user" javaType="user">
<id property="id" column="user_id">id>
<result property="name" column="name">result>
<result property="phoneId" column="phoneId">result>
<result property="age" column="age">result>
association>
resultMap>
1 - N、N - N
与N - 1、1 - 1的使用assocation类似,1 - N、N - N使用collection,collection其属性值大部分与assocation一样(加了个ofType - 表示集合的类型)。
7、discriminator - 鉴别器
有时候,一个数据库查询可能会返回多个不同的结果集(但总体上还是有一定的联系的)。 鉴别器(discriminator)元素就是被设计来应对这种情况的。
一个鉴别器的定义需要指定 column 和 javaType 属性。
如果它匹配任意一个鉴别器的 case,就会使用这个 case 指定的结果映射。 这个过程是互斥的,也就是说,剩余的结果映射将被忽略(最终只有一个会被选择)
<resultMap id="vehicleResult" type="Vehicle">
<id property="id" column="id" />
<result property="vin" column="vin"/>
<result property="year" column="year"/>
<result property="make" column="make"/>
<result property="model" column="model"/>
<result property="color" column="color"/>
<discriminator javaType="int" column="vehicle_type">
<case value="1" resultMap="carResult"/>
<case value="2" resultMap="truckResult"/>
<case value="3" resultMap="vanResult"/>
<case value="4" resultMap="suvResult"/>
discriminator>
resultMap>
---------------------------------------
更加简洁的
<resultMap id="vehicleResult" type="Vehicle">
<id property="id" column="id" />
<result property="vin" column="vin"/>
<result property="year" column="year"/>
<result property="make" column="make"/>
<result property="model" column="model"/>
<result property="color" column="color"/>
<discriminator javaType="int" column="vehicle_type">
<case value="1" resultType="carResult">
<result property="doorCount" column="door_count" />
case>
<case value="2" resultType="truckResult">
<result property="boxSize" column="box_size" />
<result property="extendedCab" column="extended_cab" />
case>
<case value="3" resultType="vanResult">
<result property="powerSlidingDoor" column="power_sliding_door" />
case>
<case value="4" resultType="suvResult">
<result property="allWheelDrive" column="all_wheel_drive" />
case>
discriminator>
resultMap>
8、sql
用于提取重复的sql片段,并且可以在 include 元素的 refid 属性或内部语句中使用属性值
<sql id="sometable">
${prefix}Table
sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
include>
select>
二、动态SQL
在编译阶段就能够确定sql主体的称之为静态sql,在编译阶段无法确定sql主体,需要在运行阶段才确定sql主体的称之为动态sql。MyBatis支持动态SQL、支持一下九种:
单分支判断:
多分支判断:
处理SQL拼接问题:
循环:
bind:
在XMLScriptBuilder中定义了动态sql的标签:
// XML脚本标签构建器
public class XMLScriptBuilder{
// 标签节点处理器池
private final Map<String, NodeHandler> nodeHandlerMap = new HashMap<>();
// 构造器
public XMLScriptBuilder() {
initNodeHandlerMap();
//... 其它初始化不赘述也不重要
}
// 初始化
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
}
1、if 标签
if用于单分支的判断,内嵌于 select / delete / update / insert 标签,结合test使用。
| 属性 | 作用 |
|---|---|
| test | 用于条件判断,支持ONGL表达式 |
<select id="findUser">
select * from User where 1=1
<if test=" age != null and age != ''">
and age > #{age}
</if>
<if test=" name != null or name != '' ">
and name like concat(#{name},'%')
</if>
</select>
2、choose、when、otherwise
这三者一起使用类似于Java的中switch - case - default,解释如下:
when的属性:
| 属性 | 作用 |
|---|---|
| test | 用于条件判断,支持ONGL表达式 |
<select id="findUser">
select * from User where 1=1
<choose>
<when test=" age != null ">
and age > #{age}
when>
<when test=" name != null ">
and name like concat(#{name},'%')
when>
<otherwise>
and sex = '男'
otherwise>
choose>
select>
3、foreach
用于批量操作遍历使用,用在比如批量插入、in、批量更新等。使用 foreach 标签时,需要对传入的 collection 参数(List/Map/Set 等)进行为空判断,否则动态 SQL 会出现语法异常。
foreach的属性:
| 属性 | 作用 |
|---|---|
| collection | 必填,Map 或者数组或者列表的属性名 |
| item | 变量名,值为遍历的每一个值(可以是对象或基础类型),如果是对象使用OGNL表达式取值即可 |
| index | 索引属性名,在遍历列表或数组时为当前索引值,当迭代的对象时 Map 类型时,该值为 Map 的键值(key) |
| open | 循环内容开头拼接的字符串,可以是空字符串 |
| close | 循环内容结尾拼接的字符串,可以是空字符串 |
| separator | 遍历元素的分隔符 |
为List时:
多参数情况:
1、直接使用属性名:
List<User> selectById(List<String> ids, String name);
<select id="selectById" parameterType="string" resultType="user">
SELECT * FROM user WHERE
<foreach collection="ids" item="e">
<if test = "e == '00001'">
id = #{e};
if>
foreach>
select>
2、使用paramx:List为第一个则是param1,为第二个则为param2,以此类推
<select id="selectById" parameterType="string" resultType="user">
SELECT * FROM user WHERE
<foreach collection="param1" item="e">
<if test = "e == '00001'">
id = #{e};
if>
foreach>
select>
3、使用@param:
List<User> selectById(@Param("idList") List<String> ids, String name);
<select id="selectById" parameterType="string" resultType="user">
SELECT * FROM user WHERE
<foreach collection="idList" item="e">
<if test = "e == '00001'">
id = #{e};
</if>
</foreach>
</select>
单参数情况:
除了上面三种外,当参数为List,且只有一个参数时,MyBatis会维护一个list,如下:
<select id="selectById" parameterType="string" resultType="user">
SELECT * FROM user WHERE
<foreach collection="list" item="e">
<if test = "e == '00001'">
id = #{e};
if>
foreach>
select>
当Array时:
多参数情况:
此时与当元素为List时一样,参考上面
单参数情况:
除了多参数情况外,单参数包含一种特殊情况,当参数为Array,且只有一个参数时,MyBatis会维护一个array,如下:
List<User> selectById(String[] ids);
<select id="selectById" parameterType="string" resultType="user">
SELECT * FROM user WHERE
<foreach collection="array" item="e">
<if test = "e == '00001'">
id = #{e};
if>
foreach>
select>
为map时:
需要注意的时属性index声明的变量表示key,item声明的变量表示value
多参数情况:
使用@Param、paramx | argx
单参数情况:
单参数下,当参数为Map,且只有一个参数时,可以使用_parameter
List<User> selectById(Map<String,String> ids);
<select id="selectById" parameterType="string" resultType="user">
SELECT * FROM user WHERE
<foreach collection="_parameter" item="e">
<if test = "e == '00001'">
id = #{e};
</if>
</foreach>
</select>
4、where
顶层的遍历标签,需要配合 if 标签使用,单独使用无意义,并且只会在子元素(如 if 标签)返回任何内容的情况下才插入 WHERE 子句。另外,若子句的开头为 “AND” 或 “OR”,where 标签也会将它替换去除。
<select id="findUser">
select * from User
<where>
<if test=" age != null ">
and age > #{age}
</if>
<if test=" name != null ">
and name like concat(#{name},'%')
</if>
</where>
</select>
建议在每个if子句的句首加and或or
注意:
如果在 where 标签之后添加了注释,那么当有子元素满足条件时,除了 < !-- --> 注释会被 where 忽略解析以外,其它注释例如 // 或 /**/ 或 – 等都会被 where 当成首个子句元素处理,导致后续真正的首个 AND 子句元素或 OR 子句元素没能被成功替换掉前缀,从而引起语法错误。
5、set
顶层的遍历标签,需要配合 if 标签使用,单独使用无意义,并且只会在子元素(如 if 标签)返回任何内容的情况下才插入 set 子句。另外,若子句的 开头或结尾 都存在逗号 “,” 则 set 标签都会将它替换去除。
<update id="updateUser">
update user
<set>
<if test="age !=null">
,age = #{age}
</if>
<if test="username !=null">
,username = #{username}
</if>
<if test="password !=null">
,password = #{password}
</if>
</set>
where id =#{id}
</update>
建议在每个句首或句末添加,
注意:
注意点同上
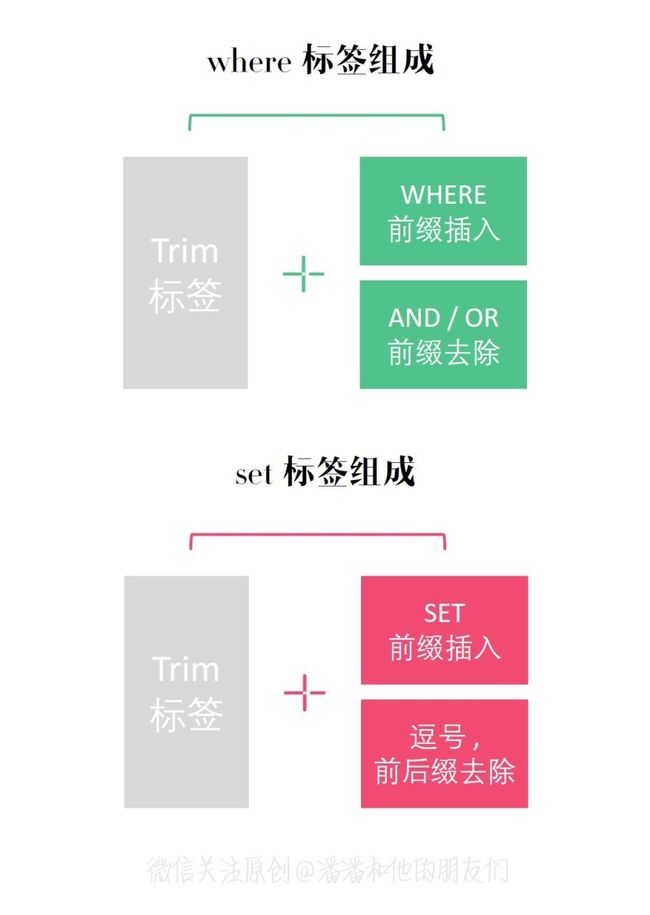
6、trim
where、set的实现都是基于trim的,功能也更加的强大
属性:
| 属性 | 描述 |
|---|---|
| prefix | 前缀,当 trim 元素内存在内容时,会给内容插入指定前缀 |
| suffix | 后缀,当 trim 元素内存在内容时,会给内容插入指定后缀 |
| prefixesToOverride | 前缀去除,支持多个(使用"|"),当 trim 元素内存在内容时,会把内容中匹配的前缀字符串去除。 |
| suffixesToOverride | 后缀去除,支持多个(使用"|"),当 trim 元素内存在内容时,会把内容中匹配的后缀字符串去除。 |
使用trim实现where:
<trim prefix="WHERE" prefixOverrides="AND |OR |AND\n|OR\n|AND\r|OR\r|AND\t|OR\t" >
...
trim>
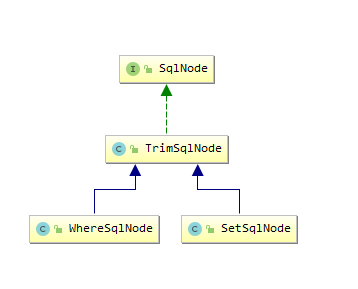
public class WhereSqlNode extends TrimSqlNode {
private static List<String> prefixList = Arrays.asList("AND ","OR ","AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
使用trim实现set:
<trim prefix="SET" prefixOverrides="," suffixOverrides=",">
trim>
public class SetSqlNode extends TrimSqlNode {
private static final List<String> COMMA = Collections.singletonList(",");
public SetSqlNode(Configuration configuration,SqlNode contents) {
super(configuration, contents, "SET", COMMA, null, COMMA);
}
}
7、bind
创建一个变量,并绑定到上下文,即供上下文使用,基本没什么用