mysql为什么要使用B+树实现索引?
关于这个问题,我们首先要弄明白两个问题:什么是索引?什么是B+树?
1、什么是索引?
索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据。
索引最形象的比喻就是图书的目录了。注意这里的大量,数据量大了索引才显得有意义,如果我想要在[1,2,3,4]中找到4这个数据,直接对全数据检索也很快,没有必要费力气建索引再去查找。
索引在mysql数据库中分三类:
B+树索引、Hash索引、全文索引
今天要介绍的是工作开发中最常接触到innodb存储引擎中的的B+树索引。
2、什么是B+树?
B+树的演化是由二叉查找树、二叉平衡树、B树三种数据结构来的。
1、二叉查找树
看这张图:

顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
特点:任何节点的左子节点的键值都小于当前节点的键值,任何节点的右子节点的键值都大于当前节点的键值。
**缺点:**如果二叉查找树变成了一个斜线上升或者下降的链表:

就会导致二叉树变得不平衡,树的高度太高了,导致查找效率不稳定。
为了解决这种问题,保证二叉树一直平衡,就要用到平衡二叉树。
2、平衡二叉树(AVL树)
特点:树的叶子节点都差不多深,有平衡之意。要求每个节点的左右子树的高度相差不能超过1。
下面是平衡二叉树和非平衡二叉树的对比:

平衡二叉树相对于二叉查找树来说,查找效率更稳定,总体的查询速度也更快。
**缺点:**平衡二叉树每个节点只存储一个键值和数据,当存储海量的数据时,二叉树的节点会非常多,高度非常高,查找效率会极其慢。
因为从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。 而如果我们用树这种数据结构作为索引的数据结构,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块。
而磁盘和内存相比,读取数据的速度要慢上百倍甚至万倍,所以查找效率极其慢。
3、B树(Balance Tree)
这是B树的结构图:

图中的p节点为指向子节点的指针,二叉查找树和平衡二叉树其实也有,因为图的美观性,被省略了。
图中的每个节点称为页,页就是我们上面说的磁盘块,在mysql中数据读取的基本单位都是页,所以我们这里叫做页更符合mysql中索引的底层数据结构。
特点:B树相对于平衡二叉树,每个节点存储了更多的键值和数据,并且每个节点拥有更多的子节点。
子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。
基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
4、B+树
B+树是对B树的进一步优化。让我们先来看下B+树的结构图:
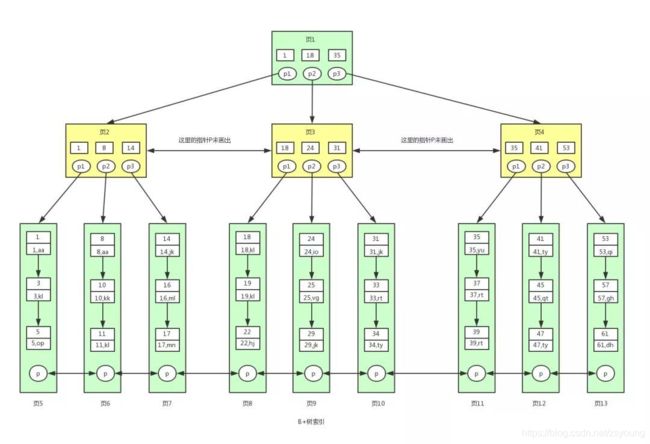
特点:
- B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。
- 因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的。
上图中的B+树索引就是innodb中B+树索引真正的实现方式,准确的说应该是聚集索引。
MyISAM中的B+树索引实现与innodb中的略有不同。在MyISAM中,B+树索引的叶子节点并不存储数据,而是存储数据的文件地址。
3、聚集索引 VS 非聚集索引
在MySQL中,B+树索引按照存储方式的不同分为聚集索引和非聚集索引。
这里我们着重介绍innodb中的聚集索引和非聚集索引。
- 聚集索引(聚簇索引):以innodb作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。这是因为innodb是把数据存放在B+树中的,而B+树的键值就是主键,在B+树的叶子节点中,存储了表中所有的数据。这种以主键作为B+树索引的键值而构建的B+树索引,我们称之为聚集索引。
趣谈编程注:换言之,在B+树中,叶子节点存储整条记录的数据,这样的索引为聚集索引。
- 非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引。非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
明白了聚集索引和非聚集索引的定义,我们应该明白这样一句话:数据即索引,索引即数据。
1、利用聚集索引查找数据

2、利用非聚集索引查找数据

在MyISAM中,聚集索引和非聚集索引的叶子节点都会存储数据的文件地址。
总结
- 索引是一种数据结构,用于在大量数据中快速定位到要查找到的数据
- B+树是由二叉查找树——平衡二叉树——B树——B+树演化而来的
- B+树非叶子节点上是不存储数据的,仅存储键值
- B+树索引就是innodb中B+树索引真正的实现方式,准确的说应该是聚集索引
- MyISAM中,聚集索引和非聚集索引的叶子节点都会存储数据的文件地址,先非聚集索引再聚集索引
- 数据即索引,索引即数据。
原文地址:https://cloud.tencent.com/developer/article/1543335