Python之PySpark简单应用
文章目录
- 一、介绍
-
- 1.准备工作
- 2. 创建SparkSession对象:
- 3. 读取数据:
- 4. 数据处理与分析:
- 5. 停止SparkSession:
- 二、示例
-
- 1.读取解析csv数据
- 2.解析计算序列数据map\flatmap
- 三、问题总结
-
- 1.代码问题
- 2.配置问题
一、介绍
PySpark是Apache Spark的Python API,它允许开发人员使用Python编写并运行分布式大数据处理应用程序。通过PySpark,开发人员可以利用Spark的强大功能和高性能,同时享受Python编程语言的灵活性和易用性。
1.准备工作
pip install pyspark
2. 创建SparkSession对象:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("example-app") \
.getOrCreate()
3. 读取数据:
df = spark.read.csv("test.csv", header=True)
4. 数据处理与分析:
result = df.groupBy("column").count().show()
5. 停止SparkSession:
spark.stop()
二、示例
1.读取解析csv数据
下面是一个简单的示例,演示了如何使用PySpark进行数据处理和分析:
from pyspark.sql import SparkSession
# 创建SparkSession对象
spark = SparkSession.builder.appName("example").getOrCreate()
# 读取CSV文件
df = spark.read.csv("C:/Users/39824/Desktop/test.csv", header=True)
# 对数据进行筛选和聚合操作
result = df.filter(df["age"] > 25).groupBy("department").count()
# 显示结果
result.show()
# 停止SparkSession
spark.stop()
在这个示例中,我们首先创建了一个SparkSession对象,然后使用该对象读取了一个CSV文件。接着,我们对数据进行了筛选和聚合操作,并最终显示了结果。最后,我们停止了SparkSession以释放资源。
输出:

2.解析计算序列数据map\flatmap
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("create rdd").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9])
rdd1 = rdd.map(lambda x: x * 10)
print(rdd1.collect())
rdd_str = sc.parallelize(["java.io.FileNotFoundException", "sc.setLogLevel(newLevel)", "hadoop.home.dir"])
rdd_str1 = rdd_str.map(lambda x: x.split("."))
print(f"map解析的结果是:{rdd_str1.collect()}")
rdd_str2 = rdd_str.flatMap(lambda x: x.split("."))
print(f"flatMap解析的结果是:{rdd_str2.collect()}")
输出:
[10, 20, 30, 40, 50, 60, 70, 80, 90]
map解析的结果是:[['java', 'io', 'FileNotFoundException'], ['sc', 'setLogLevel(newLevel)'], ['hadoop', 'home', 'dir']]
flatMap解析的结果是:['java', 'io', 'FileNotFoundException', 'sc', 'setLogLevel(newLevel)', 'hadoop', 'home', 'dir']
使用 PySpark 创建了一个 RDD,并对其进行了 map 和 flatMap 转换:
- 使用
sc.parallelize()方法创建了一个整数类型的 RDD,其中包含数字1到9。 - 对 RDD 进行
map转换,将每个元素乘以10。 - 使用
print函数输出 map 后的结果。 - 使用
sc.parallelize()方法创建了一个字符串类型的 RDD,其中包含三个字符串。 - 对 RDD 进行
map转换,将每个字符串按照 “.” 分隔成多个子字符串。 - 使用
print函数输出 map 后的结果。 - 对 RDD 进行
flatMap转换,将每个字符串按照 “.” 分隔成多个子字符串,并将所有子字符串扁平化为一维列表。
总结:
map函数将输入 RDD 的每个元素应用于给定的函数,并返回一个新的 RDD,其中包含函数应用后的结果。flatMap函数与map函数类似,但它的输出是一个扁平化的结果。也就是说,对于每个输入元素,函数可以返回一个或多个输出元素,并将所有输出元素进行扁平化。- 可以使用
collect()函数将 RDD 中的所有元素收集到本地计算机上,并将其作为列表返回。需要注意的是,如果 RDD 中的元素非常多,则可能会导致内存不足或性能问题。
PySpark提供了丰富的数据处理和分析功能,同时也具备了Python编程语言的灵活性和易用性,使得开发人员能够以简洁的方式编写大规模数据处理应用程序。
三、问题总结
1.代码问题
报错:

Traceback (most recent call last):
File "D:\demo\pyspark_demo\demo.py", line 3, in <module>
conf = SparkConf.setAppName("create rdd").setMaster("local[*]")
TypeError: SparkConf.setAppName() missing 1 required positional argument: 'value'
报错中直接指出具体报错行,经过检查发现SparkConf没有写括号
更正代码:
conf = SparkConf().setAppName("create rdd").setMaster("local[*]")
2.配置问题
报错:
java.io.IOException: Cannot run program "python3": CreateProcess error=3, 系统找不到指定的路径。
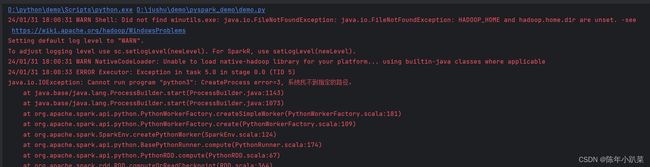
解决方式:
找到本地的python.exe,copy之后改名字python3.exe。重启解决~~~~(真是意想不到!!!!)