基于Transformer结构的扩散模型综述
个人主页: https://zhangxiaoshu.blog.csdn.net
欢迎大家:关注+点赞+评论+收藏⭐️,如有错误敬请指正!
未来很长,值得我们全力奔赴更美好的生活!
前言
近年来,计算机科学领域的生成式扩散模型迅猛发展,成为人工智能领域的热门研究方向。这一类模型,如GPT系列,以其强大的语言理解和生成能力,成功地应用于自然语言处理、文本生成、机器翻译等多个领域。扩散模型通常使用一个基于卷积的U-Net网络用于学习噪声并对噪声进行预测,近一年来,越来愈多的研究开始探索基于Transformer的噪声预测网络,本文主要介绍了近年来的一些经典工作。
文章目录
- 前言
- 1. U-Net和视觉Transformer
- 2. DiT
- 3. U-ViT
- 4. GenViT
- 5. DiffiT
- 总结
1. U-Net和视觉Transformer
视觉Transformer和卷积U-Net网络是两种不同的神经网络架构,通常用于计算机视觉任务,包括图像生成、图像分类和分割等。以下是对它们的简要回顾和比较:
- 视觉Transformer:
- 结构: 基于自注意力机制的Transformer架构,广泛应用于自然语言处理,最近也用于计算机视觉。
- 自注意力: 通过自注意力机制实现全局感知,能够捕捉输入序列或图像的长距离依赖关系。
- 序列处理: 最初设计用于序列数据,但通过图像划分成块或补充位置编码,也能应用于图像数据。
- 扩展性: 具有较强的扩展性,可以处理不同尺寸的输入。
- 卷积U-Net网络:
- 结构: 基于卷积神经网络(CNN)的U-Net结构,专注于图像处理任务,如图像分割。
- 卷积操作: 使用卷积层进行局部感知,通过卷积核在图像上滑动,捕捉图像的局部特征。
- 图像处理: 主要用于图像处理任务,如图像分割,其中U-Net的编码器和解码器结构有助于保留高分辨率信息。
- 适用性: 在处理局部特征和图像之间的空间关系时表现良好。
选择:
- 如果任务涉及到全局依赖性,尤其是对长距离上下文关系的敏感,视觉Transformer可能更适合。
- 如果任务涉及到局部特征的捕捉,如图像分割,U-Net可能更适合,特别是在计算资源有限的情况下。
在深度学习领域,扩散模型以其强大的表达能力和高质量的样本生成能力引起了广泛关注,并在各个领域中催生了许多新的应用和用例。这些模型在样本生成任务中表现出色,其核心机制涉及通过迭代去噪生成图像的去噪神经网络。在这一领域,研究者们已经取得了显著的进展,但对于去噪网络架构的深入研究尚未完全展开。目前,大多数工作都倾向于依赖卷积残差U-Net等传统结构,用于设计去噪神经网络,缺乏对其内在机理和优化空间的全面理解。
近期,随着计算机视觉领域对深度学习方法的不断深入,研究者们逐渐开始关注视觉Transformer在基于扩散的生成学习中的潜在优势。视觉Transformer是一种基于自注意力机制的创新架构,最初在自然语言处理领域取得成功,如今在图像生成任务中也呈现出良好的性能。为了进一步探索和提升生成模型的性能,一些研究方向开始尝试结合视觉Transformer和U-Net的优势,创造新的混合模型。这一趋势的目标是在图像生成和其他计算机视觉任务中取得更好的性能,通过充分发挥两者的优势,实现更有效的信息捕获和图像生成。这一前沿的研究领域不仅推动了对生成模型的不断创新,还为深度学习在图像处理和计算机视觉中的应用开辟了新的可能性。通过融合不同的神经网络结构,研究者们致力于提高生成模型的灵活性、适用性和性能,为未来的计算机视觉应用奠定了更为坚实的基础。
2. DiT
论文:Scalable Diffusion Models with Transformers(ICCV 2023)
作者探索了一类基于Transformer架构的新型扩散模型。作者训练了基于图像的潜在扩散模型,将通常使用的U-Net骨干替换为在潜在块上操作的Transformer。通过Gflops测量前向传播复杂性的角度分析了作者提出的Diffusion Transformers(DiTs)的可扩展性。作者发现,具有更高Gflops的DiTs(通过增加Transformer深度/宽度或增加输入令牌的数量)一贯具有较低的FID。除了具有良好的可扩展性属性外,最大的DiT-XL/2模型在类别条件的ImageNet 512x512和256x256基准测试中胜过了所有先前的扩散模型,在后者上取得了2.27的最先进FID。

扩散Transformer(DiT)架构图如上图所示。左图为训练条件潜在DiT模型。输入的潜在被分解成块,并由多个DiT块处理。右图为文章的DiT块的详细信息。作者尝试了标准Transformer块的变体,通过自适应层规范、交叉注意力和额外的输入令牌来引入条件。自适应层规范效果最佳。
3. U-ViT
论文:All are WorthWords: A ViT Backbone for Diffusion Models(清华大学 CVPR 2023)
代码:https://github.com/baofff/U-ViT
视觉Transformer(ViT)在各种视觉任务中显示出潜力,而基于卷积神经网络(CNN)的U-Net仍然在扩散模型中占主导地位。作者设计了一种简单而通用的基于ViT的架构(称为U-ViT),用于图像生成与扩散模型。U-ViT的特点是将所有输入,包括时间、条件和噪声图像块,都视为令牌,并在浅层和深层之间使用长跳跃连接。
作者在无条件和类条件图像生成以及文本到图像生成任务中评估了U-ViT,在这些任务中,U-ViT与相似规模的基于CNN的U-Net相比,性能相当或更好。特别是,在ImageNet 256x256上,具有U-ViT的潜在扩散模型在类别条件的图像生成中取得了创纪录的FID分数为2.29,在MS-COCO上进行文本到图像生成时为5.48,而且这是在生成模型训练期间没有使用大规模外部数据集的情况下实现的。文章的结果表明,对于基于扩散的图像建模,长跳跃连接是关键的,而基于CNN的U-Net中的下采样和上采样操作并不总是必要的。并且作者提到他们相信U-ViT可以为未来在扩散模型的骨干上进行研究并在大规模跨模态数据集上受益的生成建模提供见解。
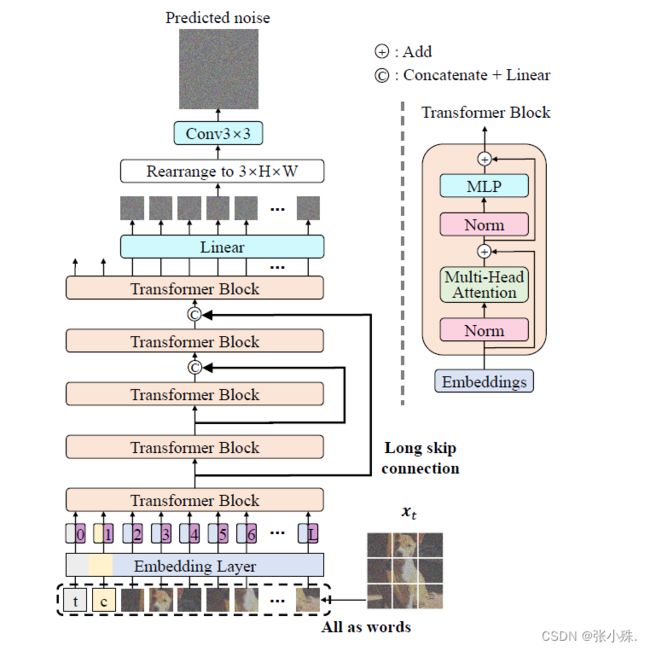
如上图所示为U-ViT用于扩散模型的架构,其特点是将所有输入,包括时间、条件和噪声图像块,都视为令牌,并在浅层和深层之间使用(#Blocks-1)/2个长跳跃连接。
4. GenViT
论文:Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
代码:https://github.com/sndnyang/Diffusion_ViT
扩散去噪概率模型(DDPM)和视觉Transformer(ViT)分别在生成任务和判别任务中取得了显著的进展,迄今为止,这些模型主要在各自的领域中得到了发展。在本文中,作者通过将ViT架构整合到DDPM中,建立了DDPM和ViT之间的直接联系,并引入了一个名为生成ViT(GenViT)的新生成模型。ViT的建模灵活性使我们能够进一步扩展GenViT以进行混合判别生成建模,并引入混合ViT(HybViT)。是首批探索单一ViT同时用于图像生成和分类的研究之一。作者进行了一系列实验,分析了提出模型的性能,并展示了它们在生成和判别任务中优于先前的最先进技术。
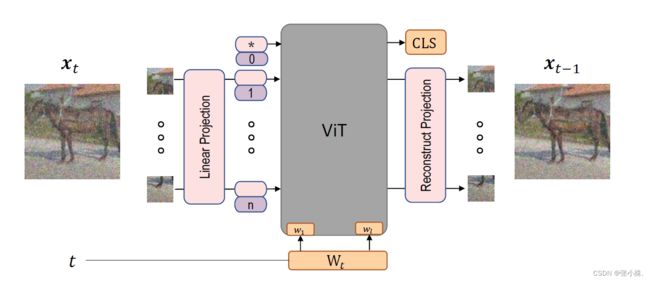
上图为GenViT和HybViT的骨干架构。对于生成建模,带有时间嵌入t的 x t x_t xt被输入模型。对于HybViT中的分类任务,从CLS(类别标志)和输入 x 0 x_0 x0计算 l o g i t s logits logits。
5. DiffiT
论文:DiffiT: Diffusion Vision Transformers for Image Generation(NVIDIA)
代码:https://github.com/NVlabs/DiffiT
扩散模型以其强大的表达能力和高质量的样本生成能力,在各个领域中启用了许多新的应用和用例。对于样本生成,这些模型依赖于通过迭代去噪生成图像的去噪神经网络。然而,去噪网络架构的作用尚未得到很好的研究,大多数工作都依赖于卷积残差U-Net。
在本文中,作者研究了视觉Transformer在基于扩散的生成学习中的有效性。具体而言,作者提出了一个新模型,称为Diffusion Vision Transformers(DiffiT),它由一个具有U形编码器和解码器的混合分层架构组成。引入了一种新颖的时间相关的自注意模块,使得注意力层能够以高效的方式在去噪过程的不同阶段自适应其行为。此外还引入了潜在DiffiT,它包括具有提出的自注意层的Transformer模型,用于高分辨率图像生成。
结果表明,DiffiT在生成高保真度图像方面非常有效,并在各种类别条件和无条件合成任务中取得了最先进的性能。在潜在空间中,DiffiT在ImageNet-256数据集上实现了1.73的新的最先进FID分数。
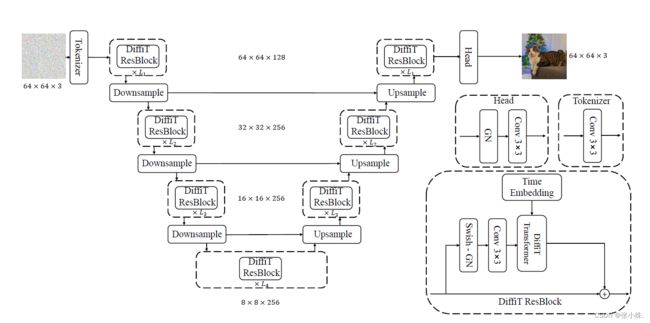
上图为DiffiT模型的总体架构图。Downsample和Upsample分别表示卷积下采样和上采样层。
总结
欢迎补充,同时文中有不对的地方欢迎指正。