Redis——RDB持久化
前言
Redis是一个键值对数据库服务器,服务器中通常包含任意个非空数据库,而每个非空数据库中又可以包含任意个键值对,为了方便起见,我们将服务器中的非空数据库以及它们的键值对统称为数据库状态。

因为Redis数据库是内存数据库,他将自己的数据库状态存储在内存里面。所以如果不想办法将存储在内存中的数据库状态保存到磁盘里面,那么一旦服务器进程退出,服务器中的数据库状态也会消失不见。
为了解决这个问题,Redis提供了RDB持久化功能,这个功能可以将Redis在内存中的数据库状态保存到磁盘中,避免数据意外丢失。
RDB持久化既可以手动执行(通过SAVE或BGSAVE命令),也可以根据服务器配置选项定期执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中。RDB持久化功能所生成的RDB文件是一个经压缩的二进制文件,通过该文件可以还原成RDB文件时的数据库状态。

由于RDB文件是保存在硬盘中的,所以即使Redis服务器进程退出,甚至运行Redis服务器停机,只要RDB文件仍然存在,Redis服务器就可以用它来还原数据库状态。
一. RDB文件的创建
1.1
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。
- SAVE命令回阻塞Redis服务进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求。
- BGSAVE命令则回派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求。
创建RDB文件的实际工作由rdb.c/rdbSave函数完成的,SAVE和BGSAVE命令会以不同的方式调用这个函数,通过以下伪代码可以明显看出这两个命令的区别:
def SAVE():
#创建RDB文件
rdbSave()
def BGSAVE():
#创建子进程
pid = fork()
if pid == 0:
#子进程
rdbSave()
#完成后向父进程发送信号
signal_parent()
elif pid > 0:
#父进程
handle_request_and_wait_signal()
else:
handle_fork_error()二. RDB文件的载入
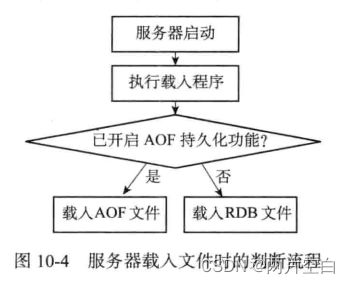
Redis并没有用于载入RDB文件的命令,RDB文件的载入工作是在服务器启动时自动执行的,只要Redis服务器在启动时检测到RDB文件存在,他就会自动加载RDB文件。
以下是Redis服务器启动时打印的日志记录,其中第二条日志就是服务器在成功加载RDB文件后打印的:

另外, 因为AOF文件更新频率通常比RDB文件的更新频率高,所以:
- 如果服务器开启了AOF持久化的功能,那么服务器会优先使用AOF文件来还原数据库状态。
- 只有在AOF持久化功能关闭的情况下,服务器才会使用RDB文件来还原数据库状态。
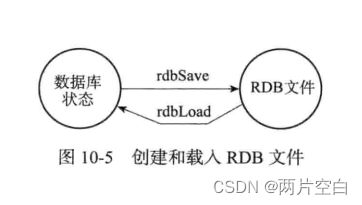
载入RDB文件的实际工作由rdb.c/rdbLoad函数完成:
三. RDB文件创建和载入时服务器的状态
3.1 SAVE命令执行时的服务器状态
当SAVE命令执行时,Redis服务器会被阻塞,所以当SAVE命令执行时,客户端发送所有命令请求都会被拒绝。
只有在服务器执行完SAVE命令,重新开始接受命令请求之后,客户端发送的命令才会被处理。
3.2 BGSAVE命令执行时的服务器状态
因为BGSAVE命令的保存工作是由子进程执行的,所以在子进程创建RDB文件的过程中,Redis服务器仍然可以继续处理客户端请求,但是在BGSAVE命令执行期间,服务器处理SAVE,BGSAVE,BGREWRITEAOF三个命令的方式会和平时有所不同。
首先,在BGSAVE命令执行期间,客户端发送的SAVE命令和BGSAVE命令会被服务器拒绝执行,是为了避免父进程和子进程同时对rdbSave函数的调用,防止产生竞争。
其次,BGREWRITEAOF和BGSAVE命令不能同时执行:
- 如果BGSAVE命令正在执行,那么客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行。
- 如果BGREWRITEAOF命令正在执行,那么客户端发送的BGSAVE命令会被服务器拒绝。
因为BGREWRITEAOF命令和BGSAVE两个命令的实际工作都是由子进程完成的,所以两个命令并不冲突。不能同时执行只是为了提高性能,并发出两个子进程,并且这两个子进程都同时执行大量的磁盘写入,效率不高。
3.3 RDB文件载入时服务器的状态
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入完成为止。
3.4 自动间隔保存
由于save命令由服务器进程执行保存工作,会阻塞服务器进程,BGSAVE命令由子进程执行保存工作,不会阻塞服务器进程,所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。
用户可以通过save选项设置多个保存条件,但是只要其中任意一个条件满足,服务器就可以执行BGSAVE命令。
举个例子:如果我们向服务器提供以下配置:
save 900 1
save 300 10
save 60 10000上面任意一个条件满足,BGSAVE命令就会被执行:
- 服务器在900秒之内,对数据库进行了至少1次修改。
- 服务器在300秒之内,对数据库进行了至少10次修改。
- 服务器在60秒之内,对数据库进行了至少10000次修改。
3.4.1 设置保存条件
当Redis服务器启动时,用户可以通过指定配置文件或者传入启动参数的方式设置save选项,如果用户没有主动设置save选项,那么服务器会为save选项设置默认条件:
save 900 1
save 300 10
save 60 10000接着,服务器程序会根据save选项所设置的保存条件,设置服务器状态redisServer的结构saveparams属性:
struct redisServer {
...
struct saveparam *saveparams; /* Save points array for RDB */
...
};saveparams属性是一个数组,数组中的每一个元素都是一个saveparam结构,每一个saveparam结构都保存了save选项设置的保存条件:
struct saveparam {
time_t seconds;
int changes;
};比如:如果save选项的值为以下条件:
save 900 1
save 300 10
save 60 10000那么服务器状态中的saveparams数组将会是如下图所示:

3.4.2 dirty计数器和lastsave属性
除了saveparams数组之外,服务器状态还维持着dirty计数器,以及lastsave属性:
- dirty计数器记录距离上一次执行save或者bgsave命令之后,服务器对数据库状态(所有数据库)进行了多少次的修改(包括写入,删除,更新操作)。
- lastsave属性是一个时间戳,记录上一次服务器成功执行save或者bgsave命令的时间。
struct redisServer
{
long long dirty; /* Changes to DB from the last save */
...
time_t lastsave; /* Unix time of last successful save */
...
};当服务器成功执行一个数据库修改命令之后,程序会对dirty计数器进行更新,命令修改了多少次数据库,dirty计数器的值就增加了多少次。
如:下面命令,会将dirty计数器加3。
SADD DATABASE REDIS MONGODB MARIADB3.4.3 检查保存条件是否满足
Redis的服务器周期性操作函数serverCron默认每隔100毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,他的其中一项工作就是检查save选项设置的保存条件是否满足,如果满足的话,就执行BGSAVE命令。
执行完BGSAVE命令后,更新执行BGSAVE时间。
伪代码:
def serverCron():
#...
#遍历所有保存条件
for saveparam in server.saveparams:
#计算距离上次执行保存操作由多少秒
save_interval = unixtime_now() - server.lastsave
#如果修改次数超过条件设置的修改次数
#和上次保存时间超过条件设置的时间
#那么执行保存操作
if save.dirty >= saveparam.changes and save_interval > saveparam.seconds:
BGSAVE()
#...四.RDB文件结构
下面介绍的是版本6的RDB文件结构:
4.1 结构

RDB文件最开头是REDIS部分,这部分的长度为5字节,保存着'REDIS'五个字符。通过这五个字符,程序可以在载入文件时,快速检查所载入的文件是否RDB文件。
注意:因为RDB文件保存的时二进制文件,而不是C字符串,为了简便起见,我们用'REDIS'五个字符代表'R','E','D','I','S'五个字符,而不是带有'\0'结尾的C字符串。本章所有内容,以及展示的RDB我呢见结构图都遵循这一规则。
db_version长度为4字节,它的值是一个字符串表示的整数,这个整数记录了RDB文件的版本号,比如"0006"就代表RDB文件的版本为第六版。
database部分包含着零个或者任意多个数据库,以及各个数据库中的键值对数据:
- 如果服务器的数据库状态为空(所有数据库都是空的),那么这个部分也为空,长度为0字节。
- 如果服务器的数据库状态不为空(有至少一个数据库非空),那么这个部分也为非空,根据数据库所保存的键值对的数量,类型和内容不同,这个部分的长度也会有所不同。
EOF常量的长度为1字节,这个常量标志着RDB文件正文内容的结束,当读入程序遇到这个值的时候,他知道所有数据库的所有键值对都已经载入完毕了。
check_sum是一个8字节长的无符号整数,保存一个校验和,这个校验和是程序通过对REDIS,db_version,database,EOF四个部分的内容进行计算得出来的。服务器在载入RDB文件时,会将载入数据所计算出来的校验和与check_sum所记录的校验和进行对比,对此来检查RDB文件是否有出错或者损坏的情况出现。
4.2 databse部分
一个RDB文件的database部分可以保存任意多个非空数据库。
例如:如果服务器的0号数据库和3号数据库非空,那么服务器将创建一个如下图所示的RDB文件,图中的database 0代表0号数据库中的所有键值对数据,而database 3则代表3号数据库中的所有键值对数据。

每一个非空数据库在RDB文件中都可以保存为SELECTED,db_nunber,key_value_pairs三个部分。

- SELECTED常量的长度为1字节,当读入程序遇到这个值的时候,它知道接下来要读入的将是一个数据库号码。
- db_name保存着一个数据库号码,根据号码的大小不同,这个部分的长度可以是1字节,2字节或者5字节。当程序读入db_namer部分之后,服务器会调用SELECT命令,根据读入的数据库号码进行数据库切换,使得之后读入的键值对可以载入到正确的数据库中。
- key_value_pair部分保存了数据库中所有键值对数据,如果键值对带有过期时间,那么过期时间会和键值对一起保存在一起。根据键值对数量,类型,内容以及是否有过期时间等条件的不同,key_value_pair部分的长度也会有所不同。
4.3 key_value_pair部分
RDB文件中的每个key_value_pair部分都保存了一个或以上数量的键值对,如果键值对带有过期时间的话,这些键值对的过期时间也会保存在内。
4.3.1 不带过期时间
不带有过期时间的键值对在RDB文件中有TYPE,KEY,VALUE三部分组成。

TYPE记录了VALUE类型,长度1字节,值可以是以下常量中的一个:

上面列出的每一个TYPE常量代表了一种对象类型或底层编码,当服务器读入RDB文件中的键值对数据时,程序会根据TYPE的值来决定如何读入和解释value数据。key和value分别保存了键值对的键对象和值对象。
- 其中键对象总是一个字符串对象,它的编码方式和REDIS_RDB_TYPE_STRING类型的value一样。根据内容长度的不同,key的长度也会有所不同。
- 根据TYPE类型的不同,以及保存内容长度的不同,保存value的结构和长度也会有所不同。
4.3.2 带过期时间
结构如下图:

TYPE,KEY,VALUE和上面介绍的意义相同。
EXPIRETIME_MS常量的长度为1字节,它告知读入程序,接下来要读入的将是一个以毫秒为单位的过期时间。
ms是一个8字节长的带符号整数,记录着一个以毫秒为单位的UNIX时间戳,这个时间戳就是键值对的过期时间。
4.4 value部分
RDB文件中的每一个value部分保存了一个值对象,每一个值对象的类型由TYPE记录,根据类型的不同,value部分的结构,长度也会有所不同。
REDIS对象编码:Redis对象系统-CSDN博客
4.4.1 字符串对象
如果TYPE值为REDIS_RDB_TYPE_STRING,那么value保存的是一个字符串对象,字符串对象的编码可以是REDIS_ENCODING_INT或REDIS_ENCODING_RAW。
如果字符串对象的编码是REDIS_ENCODING_INT,那么说明对象中保存的是长度不超过32位的整数,这种编码结构都下图:

- ENCODING值可以是REDIS_RDB_ENC_INT8, REDIS_RDB_ENC_INT16或者REDIS_RDB_ENC_INT32三个常量中的一个。它代表RDB文件使用8位,16位或者32位来保存整数值。
- 如果字符串的编码为REDIS_ENCODING_RAW,那么说明对象保存的是一个字符串对象,根据字符串长度的不同,由压缩和不压缩两种方式来保存:
- 如果字符串长度小于等于20字节,那么字符串会直接被原样保存。len保存了字符串的长度。

- 如果字符串长度大于20字节,那么字符串会被压缩后保存。
- 如果服务器关闭了RDB文件压缩功能,那么RDB程序总会以无压缩的方式来保存字符串值。具体信息可以参考redis.conf文件中关于rdbcompression选项的说明。

其中,REDIS_RDB_ENC_LZF常量标志字符串已被LZF算法压缩过,程序在碰到这个常量时,会根据compressed_len,origin_len和compressed_string对字符串进行解压缩,其中compressed_len记录被压缩后的长度,origin_len记录字符串原来长度,compressed_string记录被压缩后的字符串。
4.4.2 列表对象
如果TYPE的值为REDIS_RDB_TYPE_LIST,那么value保存的就是一个REDIS_ENCODING_LINKEDLIST编码的列表对象,RDB文件保存这种对象的结构如下图:

list_length记录了列表的长度,它记录列表保存了多少项,读入程序可以通过知道自己应该读入多少列表项。
图中item开头部分代表列表项,因为每个列表项都是一个字符串对象,所以程序会以处理字符串对象的方式来保存和读入列表项。
示例:

结构中的第一个数字3是列表长度,之后跟着的分别是第一个列表项,第二个列表项和第三个列表项。其中:
- 第一个列表项的长度为5,内容为字符串"hello"。
- 第二个列表项的长度为5,内容为字符串"world"。
- 第三个列表项的长度为1,内容为字符串"!"。
4.4.3 集合对象
如果TYPE的值为REDIS_RDB_TYPE_SET,那么value保存的就是一个REDIS_ENCODING_HT编码的集合对象,结构如下图:

其中set_size是集合的大小,它记录集合保存了多少个元素,读入程序可以通过这个大小知道自己应该读入多少个集合元素。
图中elem开头部分代表集合元素,因为每一个集合元素都是一个字符串对象,所以程序会以处理字符串对象的方式来保存和读入集合元素。
示例:
结构中第一个数字4记录了集合大小,之后跟着的是集合的四个元素:
- 第一个元素长度为5,值为"apple"。
- 第二个元素长度为6,值为"banana"。
- 第三个元素长度为3,值为"cat"。
- 第四个元素长度为3,值为"dog"。

4.4.4 哈希表对象
如果TYPE的值为REDIS_RDB_TYPE_HASH,那么value保存的就是一个REDIS_ENCODING_HT编码的集合对象,结构如下:
- hash_size记录了哈希表大小,读入程序可以通过这个大小知道自己应该读入多少键值对。
- key_value_pair开头部分代表哈希表中的键值对,键值对的键和值都是字符串对象,所以程序会以处理字符串对象的方式来保存和读入键值对。

key_value_pair结构中的每个键值对都以键紧挨着值的方式排列在一起。

合并之后的结构:

示例:
第一个数字2记录了哈希表的键值对的数量,之后跟着的是两个键值对:
- 第一个键值对的键长度为1的字符串"a",值的长度为5的字符串"apple"。
- 第二个键值对的键长度为1的字符串"b",值的长度为6的字符串"banana"。

4.4.5 有序集合对象
如果TYPE的值为REDIS_RDB_TYPE_ZSET,那么value保存的就是一个REDIS_ENCODING_SKIPLIST编码的有序集合对象。结构如下:

sorted_set_size记录有序集合的大小,读入程序需要根据这个值来决定应该读入多少有序集合元素。
以element开头部分代表有序集合元素,每一个元素又分为成员和分值两个部分,成员是一个字符串元素,分值则是一个double类型的浮点数,程序在保存RDB文件时会先将分值转换为字符串对象,然后再用保存字符串对象的方法将分值保存起来。
有序集合中的每一个元素以成员紧挨着分值的方式排列:

两结构合并后:

示例:
第一个数字2记录了有序集合元素数量:
- 第一个元素的成员是长度为2的字符串"pi",分值转化为字符串后变成长度为4的字符串"3.14"。
- 第二个元素成员是长度为1的字符串"e",分值转化为字符串后变成长度为3的字符串"2.7"。

4.4.6 INTSET编码的集合
如果TYPE的值为REDIS_RDB_TYPE_SET_INTSET,那么value保存的就是一整个集合对象,RDB文件保存这种对象的方法是,先将整数集合转换为字符串对象,然后将字符串对象保存到RDB文件中。
如果程序读入RDB文件的过程中,碰到由整数集合对象转换成的字符串对象,那么程序会根据TYPE的值,先读入字符串对象,再将字符串对象转换为原来的整数集合对象。
4.4.7 ZIPLIST编码的列表,哈希表或者有序集合
如果TYPE的值为REDIS_RDB_TYPE_LIST_ZIPLIST,REDIS_RDB_TYPE_HASH_ZIPLIST
或者REDIS_RDB_TYPE_ZSET_ZIPLIST,那么value保存就是一个压缩列表对象,RDB文件保存的方式是:
- 将压缩列表转化成一个字符串对象。
- 将转换所得的字符串对象保存到RDB文件
如果程序在读入RDB文件过程中,碰到压缩列表对象转化成的字符串对象,那么程序会根据TYPE的指示,执行下面操作:
- 读入字符串对象,将它转化成原来的压缩列表对象。
- 根据TYPE的值,设置压缩列表对象的类型:如果TYPE的值为REDIS_RDB_TYPE_LIST_ZIPLIST,那么压缩列表对象的类型为列表。如果TYPE的值为REDIS_RDB_TYPE_HASH_ZIPLIST,那么压缩列表对象的类型为哈希表。如果TYPE的值为REDIS_RDB_TYPE_ZSET_ZIPLIST,那么压缩列表对象的类型为有序集合。