C++——流和输入输出
写在前面
应该知道的一些知识
掩码(mask)
定点计数法
科学计数法 //应该都知道
基本认识
C++把程序的输入和输出看作一个字节流
流的概念:流是一个抽象、动态的概念,是一连串连续动态的数据集合。 对于输入流而言,数据源就像水箱,流 (stream)就像水管中流动着的水流,程序就是我们最终的用户。 我们通过流 (A Stream)将数据源 (Source)中的数据 (information)输送到程序 (Program)中,或者从程序中接受。
其实流就是一堆数据,这些数以依次发往要去的地方,就像水流一样。
输入时,程序从输入流中抽取字节,输出时,程序将字节添加到输出流里。
在进行输入输出时,数据不会立刻流动到目标(例如从键盘输入),而是被放在一个名为缓冲区的内存块中。
输入流
例如下面的例子。
#include
using namespace std;
int main()
{
cout << "please input words";
char ch;
int total = 0;
while(cin >>ch&&ch!='~')
{
if(ch>='0'&&ch<='9')
total++;
cout << "now total is " << total << endl;
}
cout << total;
return 0;
} 运行结果

在回车的那一刻,从缓冲区中发送给程序。
输出时,程序首先填满缓冲区,再把数据块以块的形式传递,并清空缓冲区,以便供下一波输出使用(缓冲区刷新)
输出流
输出流时逐字符输出的,即只会发送字符,例如一个-3.14,不是发送-3.14这个数据块,而是经过ostream类处理,逐字符输出字符 - 3 . 1 4。对于宽字符类型,像汉字,ostream类中也有相应的字符类型(wchar_t)。
从键盘输入每次只能键入一个字符,为什么要有缓冲区呢
这样做为了提高容错,在没有按下回车前可对要发送到输入流中的数据修改。在键入回车的一刻,缓冲区将数据流发送到目标(屏幕或其他。
抽象的解释
源 -> 流 -> 目标
流的作用
无论是进行输入还是输出,都需要将流链接两个目标对于,程序而言,可通过流与文件,显示器,键盘相连。
因此,流充当的类似桥梁的作用。
缓冲区的作用
应该都知道硬盘和内存的关系
流和文件也是对应的这种关系
通常,通过使用缓冲区可以更高效的处理输入和输出。他是一个数据的临时存储工具。磁盘通常以块传输数据(例如512字节),而程序只能一次处理一个字符,二者直连很不合理,所以就放在缓冲区中。以便以合理的方式处理数据。
一些类
管理流和缓冲区的工作C++已经为我们实现好了
streambuf类 为缓冲区提供内存, 并提供了用于填充缓冲区,访问缓冲区中的内容、刷新缓冲区和管理缓冲区内存的 类方法
ios_base类 用于表示流的一般特征,是否可读取,是二进制流还是文本流
ios类 基于ios_base 其中包括了一个指向streambuf对象的指针成员
ostream类 从ios类派生而来,提供了输出方法(类方法)
istream类 从ios类派生而来,提供了输入方法(类方法)
iostream类 基于istream ostream类,因此继承了输入和输出方法
从上面得知,这么平常的输入输出竟然包含了这么多发杂的逻辑!
而cout和cin本质上是两个重载了<<(左移运算符)和>>(右移运算符)的两个iostream类的实例化对象!(在名称空间std中)
cout
<<重载过后用于输出,不再叫左移运算符,而是叫插入运算符。
最简单的输出
int a = 10;
cout << "a is" << a << endl;因为<<返回一个ostream对象的引用,可进行递归输出。
它能够识别一些基本数据类型
unsigned char signed char char short unsigned short int unsigned int long unsigned long long long //C++ 11 unsigned long long //C++ 11 float double long double
假如我们要显示一个整形的地址
int main()
{
int a = 10;
int *pa = &a;
cout << pa;
return 0;
}非常简单
那一个字符串地址呢
char str[] ="hello world";
cout << str;运行结果

为什么不是地址呢
是因为C++为下列指针也重载了<<
const signed char * const unsigned char * const char * void *
传入字符串的指针具体化的模板(重载的<<)就会输出字符串,要想输出地址强制转换即可
cout << (void*)str;运行结果

其他的ostream类方法
put(char_type __c);
write(const char_type *__s, streamsize __n);前者用于显示字符,后者用于显示字符串,二者返回 ostream &,因此均可链式调用
cout.put('A').put('b');
cout << endl;
cout.write("hello",5).write("world",10);运行结果

合适的情况下也可将int用于put(),自动转换为ASCII码对应的字符
缓冲区的刷新
如果说在等待缓冲区满再发送消息,那为什么程序还会即时发送消息呢?
这与一些机制有关:在屏幕输出时,程序不会等到缓冲区满再发送消息,例如在换行符发送到缓冲区后,程序就会清空并且发送消息,或者在输入即将发生时。即不是先输出在输入,而是将要输入的时候输出并且输入。
控制符flush,也是控制函数,可直接传入cout。
cout << flush;
//or
flush(cout);使用cout进行格式调整
在C中可用%说明符来控制打印的格式。例如,输出小数点后的两位。
double val = 3.14159;
printf("%.2f",val);在C++中也有这样的格式控制
首先,在默认情况下
对于char,如果是一个可打印字符,则被用作字符打印在宽度为1的字段中
对于整形,显示十进制,字段宽度刚好容纳数字
对于字符,串显示字段宽度正好为字符串长度
对于浮点,显示6位,并且小数点后的0不显示,使用正常显示还是科学计数法取决于具体的值,指数大于等于6或者小于等于5即显示科学计数法(不同编译器可能不同),显示字段宽度恰好能容纳符号和数字。
特别的:老式的浮点显示方法为,显示小数点后6位,0不显示
可以用cout的类方法,或者函数更改格式或者
再说一下继承关系
ostream继承ios ios继承ios_base
因此,ios_base的方法在ostream的对象中也能使用
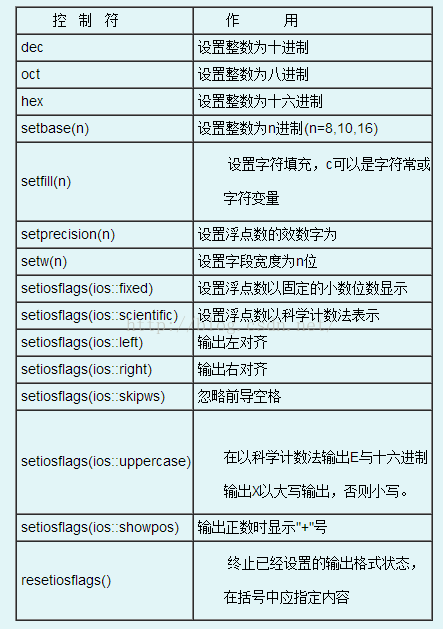
1.显示 十进制 十六进制 或者 八进制
使用控制符
dec(cout); //十
hex(cout); //十六
oct(cout); //八使用重载了的<<等价调用上面的形式
cout << dec
<< hex
<< oct;
示例
int a = 11;
cout << dec << a << endl;
cout << hex << a << endl;
cout << oct << a << endl;运行结果

注意:这样上述的两种方式都是永久有效(如果不再进行格式调整),而不是临时的(只用于下一项的输出,下一项和下一次是不同的概念)。
2.设置字段宽度
可用于对齐(默认右对齐)
注意:字段宽度的设置,暂时有效,只适用于下一项,不是下一条输出语句,也不是永久
//返回当前设置的宽度,这里的返回指的return value
cout.width();
//设置输出字段宽度并恢复之前的设置,并且返回一个之前设置的宽度值
cout.width(int len);
//比如
#include
using namespace std;
int main()
{
char ch = 'a';
cout.width(5);
//下面的语句输出10个 字宽,因为被重设置了,但将会输出5
cout << cout.width(10) << endl;
cout << ch << endl;
//正常输出
cout << ch << endl;
//set 10
//len is 10
cout.width(10);
int len = cout.width();
//下面的输出字宽,并且返回默认值0 即return 0,并且输出一项后字宽重新 被设置为0
cout << "len is " << len << endl;\
//***len*is* 10 个字宽
//<< len 正常输出
cout << ch;
return 0;
}
运行结果

3.填充字符
cout.fill(char);注意:这个设置永久有效
cout.fill('*');
cout.width(10);
int a =10;
cout << a << endl << a;运行结果

4.设置浮点数的显示精度
cout.precision(int);示例
double val = 3.14159;
cout.precision(4);
cout << val;
cout << endl << val;注意:新的精度设置是永久有效(如果不人为改变),在进行截断时会进行四舍五入
运行结果

5.打印末尾的0和小数点
显示末尾小数点,即使位数够了,也显示 .
所以,可能会有这样的显示 : 20 .
这个类方法是ios_base中提供的,并且接受一个参数
ios_base::showpoint 是ios_base中定义的一个静态常量,可用于修改设置
同时ios_base还提供了多个类似常量,因此使用常量时用作用域解析符号 : :
cout.setf(ios_base::showpoint); double a = 2.00;
cout << a << endl;
cout.setf(ios_base::showpoint);
cout << a;运行结果

可以看一看showpoint的具体值
cout << "ios_base::showpoint value is " << ios_base::showpoint;运行结果

但不可直接传入1024作为参数
6.setf函数
应该知道的一些东西
ios_base类有一个保护的数据成员,以位为单位,分别控制着格式的各个方面(把他称作标记),参数是一个fmtflags值,指出要设置哪一位。返回值是类型为fmtflags的数字,指出所有标记以前的设置。如果打算以后恢复格式,则可以保存这个值。
函数原型其一
fmtflags setf(fmtflags);其中,fmtflags是bitmask(比特位掩码)的一个别名,通过这个命名就可以隐约的感觉出来实现原理——基于掩码
ps:掩码是位运算中的重要知识点
如何传入参数?
如果要设置11位为1,则传入一个bit位11位为1的数字。
这样的传参太令人头疼,但C++已经帮我们实现了
上面的1024转换为2进制数字是什么样子的呢
10000000000 //二进制表示
当作掩码改变第一位
一些其他的格式常量
注意:都是永久设置
ios_base::boolalpha; //输出bool值,即true和false
ios_base::showbase; //对于输出使用C++基数前缀 (0, 0x)
ios_base::showpoint; //显示小数点和小数点后面的位数
ios_base::uppercase; //对于16进制输出,使用大写字母,用E法表示
ios_base::showpos; //在正数前面加上+想要恢复设置可用调用函数unsetf()函数,恢复其中的某一个设置
演示
#include
using namespace std;
int main()
{
bool p = false;
const int a = 114514;
cout.setf(ios_base::boolalpha);
cout.setf(ios_base::showbase);
cout << "p(bool) is " << p << endl;
cout << hex << a << endl;
double b = 30.45;
cout.precision(2);
cout.setf(ios_base::showpoint);
cout << b << endl;
cout.setf(ios_base::uppercase);
cout << hex << a << endl;
cout.setf(ios_base::showpos);
cout << dec << a << endl;
return 0;
}
运行结果

第二个setf()接受两个参数,并返回以前设置的值。
//函数原型
fmtflags setf(fmtflags,mask/*fmtflags*/);第一个参数的作用与上面的版本相同,第二个参数是一个掩码,表示要清除哪些位。
可以这样使用
#include
using namespace std;
int main()
{
ios_base::fmtflags temp;
bool p = false;
const int a = 114514;
cout.setf(ios_base::boolalpha);
cout.setf(ios_base::showbase);
cout << "p(bool) is " << p << endl;
cout << hex << a << endl;
double b = 30.45;
cout.precision(2);
//关闭上面开启的码位
temp = cout.setf(ios_base::showpoint);
cout << b << endl;
cout.setf(ios_base::uppercase,temp);
cout << hex << a << endl;
cout.setf(ios_base::showpos);
cout << dec << a << endl;
return 0;
}
运行结果

或者也可以恢复到之前的设置
cout.setf(temp,ios_base::adjustfidld);调用函数unsetf()恢复设置
#include
using namespace std;
int main()
{
bool p = false;
cout.setf(ios_base::boolalpha);
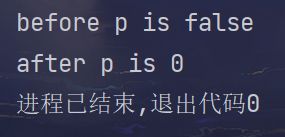
cout << "before p is " << p << endl;
cout.unsetf(ios_base::boolalpha);
cout << "after p is " << p;
}
运行结果
C++提供了一些参数
| 第二个参数 | 第一个参数 | 含 义 |
|---|---|---|
| ios_base::dec | 十进制 | |
| ios_base::basefield | ios_base::oct | 八进制 |
| ios_base::hex | 十六进制 | |
| ios_base::fixed | 定点计数 | |
| ios_base::floatfield | ios_base::scientific | 科学计数 |
| ios_base::left | 左对齐 | |
| ios_base::adjustfield | ios_base::right | 右对齐 |
| ios_base::internal | 符号/基数前缀左对齐 值又对齐 |
8.头文件iomanip
提供了一些控制符
例如
setprecision(int);
setfill(char);
setw(int);
见名知义了,不解释。
可以和cout连用
演示
#include
#include
using namespace std;
int main()
{
double a =20.4055;
cout << setprecision(4) << setfill('#') << setw(10);
cout << a;
} 运行结果

注意: setprecision(int)函数在位数够的情况下不会显示小数点,在小数点后全是0的情况即使规定也不会去做
double a =20.0045;
cout << setprecision(4) << a;运行结果

想要显示全用fixed
int main()
{
double a =20.00000;
cout << setprecision(4) << a << endl;
cout << fixed << a;
}运行结果

9.小数点后几位的表示
浮点是数的含义取决于输出模式。在默认的情况下,它指的是显示的总位数。在定点模式和科学计数模式下,精度指的是小数点后面的位数
原理:使用定点计数法再限制浮点数显示精度即可
法一
double a =20.4055;
cout.precision(4);
cout << fixed << a;法二
cout << fixed << setprecision(4) << a;还有很多种方法,可以遵循上述原理排列组合。
cin
cin将对象标准输入表示位字节流。通常情况下,通过键盘来生成这种字符流。cin 根据对象接收值的变量的类型,使用其类方法将字符序列转换为所需的类型。
简单的来说,从键盘输入的全看作字符流,也可以理解为字符串,聪明的cin 用他的类方法来判断要把这些数据流转换为什么类型。
int a;
cin >> a;例如,我们从键盘输入114514,我们以为输入了一个整形,实际上只是把键盘的输入信息添加到输入流中而已,这种流的本质是字符流。
C++重载了>>(更名为抽取运算符),使之能够识别下面的基本类型
unsigned char &
signed char &
char &
short &
unsigned short &
int &
unsigned int &
long &
unsigned long &
long long & //C++ 11
unsigned long long & //C++ 11
float &
double &
long double &
比如重载了int的原型
istream & operator >>(int &);这样处理的不是数据的副本,而是本身,并可以修改其值,正对应可以用cin修改一个变量。
返回istream & 能使cin 链式调用
int a,b;
cin >> a >> b;可以将hex,oct,dec控制符与cin一起使用,来指定以几进制读取数据
using namespace std;
int main()
{
int a;
cin >> hex >> a;
cout << a;
}运行结果

cin与指针
istream类还为下列字符指针类型重载了>>运算符。
signed char *
char *
unsigned char *
使得cin能用字符指针读取字符串
演示
int main()
{
char str[10];
cin >> str;
cout << str;
}运行结果

cin如何检查输入
cin查看输入流的方式是:逃过空白(空格,回车,制表符等),直到遇到非空白字符,再从输入流中抽取。
>>运算符将读取一个指定类型的数据。也就是说,他读取从非空白字符开始,到与目标类型不匹配的第一个字符之间的全部内容。
如果输入类型不匹配,会返回0,于是可以有这种语法
while(cin >> a);读取到不符合a数据类型的数据将跳出循环。
流状态,对输入流的进一步探索
cin或者cout对象包含一个描述流状态的数据成员(就是一个变量)(从ios_base继承而来),流状态由3个ios_base元素组成:其中每个元素都是一位
eofbit
cin读取到文件结尾的时候,将设置eofbit
badbit
在一些无法诊断的失败破坏流时,设置badbit
failbit
未能读取到预期字符时,或者I/O失败,设置failbit
上述3个位全部为0的时候,表示输入顺利。
可以看一看他们对应的掩码
cout << ios_base::badbit << ios_base::eofbit << ios_base::failbit;运行结果

分别对应的二进制
ios_base::badbit mask: 001
ios_base::eofbit mask: 010
ios_base::failbit mask: 100
可以检查流状态,并利用这些信息进行一些程序处理
| 成员 | 描述 |
|---|---|
| eofbit | 如果到达文件结尾,设置为1 |
| badbit | 如果流被破坏,设置为1.例如文件损坏 |
| failbit | 如果输入未能读取预期的字符或者输出操着没有写入预期的字符,设置为1 |
| goodbit | 另一种表示流的方法 |
| good() | 如果流可以使用( 000 ),则返回true |
| eof() | 如果eofbit被设置,返回true |
| bad() | 如果badbit被设置,返回true |
| fail() | 如果failbit被设置,返回true |
| rdstate() | 返回流状态 |
| exceptions() | 返回一个位掩码,指出哪些标记导致异常 |
| exceptions(iostate ex) | 设置哪些状态将导致clear()引发异常;例如,如果ex是eofbit,并且eofbit已经被设置 则将会引发异常 |
| clear(iostate s) | 流状态设置为s,default = goodbit,并将其他位清除 |
| setstate(iostate s) | 调用( clear(rdstate|s) )。单独设置s对应的位,其余位不变 |
1.设置状态
下面的代码将会使流状态重新设置
cin.clear(); //default argument is goodbit或者用上面介绍的方法设置某一个位
为什么需要重新设置流状态呢?
最常见的理由是,输入不匹配或者达到文件结尾时,重新打开输入流,因为这时候一些位已经被设置,会影响流的正常读取。当然,具体的情况具体分析。
演示
int main()
{
int a;
int n = 5;
int sum = 0;
while(n--)
{
cin >> a;
if(!cin.good())
{
cout << "输入流错误\n";
//break;
}else
sum += a;
cout << "sum is " << sum << endl;
}
cin >> a;
}运行结果

可以看见,因为输入流错误,不能再进行输入,只能等待循环结束,并且,循环外的输入语句也没有执行。可用clear()重新设置输入流,但还是需要一些处理,下面会说到。
I/O与异常
假设某个输入函数设置了eofbit,这是否会引发程序异常呢?
在默认情况下,这是不行的,因为exceptions(iostate ex)其中的ex默认位goodbit。
如果更改了设置,使之引发了异常,则将引发ios_base::failure,从srd::expction类派生而来,因此有一个what()方法。
int main()
{
int sum = 0;
int a;
cin.exceptions(ios_base::failbit);
try{
while(cin >> a)
{
sum += a;
}
} catch (ios_base::failure & bf) {
cout << bf.what() << endl;
}
cout << "sum is " << sum;
}运行结果

流状态的影响
对于读入数据类型错误的情况,输入流被设置了failbit,理应用clear()重置。
using namespace std;
int main()
{
int a;
int n = 5;
int sum = 0;
while(n--)
{
cin >> a;
if(!cin.good())
{
cout << "输入流错误,已经重新设置\n";
cin.clear();
/* while(!isspace(cin.get()))
{
continue;
}*/
}else
sum += a;
cout << "sum is " << sum << endl;
}
cin >> a;
}运行结果

这是为什么呢?
原因是e被一直留在了输入流中
执行第一次的显示错误消息后重新进行cin>>a,此时读取到的还是e,因为类型不同,e一直没被读取,就一直进行上述循环。
将代码中的注释打开,读取到空白字符,即可重新输入。
运行结果

其他的istream类方法
1.单字符输入
get(char &) //返回一个istream & ,因此可以递归使用
get(void) //读取字符并且返回其对应的整形,不能递归使用
不跳过空白的字符读入
顺便一说,下面的代码将永远不能跳出循环,因为cin忽略输入流中的空白字符
char ch;
cin >> ch;
while(ch != '\n')
{
//do something
}但下面的代码可以,cin.get(ch)不跳过空白字符
char ch;
while(cin.get(ch)&&ch!='\n')
{
//do something
}可用这样的形式读取
cin.get(ch).get();将会丢弃第二个输入字符
演示
using namespace std;
int main()
{
string str;
char ch;
int i=0;
while(cin.get(ch).get()&&ch!='\n')
{
str += ch;
}
cout << str;
}运行结果

cin.get(void)达到文件结尾反回EOF,因此可以这样使用
while(ch = cin.get() != EOF)
{
//do something
}2.读入单个字符的选择
如果要读入菜单选项等,使用跳过空白符号的cin>> 更加合适
如果希望检查输入流中的每一个字符,应该使用get()函数的两个版本
其中get(ch)的接口更佳,get(void)的优点是方便C程序到C++程序的转换。
3.字符串读入
四个函数
istream & get(char *, int, char);
istream & get(char *, int);
istream & getline(char *, int, char);
istream & getline(char *, int);
第一个参数是用于存放字符串的地址
第二个参数是表示读取的长度+1(存放 '\0' )
第三个参数用于表示分界符
上述函数均在读取最大数目的字符或遇到换行符后为止
get()和getline()的主要区别是,前者将换行符留在输入流中,而后者从输入流中读取换行并且舍弃
ignoer()成员函数。
该函数接受两个参数:一个是数字,指定要读取的最大字符数,另一个参数是字符,用作分界符号。
函数功能,丢且接下来输入的字符长度为第一个参数,直到遇到分界符或者读满。
演示
using namespace std;
int main()
{
string str;
char str1[12];
char ch;
//cin.get(str,12) //error str isn't a char
cout << "use cin.get input str1" << endl;
cin.get(str1,12);
cout << "now str1 is " << str1 << endl;
ch = cin.get();
if(ch == '\n')
cout << "next char is \\n" << endl;
cout << "use function ignore(10,'\\n')" << endl;
cin.ignore(10,'\n');
cout << "use cin.getline input str1" << endl;
cin.getline(str1,12);
cout << "now str1 is " << str1 << endl;
cin.get(ch);
if(ch == '\n')
cout << "next char is\\n";
else
cout << "next char not is \\n";
return 0;
}一些运行结果

use cin.get input str1
hello world
now str1 is hello world
next char is \n
use function ignore(10,'\n')
1234567890
use cin.getline input str1
now str1 is /*\n*/next char is \n
上面的空行是str1本身是回车输出回车,我们又输入了一个回车的结果
字符串输入错误
getline()和get()与其他输入函数一样,遇到文件结尾时将设置eofbit,流被破坏设置badbit。
无输入或者输入超限的情况下将设置failbit
其中,如果不能从流中抽取字符则把空字符放在输入字符串中,并使用setstate设置failbit。
不能从流中抽取字符的情况下有两种
第一种是到达了文件尾
对于get(char *, int)来说(不是getline()),另一种可能是读入了空行
对上面的补充
getline()读入了空行也不会设置failbit,而是读入换行符并将其舍弃
演示
char str1[12];
cin.getline(str1,5);
cout << str1 << endl;
cin >> str1;运行结果

可以看见,不能再进行读取了
char ch;
char str1[12];
cin.get(str1,10);
cout << "str1 is " << str1 << endl;
cin.get(ch);
cout << "ch is " << ch << endl;运行结果

可以看见str1没有读入换行,ch也是乱码
如果想让getline()读入空行结束,可以这样书写
char str1[12];
while(cin.getline(str1,12)&&str1[0]!='\0')
{
cout << str1 << endl;
}运行结果

注意输入时不要超过getline中的参数限制
其他的istrream类方法
1.read()
读取指定数目的字节,不会再末尾加上空字符'\0',不是设计专门用来键盘读入的,常与ostream wrtie组合使用来读写文件,反回istream &,可链式调用
2.peek()
反回输入流中的下一个字符,但不抽取
演示
char ch;
char str[10];
int i= 0;
while((ch = cin.peek()) != '.' && ch!='\n')
str[i++] = ch = cin.get();
cout << "str is " << str << endl;
cin.get(ch);
cout << "next char is " << ch;运行结果

3.gcount()
返回最后一个非格式化抽取方法(不是cin>>)读取的字符数。
演示
char ch;
char str[10];
cin >> ch;
while(ch!='\n')
{
cin.get(ch);
}
cin.getline(str,10);
cout << cin.gcount();运行结果

为什么是7个呢
因为换行符也是一个字符
4.putback()
将一个字符头差插到输入流中 ,反回istream &
演示
char str[10];
cin.putback('1');
cin >> str;
cout << str;运行结果
