05、全文检索 -- Solr -- Solr 全文检索之图形界面的文档管理(文档的添加、删除,如何通过关键字等参数查询文档)
目录
- Solr 全文检索之文档管理
-
- 添加文档
-
- 使用 JSON 添加文档:
- 使用 XML 添加文档:
- 删除文档
-
- 使用 JSON 删除文档:
- 使用 XML 删除文档:
- 查询文档
- 查询文档的详细参数
-
- fq(Filter Query):过滤
- sort:排序
- start、rows:分页
- fl(Field List):指定返回哪些字段的数据
- df(Default Field): 指定通过哪个字段查询关键字
- wt(write type):响应类型
- debugQuery: 调试过程
- hl:高亮效果
- indent on :是否缩进
Solr 全文检索之文档管理
看下一开始还没操作过的数据

添加文档
(1)选中指定Core,然后选择“Documents”标签页。
(2)在编辑页面中选择数据格式:XML或JSON。
(3)输入XML或JSON数据:
使用 JSON 添加文档:
{
"id": 1,
"title": "Spring Boot"
"description": "学习 Spring Boot 真有趣"
}
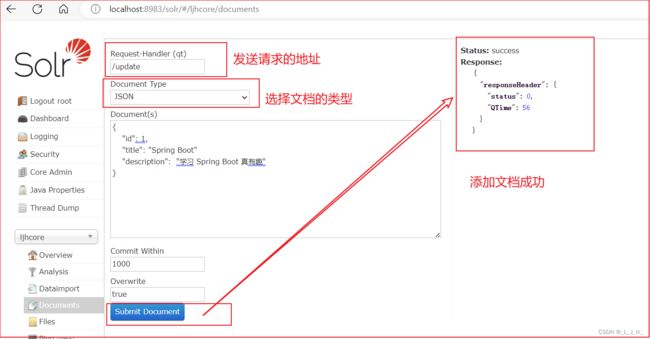
然后再看这里,文档数量变成1了。
使用 XML 添加文档:
2
学习 Solr 全文检索 真有趣

删除文档
(1)选中指定Core,然后选择“Documents”标签页。
(2)在编辑页面中选择数据格式:(Solr Command(raw XML或JSON))
(3)输入XML或JSON数据:
使用 JSON 删除文档:
{"delete":{"id":1}}
我这里选择文档类型为 JSON ,而且写法也是 JSON 格式,但是却删除失败。
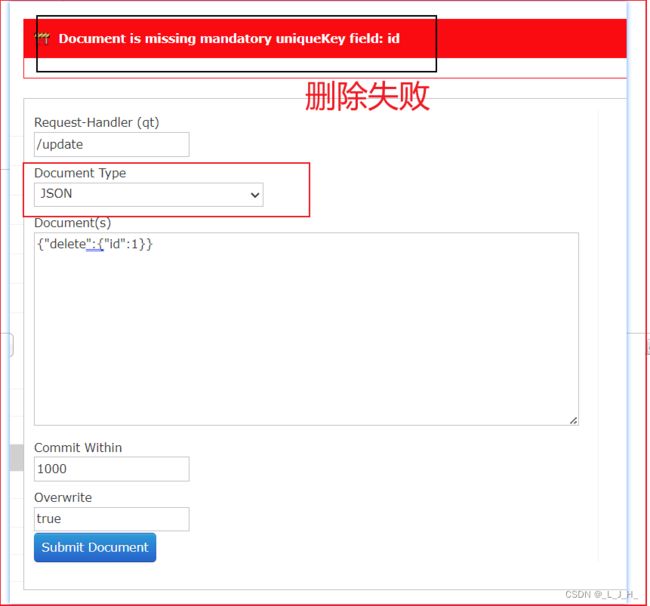
写的文档内容不变,文档类型选择:Solr Command(raw XML或JSON) ,就可以删除成功了。
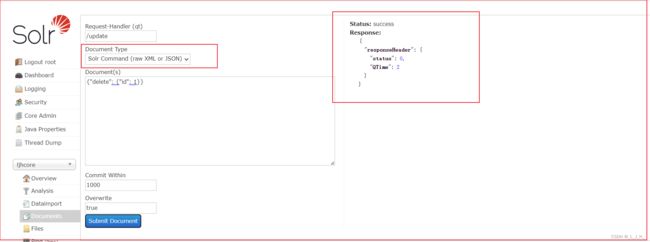
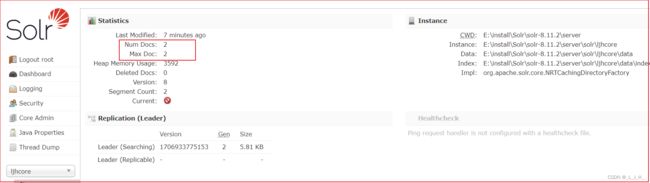
从这里看,可以看出原本两个文档,现在只剩下一个了

使用 XML 删除文档:
2

可以看到,文档数量为 0 。两种删除文档的方式都成功了

【备注:】添加文档用add命令、删除文档用delete命令
查询文档
为了演示,现在先把刚刚删除的文档再添加进来:


选中指定 Core,然后选择 “Query” 标签页。
“q” 文本框用于输入查询参数。
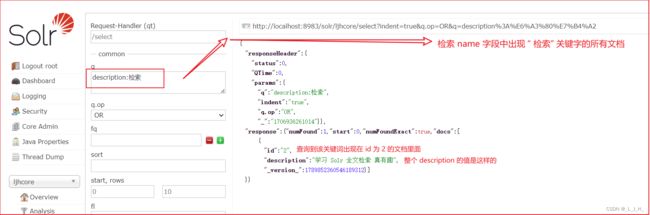
例如 输入 “name:检索”,这意味着检索 name字段中出现 “ 检索” 关键字的所有文档;
例如 输入 “学习”,这意味着检索默认字段(由df文本框指定)中出现“学习”关键字的所有文档;
例如 输入 “*:*”,这意味着检索任意字段中出现任意关键字的文档——也就是检索所有文档。
输入 “description:检索”
输入 “学习”

输入 “*:*”


Solr的查询语法:https://lucene.apache.org/solr/guide/8_7/query-syntax-and-parsing.html 页面
查询文档的详细参数

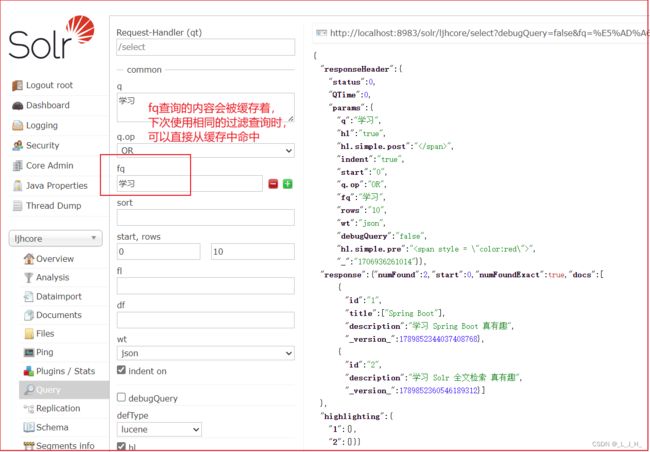
fq(Filter Query):过滤
fq(Filter Query):对应于fq参数,过滤也是一个查询,用于过滤查询结果。
在负责查询时,过滤可以很好的提高查询效率,fq查询的内容会被缓存着,下次使用相同的过滤查询时,可以直接从缓存中命中。
sort:排序
sort:对应于sort参数,用于指定根据哪个字段的得分进行排序。
如“price asc”或“inStock desc, price asc”等。

start、rows:分页
start、rows:用于控制分页。其中start指定从第几个文档开始,rows指定最多返回几个文档。
现在演示的文档有两个,分页查询如图:


fl(Field List):指定返回哪些字段的数据
fl(Field List):对应于fl参数,用于指定搜索结果中需要返回的Field,这些Field需要被索引才能正常返回。
多个Field之间可通过空格或逗号分隔。Field列表还支持通配符:*,这意味着返回文档的所有Field。
默认情况,fl默认值为:*,也就是返回所有Field。
设置查询后只返回哪些字段的数据

df(Default Field): 指定通过哪个字段查询关键字
df(Default Field):对应于df参数,指定默认Field,如果在q参数中没有指定要检索的字段,
则默认检索该参数所指定的字段。

wt(write type):响应类型
wt(write type):对应于wt参数,用于选择响应类型。默认是 json。
也就是默认查询结果将以JSON格式展现,常用的 wt 还可以是 xml。

debugQuery: 调试过程
debugQuery:勾选该复选框之后,相当于将debugQuery参数设为true,
这样返回的结果中会包含调试信息、包含“explain”信息(explain 中解释了每个文档的得分过程)。
相当于显示调试的过程

hl:高亮效果
对关键词查询的结果添加高亮效果

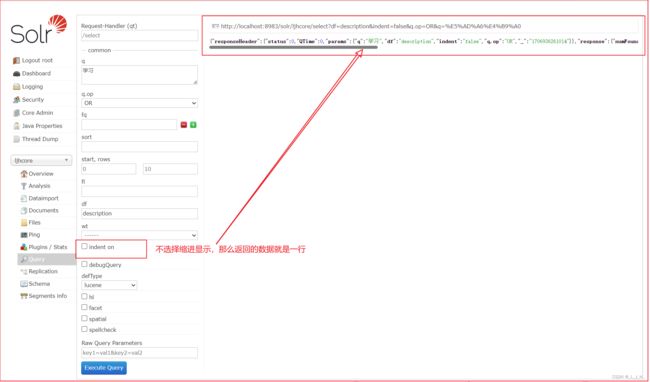
indent on :是否缩进
勾上选择缩进显示

不选择缩进显示