AI Earth挑战赛docker踩坑记录 WIN10+PyTorch
文章目录
- 0、docker环境说明
- 1、数据准备
- 2、py文件
- 3、requirements文本文件
- 4、shell文件
- 5、dockerfile文件
- 6、Powershell
- 7、提交结果
0、docker环境说明
我的系统是WIN10系统,装了一个docker desktop,让它保持启动状态就行了。阿里云的仓库也建好了,仓库名:enso_ai_2
为加快docker build,把docker配置文件改一下,参考链接
1、数据准备

赛题数据从这里下载。因为是调试阶段,所以先不训练模型,只拿test样例_20210207。解压后是这样的:
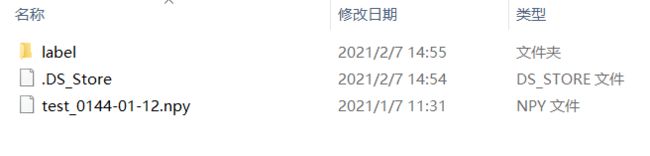
这边要把label文件夹删掉(删的原因在后面会提)、把.DS_Store也删掉。新建一个文件夹tcdata,在其中再建立一个子文件夹enso_round1_test_20210201,将test_0144-01-12.npy放入子文件夹enso_round1_test_20210201中去。像下面这样:

2、py文件
这个代码主要部分参考了微信公众号“异度入侵”的toy model和LSGOMYP的GitHub开源,相当于把前者的PyTorch部分和后者的文件处理部分整合在了一起。因为处理的是时空数据,所以模型差不多就是一个CNN+一个LSTM,反正是调试的,不作过多讲解了。
import torch
import numpy as np
import torch.nn as nn
import zipfile
import os
class simpleSpatailTimeNN(nn.Module):
def __init__(self, n_cnn_layer: int = 1, kernals: list = [3], n_lstm_units: int = 64):
super(simpleSpatailTimeNN, self).__init__()
self.conv1 = nn.ModuleList([nn.Conv2d(in_channels=12, out_channels=12, kernel_size=i) for i in kernals])
self.conv2 = nn.ModuleList([nn.Conv2d(in_channels=12, out_channels=12, kernel_size=i) for i in kernals])
self.conv3 = nn.ModuleList([nn.Conv2d(in_channels=12, out_channels=12, kernel_size=i) for i in kernals])
self.conv4 = nn.ModuleList([nn.Conv2d(in_channels=12, out_channels=12, kernel_size=i) for i in kernals])
self.max_pool = nn.AdaptiveMaxPool2d((22, 1))
self.avg_pool = nn.AdaptiveAvgPool2d((1, 128))
self.batch_norm = nn.BatchNorm1d(12, affine=False)
self.lstm = nn.LSTM(88, n_lstm_units, 2, bidirectional=True)
self.linear = nn.Linear(128, 24)
def forward(self, sst, t300, ua, va):
for conv1 in self.conv1:
sst = conv1(sst)
for conv2 in self.conv2:
t300 = conv2(t300)
for conv3 in self.conv3:
ua = conv3(ua)
for conv4 in self.conv4:
va = conv4(va)
sst = self.max_pool(sst).squeeze(dim=-1)
t300 = self.max_pool(t300).squeeze(dim=-1)
ua = self.max_pool(ua).squeeze(dim=-1)
va = self.max_pool(va).squeeze(dim=-1)
x = torch.cat([sst, t300, ua, va], dim=-1)
x = self.batch_norm(x)
x, _ = self.lstm(x)
x = self.avg_pool(x).squeeze(dim=-2)
x = self.linear(x)
return x
test_path = './tcdata/enso_round1_test_20210201/'
# 1. 测试数据读取
files = os.listdir(test_path)
test_feas_dict = {}
for file in files:
test_feas_dict[file] = np.load(test_path + file) # 222
# 2. 结果预测
device = 'cpu'
model = simpleSpatailTimeNN().to(device)
# model.load_state_dict(torch.load('./user_data/model2_state1.pth',map_location=torch.device('cpu')))
model.eval()
test_predicts_dict = {}
for file_name, val in test_feas_dict.items():
test_sst = torch.from_numpy(val[:, :, :, 0]) \
.to(device).float().unsqueeze(0)
test_t300 = torch.from_numpy(val[:, :, :, 1]) \
.to(device).float().unsqueeze(0)
test_ua = torch.from_numpy(val[:, :, :, 2]) \
.to(device).float().unsqueeze(0)
test_va = torch.from_numpy(val[:, :, :, 3]) \
.to(device).float().unsqueeze(0)
preds = model(test_sst, test_t300, test_ua, test_va)
output = preds.cpu().detach().squeeze().numpy()
test_predicts_dict[file_name] = output
# 3.存储预测结果
for file_name, val in test_predicts_dict.items():
np.save('./result/' + file_name, val)
def make_zip(source_dir='./result/', output_filename='result.zip'):
zipf = zipfile.ZipFile(output_filename, 'w')
pre_len = len(os.path.dirname(source_dir))
source_dirs = os.walk(source_dir)
print(source_dirs)
for parent, dirnames, filenames in source_dirs:
print(parent, dirnames)
for filename in filenames:
if '.npy' not in filename:
continue
pathfile = os.path.join(parent, filename)
arcname = pathfile[pre_len:].strip(os.path.sep) # 相对路径
zipf.write(pathfile, arcname)
zipf.close()
make_zip()
device用的是cpu,因为我发现cuda好像不太行,其实写'cuda' if torch.cuda.is_available() else 'cpu'也是可以的- 在代码中没有创建
result文件夹的代码,所以必须自己手动创建一个result空文件夹,否则运行会报文件夹不存在的错误 - 创建一个userdata文件夹,里面存放
model2_state1.pth,用于加载模型数据。(这行被注释了,后面会说) - #222处我用到了
np.load(test_path + file),所以如果是文件夹的话,它是load不了的,因此前面我才会把label文件夹删了,不然他会报IsADirectoryError。但是也有人说他没删也不报错,我不太懂,后面再看看。
3、requirements文本文件
首先pip install pipreqs,安装完毕,在当前目录地址栏输入powershell回车

在powershell中输入pipreqs --encoding=utf8 --force
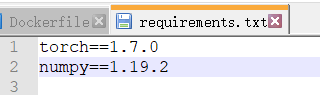
然后他应该会弹出INFO: Successfully saved requirements file in .\requirements.txt
打开requirements.txt查看,这俩是可以删掉的,后面会说。
4、shell文件
用Notepad++新建文件,然后保存为run.sh
文件内容如下
#!/bin/sh
CURDIR="`dirname $0`" #获取此脚本所在目录
echo $CURDIR
cd $CURDIR #切换到该脚本所在目录
python model3.py
5、dockerfile文件
使用Notepad++新建文件保存为dockerfile,不带扩展名
# Base Images
## 从天池基础镜像构建
# FROM registry.cn-shanghai.aliyuncs.com/tcc-public/python:3
FROM registry.cn-shanghai.aliyuncs.com/tcc-public/pytorch:1.4-cuda10.1-py3
## 把当前文件夹里的文件构建到镜像的根目录下(.后面有空格,不能直接跟/)
ADD . /
## 指定默认工作目录为根目录(需要把run.sh和生成的结果文件都放在该文件夹下,提交后才能运行)
WORKDIR /
## Install Requirements(requirements.txt包含python包的版本)
## 这里使用清华镜像加速安装
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
#RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
## 镜像启动后统一执行 sh run.sh
CMD ["sh", "run.sh"]
用了天池的PyTorch基础镜像
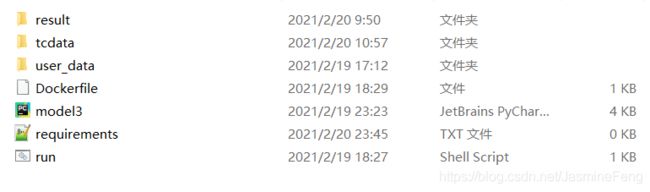
至此,我们应该有这些:
6、Powershell
在当前目录输入powershell回车,进入shell命令行。
注意,下面的<>及其中的内容要根据实际情况替换,<>相当于定界符,本身是不用输入的
docker login --username=<用户名> registry.cn-shanghai.aliyuncs.com
这个输完了会让我们输Password,这个时候我们是看不到自己输的密码的
如果用户名密码匹配的话,会弹出Login Succeededdocker build -t <公网地址>/<版本号> .
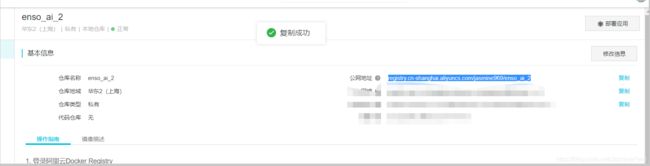
公网地址在这里看,复制一下。版本号我们自己定一个,建议:项目名+日期。
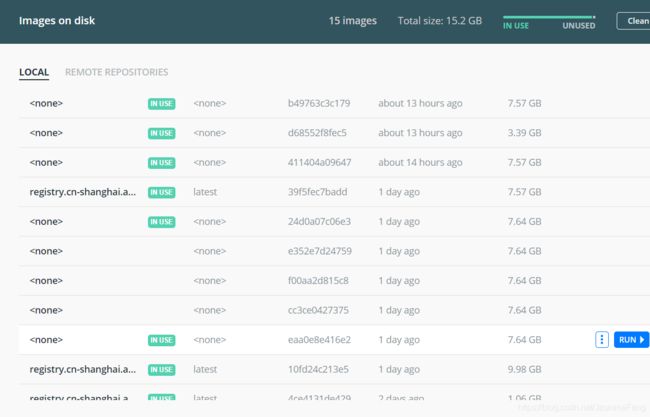
注意:每次更新文件,都要重新build一次,版本号也要自己更新,然后之前的镜像版本就可以remove了,嗯,养成一个好习惯!
如果不更新版本号的话,就会出现这种局面,好多
然后,版本号后面要跟一个空格,再跟一个英文句点.
回到我们的shell命令行,这个build是要花点儿时间的,大家也知道,torch库下载安装多么麻烦,我昨天用了一个小时多一点才构建完成。
每次build都要重新装torch库,简直要把人逼疯,如果有小伙伴知道怎么能够快速从上次的镜像构建当前镜像,可以在评论区告诉我,谢谢。
我当时动了点儿心思,我想我既然是从阿里云的PyTorch镜像构建的,那我requirements.txt里为啥还要放torch库呢,我就删了,然后运行就报错了,说是torch版本太低,不支持model.load_state_dict,于是乎我就把py文件里这行代码注释掉了,反正调试阶段嘛,最终结果准确度不重要。这样一来,就是torch随机初始化的模型。改了之后,果然不报错了。我索性在requirements.txt中把numpy也删掉了,同样没报错,这样build就可以瞬间完成了。docker run <公网地址>/<版本号> sh run.sh
版本号就是我们之前自定义的,应该还没忘吧?当然,我们也有可能忘了,幸好我们已经build了,这时我们可以在docker destop里查看了,把光标移动到镜像地址上,就会弹出完整地址了,(他全是大写的,希望我们至少记住版本号大小写),如果我们连这个也忘了,那就去看看shell命令行的历史记录吧。
因为我用的是cpu,所以用的是这条命令,如果用gpu,则nvidia-docker run 公网地址/版本号 sh run.sh,如果之前你都按部就班的做了,这步是不会报错的。
正常会弹出
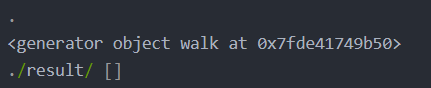
假如出错了,一般是py文件问题,比如找不到文件的error,还有之前那个IsADirectoryErrordocker push <公网地址>/<版本号>推送到镜像仓库,如果出错,可能没登录
7、提交结果

用户名是阿里云的用户名,不是docker的用户名,(我的这两个确实不一样)。
镜像路径带上版本号,就是之前<公网地址>/<版本号>的格式。
你可能要等一会,应该不会超过1分钟,如果超过一分钟还在waiting,我觉得可能是提交失败了。
![]()
官网上说了出现这个的可能原因,其实还有一个,就是你在powershell里面push了嘛?
我之前一直在解决docker run的bug,debug完以为大功告成了,直接提交结果,提交十几次了总不成功,甚至一度 产生退赛的想法。
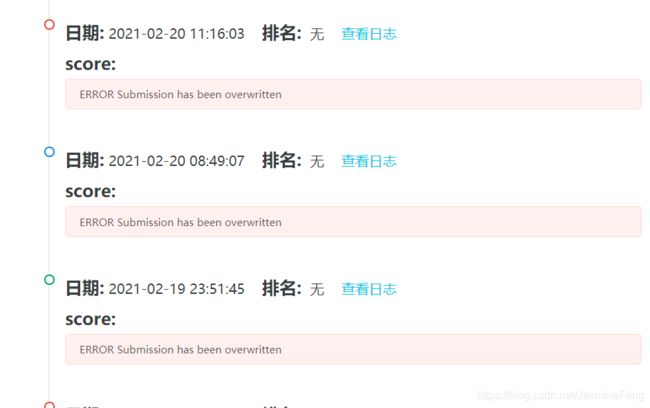

后来有人提醒我可能是我没push,我才反应过来,简直被自己蠢哭,于是我终于有score了红红火火恍恍惚惚。
P.S. 负分是正常的,因为模型权重偏置都是随机初始化的。

——————————————————————————————————————
待解决的问题:怎么利用上次build好的镜像快速build当前镜像?