论文解读:DeepEMD小样本图像分类
创新点
引入EMD距离度量方式,通过寻找各个图块之间的最佳匹配方式来计算距离
知识准备:陆地移动距离(Earth Mover’s Distance,EMD)
假设有一系列的货源地S={ |i=1,...,m}和一系列的目的地D={
|i=1,...,m}和一系列的目的地D={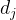 |j=1,...,k},si和dj分别表示货源地i的货物供应量(me:问题中只有一种货源,只不过每个货源地拥有不同的数量)和目的地j的需求量,cij表示两地之间的单位运输成本,xij表示两地之间的运输量,那么运输问题的目的是寻找运输成本最低的运输方案
|j=1,...,k},si和dj分别表示货源地i的货物供应量(me:问题中只有一种货源,只不过每个货源地拥有不同的数量)和目的地j的需求量,cij表示两地之间的单位运输成本,xij表示两地之间的运输量,那么运输问题的目的是寻找运输成本最低的运输方案![]() 。需要注意的是,一个目的地可以被任何一个货源地所提供,只是运输成本有所不同而已。过程如下
。需要注意的是,一个目的地可以被任何一个货源地所提供,只是运输成本有所不同而已。过程如下


上式:运输给这k个目的地中第i个资源的总和=货源地i的货物供应量
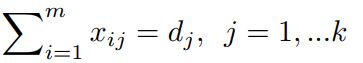
上式:第j个目的地的需求量dj=m个货源地分别对第j个目的地提供的供应量之和
创新点1:EMD运用在图像特征中求两幅特征图之间相似性
直接从图片本身出发,把EMD用作一种距离度量指标
本文将S 和D 分别看作支持集图像和查询集图像对应的特征图,特征图中的每个像素点都是一个带有权重的结点,而si 和dj 分别对应各个结点的权重,支持集特征图每个像素点对应的特征向量为ui,而查询集特征图每个像素点对应的特征向量为vj,则两个结点间的运输成本cij可定义为
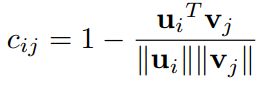
回忆高中向量知识,应该可以看出后面这项其实就是两个向量之间夹角的余弦。也就是说,如果两个nodes完全相同,那么夹角为0,余弦值就是1。于是乎这个距离就是0。因此,越相似的nodes,产生的cost越小。这个cij就对应之前的货源地到目的地的距离,也就是运输距离。
通过求解上述的线性规划问题,寻找最优的运输方案![]() ,则两幅特征图之间的相似性可由下式计算
,则两幅特征图之间的相似性可由下式计算

然后作者证明了求解![]() 的过程是可微分的(在3.3. End-to-End Training那个板块),因此可以采用梯队下降的方式进行求解。
的过程是可微分的(在3.3. End-to-End Training那个板块),因此可以采用梯队下降的方式进行求解。
me:当![]() 时,越相似
时,越相似 越小,所以支持集图片U与查询集图片V的相似度
越小,所以支持集图片U与查询集图片V的相似度![]() 就越小。作者应该是想越相似的两张图片,相似度
就越小。作者应该是想越相似的两张图片,相似度![]()
越大,所以才添加了了负号,最终使![]()
me:只是利用EMD将问题用符号抽象化而已,这里并没有感觉到有创新的地方。
创新点2:相互参考机制(cross-reference mechanism)
me:支持集的信息太过繁杂,为了使得支持集更关注查询集的信息,的计算加入了查询集的特征。
为了解决了杂乱背景和大的类内外观变化带来的挑战
上述求解过程中结点上的权重和 是很重要的,他直接影响了运输方案的设计,因此提出了一种相互参考机制(cross-reference mechanism),权重si 计算过程如下(dj 类似)

(me:那么dj 应该是按下面这么计算![]() )
)
通过比较两方结点之间的关系来计算每个结点处的权重,这样做的目的是对于方差较大,变化较多的背景区域分配更少的权重,而对于两幅图中共现的目标区域分配更多的权重
另一种解释(来自文章2):
所以对于本文的问题,应该如何确定一个两张图片之间合适的权重?在彩色图片修复领域,通常颜色越占主导地位,像素越多的nodes会得到越大的权重。但是在小样本领域,像素越多不一定能够反映越多信息,图片中包含了许多高级的语义信息。所以很自然地能想到,既然要提取语义信息,那就得区分前景和背景。相对来说,前景肯定包含更多语义信息,故而更重要。那么怎么找到前景?两张图片中共同出现的区域更可能是前景。于是本文提出了cross-reference mechanism(交叉参照原理)。
再对所有的权重做正则化处理
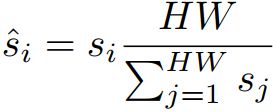
me:这样的话![]()
创新点3:Structured Fully Connected Layer
Standard Fully Connected Layer

Structured Fully Connected Layer
涉及的参数比标准的全连接层更多了,所以这篇论文更吃显存了。
在结构化全连接层中,我们学习了每个类别的一组向量作为原型,而不是一个向量,这样我们就可以使用结构化距离函数地球移动距离(EMD)来进行图像分类。
在推理时,我们固定网络骨干,并使用随机梯度下降(SGD)从支持集中采样数据来学习结构化全连接层中的参数。经过几次优化迭代后,我们可以通过计算查询图像与SFC中每个原型之间的地球移动距离来生成类别得分。

如何拓宽到N-way Kshot task(这是DeepEMDv2提及的)
算法1

算法1解读:
算法1是一个N-way K-shot任务的测试集,其中N表示类的数量,K表示每个类的样本数量。![]()
为优化迭代次数。
算法的输入包括一个训练好的特征提取器Θ(亮点:这里用到了查询集的特征),一个支持集S(包含N个类的示例)和一个查询集Q(包含需要分类的示例)。
算法的输出为查询集的测试精度(testing accuracy, Acc)。
初始化一个SFC (structured fully connected)层,表示为Φ=Φ';
循环---开始
从1迭代到![]()
,每次从支持集S中采样一个小批量Bi
它使用模型[Θ(特征提取器), Φ(代表类别特征的矩阵)]对小批量Bi进行预测
计算预测的交叉熵损失(L%)
使用随机梯度下降(SGD)更新SFC层Φ
循环---结束
使用模型[Θ, Φ]对查询集Q中的图像进行预测。
计算预测的准确性(Acc)
返回查询集的精度(Acc)
总结
我们提出了一种采用地球移动距离作为距离度量的几次分类框架。隐式定理允许我们的网络端到端可训练。我们提出的设置节点权重的交叉参考机制在EMD的制定中是至关重要的,可以有效地减少不相关区域造成的负面影响。可学习的结构化全连接层可以在k-shot设置中直接对图像的密集表示进行分类
算法评价

EMD距离最早是应用于图像检索等领域的,本文将其引入图像分类算法中,主要是看中了其考虑局部图块之间的匹配关系。在先前的文章中我们也提到过,相对于将一整幅图像压缩(可以从图中FCN的过程看出来,H、W是不断通过池化被减小的)为一个高度抽象的特征向量,并计算两个特征向量之间的距离作为相似性度量的方式而言,通过比较各个局部图块之间的相似程度来反映两幅图像是否属于同一类别,则更为可靠和准确。但如果是每两个图块之间都逐一比对的话,这计算成本也过于高昂,于是作者就利用EMD方法,通过线性规划的方式寻找两幅图像各个图块之间的最佳匹配方式,并且为不同的位置的图块分配了不同的权重,类似于注意力机制,对于目标区域给予更多注意。
他人观点
为解决backbone网络会不知道在纷繁复杂的图片应该关注什么信息。
比如一张图,一个人牵着一只狗,标签为人,但由于网络在训练时可能只把狗作为标签(比如imagenet),因此提取特征时便关注狗去了,而不是人。为解决这类问题,dense-feature based方法应运而生,其核心思想是backbone出来的feature不通过global pooling,以此来保留空间信息(这个问题能否用通用创新点SPD解决?),对比不同图片的spatial feature map,从中找出对应关系,这样如果有两张图,其共性是人而不是狗,那通过这种人和人的对应关系就能把狗这一confounding factor给去除。这一类方法论文如:CAN[16]、CTX[2]、DeepEMD [10]、LDAMF[17]、MCL[18]。
原文链接:小样本学习只是一场学术界自嗨吗-CSDN博客
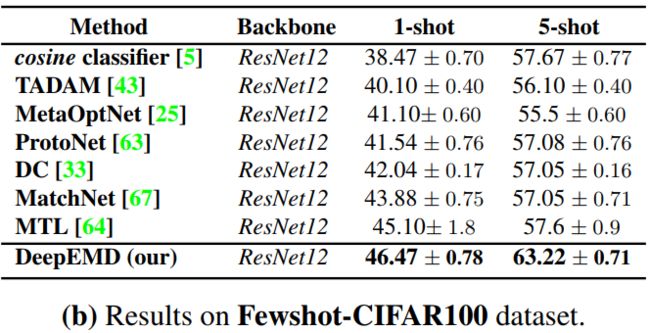
实验结果
实验在四个常见小样本数据集上:miniImageNet, tieredImageNet, Fewshot-CIFAR100 (FC100) and Caltech-UCSD Birds-200-2011 (CUB).


论文下载
DeepEMD Few-Shot Image Classification with Differentiable Earth Mover’s.pdf

DeepEMDv2 Differentiable Earth Mover’s Distance for Few-Shot Learning.pdf

参考资料
文章参考资料
文章1:
论文阅读笔记《DeepEMD_ Few-Shot Image Classification with Differentiable Earth Mover’s Distance》-CSDN博客 (2023_12_5 15_40_10).html
链接:论文阅读笔记《DeepEMD: Few-Shot Image Classification with Differentiable Earth Mover’s Distance》-CSDN博客
文章2:
【小样本分类】DeepEMD_ Differentiable Earth Mover’s Distance for Few-Shot Learning - 知乎 (2023_12_8 21_11_45).html
链接:【小样本分类】DeepEMD: Differentiable Earth Mover’s Distance for Few-Shot Learning - 知乎
视频参考资料:
【CVPR 2020】小样本学习论文解读 | DeepEMD: Few-Shot Image Classification..._哔哩哔哩_bilibili