论文浅尝 | 大型语言模型的人类对齐

笔记整理:方润楠、习泽坤,浙江大学硕士,研究方向为自然语言处理
链接:https://arxiv.org/abs/2307.12966
概述
这份综述探讨了针对大型语言模型(LLMs)的人类期望进行对齐的技术,涵盖了以下几个方面:1. 数据收集:有效收集LLMs对齐所需的高质量指令的方法,包括使用NLP基准、人工注释和利用强大的LLMs。2. 训练方法:对LLMs对齐采用的主要训练方法进行详细审查。涵盖了有监督微调、在线和离线人类偏好训练以及参数高效训练机制。3. 模型评估:评估人类对齐LLMs效果的方法,呈现了多方面的评估方法。综合总结并梳理了研究发现,为领域内对理解和推进LLMs对齐以更好地适应人类导向任务和期望感兴趣的人提供了有价值的资源,同时也指出了未来几个有前景的研究方向。
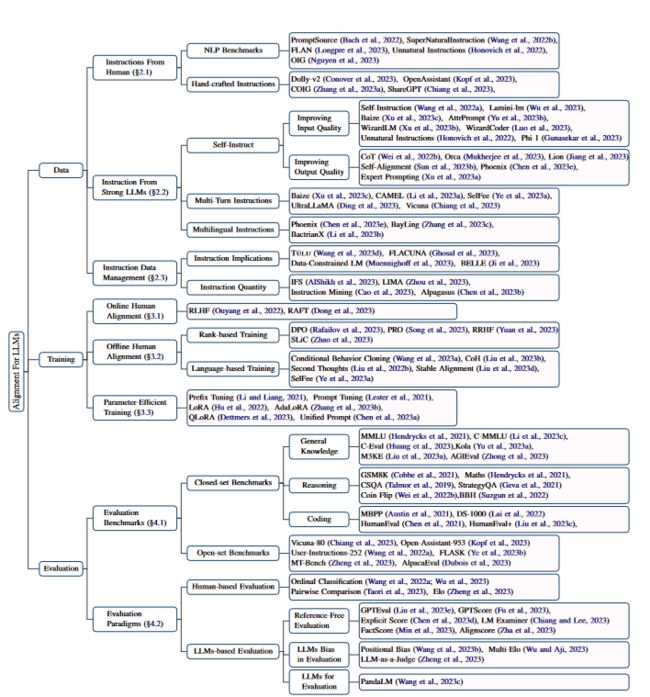
对齐数据集
将LLMs与人类期望对齐需要收集高质量的训练数据,这些数据真实地反映了人类的需求和期望。在本调研中,我们将指令概念化为Ik = (xk, yk),其中xk表示指令输入,yk表示相应的回复。这些数据可以来自多种来源,包括人工生成的指令和由强大的LLMs生成的指令。在本节中,我们总结了这些指令生成方法,并介绍了构建多样化训练指令组合的有效策略。
人类指令构造
一个很容易想到的方法就是将现有的自然语言处理基准转化为自然语言指令。各种各样的基准代表了各种多样且异构的自然语言处理任务,如对话、推理任务和编码任务,都统一在语言指令的框架下。在每个NLP基准中,让注释员创建了几个自然语言模板,将所有输入数据融入到一个连续的文本中。用来增强LLMs在训练任务的多任务学习能力,提高对未知任务的泛化能力。

虽然由NLP基准构建数据集很轻松,但是由于许多数据集专注于小而特定的数据集,这意味着产生的指令适用范围相对较窄,具有局限性。因此,它们可能无法满足现实世界应用的复杂需求,例如进行动态人类对话。为了应对上述问题,可以通过有意识的手动注释来构建指令。如何有效设计一个人机协作的注释框架成为关键问题。
例如Kopf[1](2023)等人使用超过13,000名国际标注者构建了包含超过10,000个对话的OpenAssistant语料库。注释过程包括a)为对话编写初始提示;b)以助理或用户身份回复;c)对对话质量进行排名,以明确提供人类偏好。因此,这个语料库可以用于LLMs的SFT和人类偏好对齐训练。Zhang[2]等人从现有的英语指令数据集构建了高质量的中文指令。他们首先将英语指令翻译成中文,然后验证这些翻译是否可用。最后,他们雇佣标注者将指令进行纠正和重新组织,以选择的语料库中的任务描述、输入、输出格式。
强语言模型构造
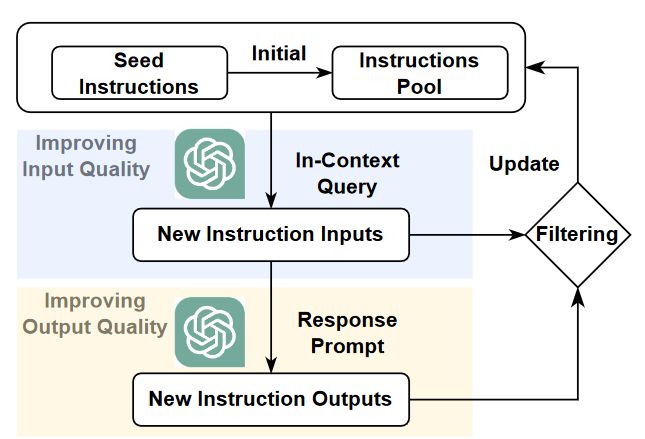
自构建利用了大语言模型强大的in-context learning能力,从人工注释的指令数据集中生成大量涵盖了各种不同的主题和任务类型的指令,自动生成的指令随后经过如下图所示的质量控制筛选流程,提高指令质量,这个迭代过程将持续进行,直到达到所需的数据量。
在提高输入质量模块中,主要目标是提高输入指令的多样性,例如Yu[3](2023)等人将将元信息(例如长度、主题、风格)添加到数据生成prompt中可以有效地消除生成的合成数据中的偏见,并提高这些合成数据的多样性。
在提高输出质量模块中,需要根据不同的情况选择不同方式提高输出质量,总体上可以分为以下四类:Reasoning-Provoking Conditions,Hand-crafted Guiding Principles,Role-playing Conditions,Difficulty-monitoring Conditions。
在之前的部分中,我们主要关注收集合成的单轮指令。然而,与人类良好对齐的LLMs应该能够在基于对话的环境中与用户进行交互。为了实现这一目标,一些研究工作尝试从强语言模型中收集合成的多轮指令。在将LLaMA与人类对齐时,Vicuna利用了来自ShareGPT的指令。Li[4]等人(2023)提出了一个名为CAMEL的“角色扮演”框架,其中人类标注者首先提供一个主题,然后分别激发LLMs成为“AI用户”和“AI助手”来讨论这个主题。
上述生成的指令或对话大多是基于英语的。为了将LLMs与使用其他语言的人类对齐,将现有的英语资源扩展到多语种资源是迫切且必要的。一个直接的想法是将指令的输入和输出翻译成目标语言。Chen[5]等(2023)提出了两种翻译策略:(a)后回答策略,首先将指令输入翻译成目标语言,然后提示强大的LLMs回答。这可能会保留目标语言中嵌入的特定文化模式,但输出质量可能较低,因为现有的强大LLMs通常以英语为主导;(b)后翻译策略,首先提示强大的LLMs用英语回应指令,然后再翻译输入和输出。这种方法可以获得高质量的输出文本,但会失去特定的文化信息。
指令数据管理
正如上面讨论的,有多种方法专注于从不同来源生成高质量的指令。因此,有效地管理所有这些指令数据在LLMs的对齐中变得至关重要。Ji[6]等(2023)展示了训练指令的总数的增加对于标准NLP任务(例如信息提取、分类、封闭型问答、摘要)是有益的。然而,这对于复杂的推理任务(如数学、编码)影响微乎其微。此外,Muennighoff[7]等(2023)发现,添加约50%的编程指令不仅不会影响一般对话表现,还会增强LLMs的推理能力。
指令数据管理中的另一个问题是实现有效的LLM对齐所需的最佳指令数据量。AlShikh[8]等(2023)通过引入一种称为IFS的新型早停止准则来解决这个问题。IFS的基本思想是,鉴于输入的文本前缀,基础性LLMs通常会预测后续的标记并生成“续写式”的输出,而经过完全调整的LLMs会将输入前缀解释为问题,从而生成“回答式”的输出。他们发现LLaMA大约需要8000个指令。更多的指令可能会引起语义的转变。Zhou[9]等人(2023)类似地发现,仅需要6000个高质量的指令就足以与人类的偏好达成一致。
对齐训练
基于SFT的方法用于使用收集的指令数据对现有的基础LLM进行微调,以使其与人类一致。SFT通过计算交叉熵损失来帮助LLM理解提示的语义含义并生成有意义的回答。SFT的主要限制是只教授LLM关于最佳回答,无法提供对次优回答的细粒度比较。
在线人类偏好训练
强化学习从人类反馈中学习(RLHF)(Ouyang[10]等,2022年)旨在在PPO框架下从外部奖励模型中学习人类偏好信号。具体而言,RLHF包括三个主要阶段:
第一步:收集高质量的指令集并对预训练的LLM进行SFT微调。
第二步:收集手动排名的比较回答对,并训练一个奖励模型IR来验证生成回答的质量。
第三步:在PPO强化学习框架下,通过IR计算的奖励来优化SFT模型(策略)。
在第三步中,为了减轻过度优化问题,Ouyang[11]等人(2022年)在当前模型权重和第一步获得的SFT模型权重之间添加了KL散度正则化。然而,尽管在学习人类偏好方面有效,但PPO训练在实施和稳定训练方面存在困难。因此,Dong[12]等人(2023年)尝试在上述过程中移除PPO训练,并提出一种新颖的奖励排序微调(RAFT)方法,该方法使用现有的奖励模型基于模型输出选择最佳的训练样本集。具体而言,RAFT首先采样一大批指令,然后使用当前LLM对这些指令进行回答。然后,通过奖励模型对这些数据进行排名,只选择前k个实例用于SFT。RAFT还可以用于离线人类偏好学习,在每个批次中将全局指令集持续更新为排名最高的指令。这样可以在每个步骤中连续更新全局指令集,以改善训练数据的质量。
离线人类偏好训练
使用已经存在的人类偏好数据集的对齐训练主要有两种方式,一种是基于排名的,另一种是基于自然语言的。
排名优化方法直接将人类偏好表达为一组回答的排名结果,并将排名信息直接纳入LLM的微调阶段。Rafailov[13]等人(2023年)提出了直接偏好优化(DPO)方法,它隐式地优化了与上述现有RLHF算法相同的目标(即带有KL散度项的奖励函数)PRO还添加了SFT训练目标以进行正则化。Zhao[14]等人(2023年)不同于调整奖励训练目标,他们首先使用各种排名函数(包括排名损失、边际损失、列表排名损失和期望排名损失)校准序列似然。此外,他们还探索了使用SFT训练目标和KL散度作为正则化项。在各种文本生成任务上的实验结果表明,KL散度项的排名损失表现最佳。Yuan[15]等人(2023年)提出了RRHF,使用类似上述的框架进一步优化LLaMA-7B以使其与人类偏好一致。RRHF基于列表排名损失,但根据实证结果去除了边际项。
有一些方法提出直接使用自然语言通过SFT注入人类偏好,因为强化学习算法很难优化,而LLM具有强大的文本理解能力。Chain of Hindsight(CoH)(Liu[16]等人,2023年)直接将人类偏好作为一对平行回应引入,这些回应使用自然语言前缀来区分低质量或高质量。如图4所示,在为每个模型输出分配人类反馈后,CoH将输入指令、LLM输出和相应的人类反馈连接在一起作为LLM的输入。值得注意的是,CoH仅将微调损失应用于实际的模型输出,而不是人类反馈序列和指令。在推理过程中,CoH直接将位置反馈(例如,好)放在输入指令之后,以鼓励LLM生成高质量的输出。值得注意的是, CoH还融入了SFT目标和随机词遮罩以防止LLM过拟合。
参数高效训练
参数高效一种旨在减少对大型语言模型(LLMs)进行微调的计算和数据要求的策略,以使其能够遵循特定的指令。与其更新所有参数不同,该方法选择性地冻结模型的大部分参数,只在训练过程中更新一小部分额外的参数。
参数有效训练的动机是在实现指令遵循的同时减少微调所需的计算和数据需求。通过冻结大量参数,可以减少对庞大的计算资源(如大型GPU内存)的需求。此外,它还减少了对专门用于指令训练的大规模数据集的依赖,而获取这些数据集可能具有挑战性且资源密集。
参数有效训练中微调的具体参数子集因方法和目标而异。通常的目标是识别和更新对指令遵循具有最显著影响的参数,同时将模型的其余部分保持不变。这个有限的额外参数集可以使用较小的数据集或甚至专门为指令遵循生成的合成数据进行训练,从而使训练过程更具可行性
通过采用参数有效训练策略,研究人员旨在在指令遵循和相关的计算、数据需求之间取得平衡。这种方法可以实现更实用和高效的LLMs训练,从而使其更易于应用于各种实际应用场景。
对齐效果评估
在收集指令并对LLM进行指令训练之后,我们最终需要考虑对对齐质量进行评估。
评估测试集
测试集主要分为闭环和开放测试集。在对齐质量的评估中,闭集基准测试主要包括通识知识、推理和编码等方面的测试。这些基准测试涵盖了不同领域和难度级别的问题,旨在评估LLM在各种任务中的表现。它们提供了一种客观的方法来衡量LLM在特定任务上的能力,并帮助发现LLM可能存在的盲点或改进的空间。这些基准测试对于评估LLM的对齐质量非常有帮助,并为研究人员和开发者提供了一种标准化的评估手段。如通识知识MMLU(Hendrycks[17]等,2021年)是一个用于评估LLM在零样本和少样本设置下的知识的英语基准测试,推理GSM8K和Maths)旨在评估LLM的算术推理能力。CSQA(Talmor等,2019年)和StrategyQA(Geva等,2021年)旨在评估常识推理能力,要求LLM利用日常生活常识在新情境中进行推理。代码HumanEval(Chen[]等,2021年)、HumanEval+(Liu[18]等,2023年)是广泛使用的基准测试,用于评估LLM的编码技能。
开放式基准测试的响应更加灵活多样,对齐的LLM通常会得到聊天式的问题或没有固定参考答案的主题。这些基准测试通过不同的方法来评估LLM的性能,如胜率比较、多轮对话评估和对齐技能评估。它们提供了一种更全面、更细粒度的评估方式,可以揭示LLM在不同方面的表现和能力。然而,由于开放式基准测试的灵活性,评估过程可能更加复杂,并且可能需要更多的人力和时间资源。在实际应用中,研究人员和开发者需要根据具体需求选择适合的基准测试,并结合闭集和开放式基准测试来评估LLM的对齐质量。
评估范式
基于人类的评估方法。自动评估指标,如BLUE和ROUGE,需要参考答案,并且与人类判断的相关性相对较低。因此,它们不适用于评估对开放式问题的回答。为了弥补这一差距,人类标注员被用来评估开放式模型回答的质量。Wang[19]等人(2022年);Wu[20]等人(2023年)提出在一种序数分类设置中评估回答质量,其中人类标注员被指示将每个回答分类为四个级别之一(可接受、轻微错误、重大错误和不可接受)。然而,其他一些研究发现这种分类注释策略严重依赖于标注员的主观性,可能导致较差的一致性。为了准确评估多个LLM,Zheng[21]等人(2023年)进一步引入了Elo评分系统,该系统计算象棋等零和博弈中玩家的相对技能水平。具体而言,在Elo系统中,玩家得分根据每个成对比较的结果和当前玩家得分进行更新。
基于人类评估的方法可能效率低下且昂贵,因此有研究提出了基于LLM的评估方法。这些方法利用LLM的文本能力直接对生成文本进行评估,无需参考文本或人工标注。可以使用复杂的输入指令来指导LLM评估生成文本的质量,并且可以进行多维度评估。此外,还提出了针对特定任务的LLM评估框架,如文本摘要、代码生成、开放式问答和对话。这些基于LLM的评估方法提供了一种有效的替代方案,可以在不依赖人工标注的情况下评估生成文本的质量。
总结与展望
LLM(Language Model)对齐的发展仍处于初级阶段,因此还有很大的改进空间。接下来,作者将讨论一些挑战以及相应的未来研究方向。
细粒度指令数据管理
尽管LLM对齐的研究非常活跃,但其中许多研究工作提出利用来自不同来源的训练指令,这使得在不同方法之间进行公正比较变得具有挑战性。正如在之前所讨论的那样,关于特定指令数据集的影响有一些有趣的发现。例如,FLAN和编程指令可以提高与LLM对齐的推理能力,而ShareGPT在广泛的基准测试中表现良好。然而,在指令数据管理的其他方面仍存在许多不明确的问题,包括指令数据的最佳质量控制、最佳指令训练顺序以及如何有效地混合不同的指令。这些研究努力最终可以实现细粒度的指令管理,使研究人员和实践者能够构建高质量的指令数据。
非英语语言的LLM对齐
现有的LLM对齐研究大多集中在英语领域。尽管许多方法如复杂指令生成和解释调整是与语言无关的,但它们只探索了基于英语的提示,并且尚不清楚这些提示在适应其他语言时的表现如何,严重阻碍了LLM在非英语地区的应用。有趣的是,我们希望了解以下两个方面的情况:1)这些对齐技术在各种语言中的表现,特别是在资源匮乏的语言中;2)如何有效地在不同语言之间传递LLM对齐的效果。
LLM对齐训练技术
大多数现有的对齐LLM都是基于简单的SFT(指令反馈训练)技术。然而,SFT并没有明确地将人类偏好纳入LLM中。因此,仅基于SFT对齐LLM可能需要更多的指令数据和训练资源。总体而言,对于将人类偏好融入LLM中的各种训练技术的效果缺乏全面的研究。因此,关键是提出一种资源受限的LLM对齐训练框架,其中某些对齐资源在一定程度上给定(例如,最多10,000条指令,5小时训练时间等),使研究人员和实践者能够验证各种训练方法的有效性。随着越来越多的指令数据可用,这种探索可以进一步推动有效和环对环境友好的LLM对齐解决方案的发展。
人为参与的LLM对齐数据生成
ShareGPT数据已广泛应用于LLM对齐。初步分析也表明,ShareGPT在广泛的自然语言处理任务中表现一致良好。这些结果表明,人类仍然是改进LLM对齐质量的关键因素。与传统的人工注释框架不同,其中人类根据指令提供注释,ShareGPT是一种人在循环中的对齐解决方案,人类可以自由确定LLM应该生成什么。这显示了人为参与的数据生成解决方案在LLM对齐中的巨大潜力。有趣的是,探索其他类型的人为参与的解决方案,以进一步促进LLM对齐,将会是一项有趣的研究方向。
人类-LLM联合评估框架
现有的LLM评估框架要么利用LLM进行有效评估,要么利用人类进行高质量评估。而最先进的LLM在各种自然语言处理任务中表现出类似或更优的评估能力。可以将LLM作为特殊的评估标注者,并开发LLM-人类联合评估框架,根据它们各自的优势为LLM和人类分配不同的评估任务,以保持LLM对齐评估过程的效率和质量。
参考文献:
[1]Andreas Kopf, Yannic Kilcher, Dimitri von Rutte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Rich’ard Nagyfi, ES Shahul, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Mattick. 2023. Openassistant conversations - democratizing large language model alignment. ArXiv, abs/2304.07327.
[2]Ge Zhang, Yemin Shi, Ruibo Liu, Ruibin Yuan, Yizhi Li, Siwei Dong, Yu Shu, Zhaoqun Li, Zekun Wang, Chenghua Lin, Wen-Fen Huang, and Jie Fu. 2023a. Chinese open instruction generalist: A preliminary release. ArXiv, abs/2304.07987.
[3]Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. 2023b. Large language model as attributed training data generator: A tale of diversity and bias. arXiv preprint arXiv:2306.15895.
[4]Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023a. CAMEL: communicative agents for "mind" exploration of large scale language model society. CoRR, abs/2303.17760.
[5]Zhihong Chen, Feng Jiang, Junying Chen, Tiannan Wang, Fei Yu, Guiming Chen, Hongbo Zhang, Juhao Liang, Chen Zhang, Zhiyi Zhang, Jianquan Li, Xiang Wan, Benyou Wang, and Haizhou Li. 2023e. Phoenix: Democratizing chatgpt across languages. CoRR, abs/2304.10453.
[6]Yunjie Ji, Yan Gong, Yong Deng, Yiping Peng, Qiang Niu, Baochang Ma, and Xiangang Li. 2023. Towards better instruction following language models for chinese: Investigating the impact of training data and evaluation. CoRR, abs/2304.07854.
[7]Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. 2023. Scaling data-constrained language models. arXiv preprint arXiv:2305.16264.
[8]Waseem AlShikh, Manhal Daaboul, Kirk Goddard, Brock Imel, Kiran Kamble, Parikshith Kulkarni, and Melisa Russak. 2023. Becoming self-instruct: introducing early stopping criteria for minimal instruct tuning. arXiv preprint arXiv:2307.03692.
[9]Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
[10] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems.
[11] Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. 2023. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767.
[12] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290
[13] Yao Zhao, Mikhail Khalman, Rishabh Joshi, Shashi Narayan, Mohammad Saleh, and Peter J Liu. 2023. Calibrating sequence likelihood improves conditional language generation. In The Eleventh International Conference on Learning Representations.
[14] Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. Rrhf: Rank responses to align language models with human feedback without tears.
[15] Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. 2023b. Languages are rewards: Hindsight finetuning using human feedback. arXiv preprint arXiv:2302.02676.
[16] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In International Conference on Learning Representations.
[17] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
[18] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023c. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210
[19] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022a. Self-instruct: Aligning language model with self generated instructions. CoRR, abs/2212.10560.
[20] Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. 2023. Lamini-lm: A diverse herd of distilled models from large-scale instructions. CoRR, abs/2304.14402.
[21] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。