Elasticsearch持久化过程详解
前言
这篇文章主要介绍Elasticsearch的索引工作机制,它是如何利用translog来保证数据的安全,以及我们在生产环境中如何优化translog的参数来最大化性能,主要会介绍到elastic中常见的2个操作:refresh和flush,以及这2个接口是如何保证数据能够被检索到的。
一、数据持久化
我们把数据写到磁盘后,还要调用fsync才能把数据刷到磁盘中,如果不这样做在系统掉电的时候就会导致数据丢失,这个原理相信大家都清楚,elasticsearch为了高可靠性必须把所有的修改持久化到磁盘中。
elastic底层采用的是lucene这个库来实现倒排索引的功能,在lucene的概念里每一条记录称为document(文档),lucene使用segment(分段)来存储数据,用commit point来记录所有segment的元数据,一条记录要被搜索到,必须写入到segment中,这一点非常重要,后面会介绍为什么elastic搜索是near-realtime(接近实时的)而不是实时的。
elastic使用translog来记录所有的操作,我们称之为write-ahead-log,我们新增了一条记录时,es会把数据写到translog和in-memory buffer(内存缓存区)中,如下图所示:
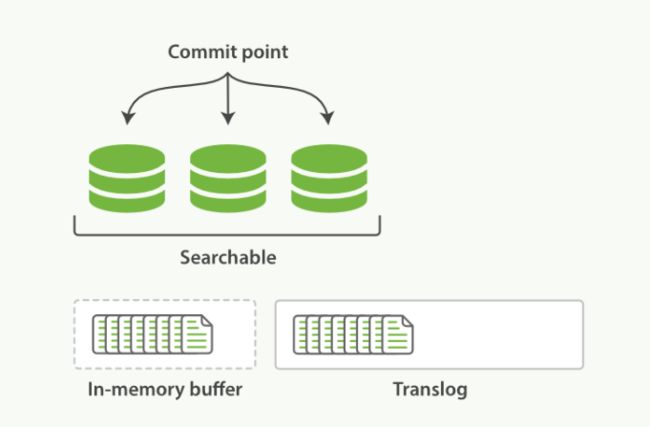
内存缓存区和translog就是near-realtime的关键所在,前面我们讲过新增的索引必须写入到segment后才能被搜索到,因此我们把数据写入到内存缓冲区之后并不能被搜索到,如果希望该文档能立刻被搜索,需要手动调用refresh操作。
1.逻辑全流程
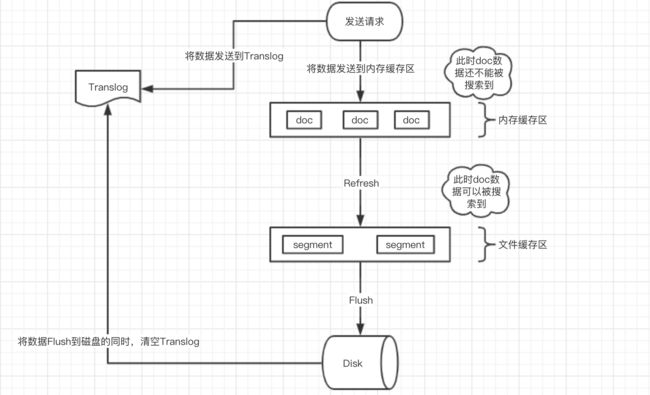
整体流程:
- 数据首先写入内存缓存区和Translog日志文件中。
当你写一条数据doc的时候,一方面写入到内存缓冲区中,一方面同时写入到Translog日志文件中。 - 内存缓存区满了或者每隔1秒(默认1秒),refresh将内存缓存区的数据生成index segment文件并写入文件系统缓存区,此时index segment可被打开以供search查询读取,这样文档就可以被搜索到了(注意,此时文档还没有写到磁盘上);然后清空内存缓存区供后续使用。可见,refresh实现的是文档从内存缓存区移到文件系统缓存区的过程。
- 重复上两个步骤,新的segment不断添加到文件系统缓存区,内存缓存区不断被清空,而translog的数据不断增加,随着时间的推移,Translog文件会越来越大。
- 当Translog长度达到一定程度的时候,会触发flush操作,否则默认每隔30分钟也会定时flush,其主要过程:
- 执行refresh操作将内存缓存区中的数据写入到新的segment并写入文件系统缓存区,然后打开本segment以供search使用,最后再次清空内存缓存区。
- 一个commit point被写入磁盘,这个commit point中标明所有的index segment。
- 文件系统中缓存的所有的index segment文件被fsync强制刷到磁盘,当index segment被fsync强制刷到磁盘上以后,就会被打开,供查询使用。
- translog被清空和删除,创建一个新的translog。
一、Refresh
1.Refresh操作
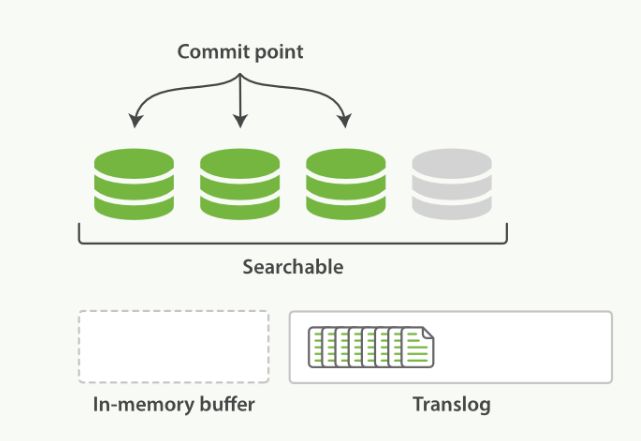
默认情况下,es每隔一秒钟执行一次refresh,可以通过参数index.refresh_interval来修改这个刷新间隔,执行refresh操作具体做了哪些事情呢?
- 所有在内存缓冲区中的文档被写入到一个新的segment中,但是没有调用fsync,因此内存中的数据可能丢失
- segment被打开使得里面的文档能够被搜索到
- 清空内存缓冲区
执行refresh后的状态如下图所示:
refresh的开销比较大,我在自己环境上测试10W条记录的场景下refresh一次大概要14ms,因此在批量构建索引时可以把refresh间隔设置成-1来临时关闭refresh,等到索引都提交完成之后再打开refresh,可以通过如下接口修改这个参数:
curl -XPUT 'localhost:9200/test/_settings' -d '{
"index" : {
"refresh_interval" : "-1"
}
}'另外当你在做批量索引时,可以考虑把副本数设置成0,因为document从主分片(primary shard)复制到从分片(replica shard)时,从分片也要执行相同的分析、索引和合并过程,这样的开销比较大,你可以在构建索引之后再开启副本,这样只需要把数据从主分片拷贝到从分片:
curl -XPUT 'localhost:9200/my_index/_settings' -d ' {
"index" : {
"number_of_replicas" : 0
}
}'执行完批量索引之后,把刷新间隔改回来:
curl -XPUT 'localhost:9200/my_index/_settings' -d '{
"index" : {
"refresh_interval" : "1s"
}
}'你还可以强制执行一次refresh以及索引分段的合并:
curl -XPOST 'localhost:9200/my_index/_refresh'
curl -XPOST 'localhost:9200/my_index/_forcemerge?max_num_segments=5'
2.Refresh API
POST /_refresh 刷新(Refresh)所有的索引。
POST /blogs/_refresh 只刷新(Refresh) blogs 索引。尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率:
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" 每30秒刷新 my_logs 索引。
}
}refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings
{ "refresh_interval": -1 } 关闭自动刷新。
PUT /my_logs/_settings
{ "refresh_interval": "1s" } 每秒自动刷新。refresh_interval 需要一个 持续时间 值, 例如 1s (1 秒) 或 2m (2 分钟)。 一个绝对值 1 表示的是 1毫秒 --无疑会使你的集群陷入瘫痪。
二、Flush
1.Flush操作
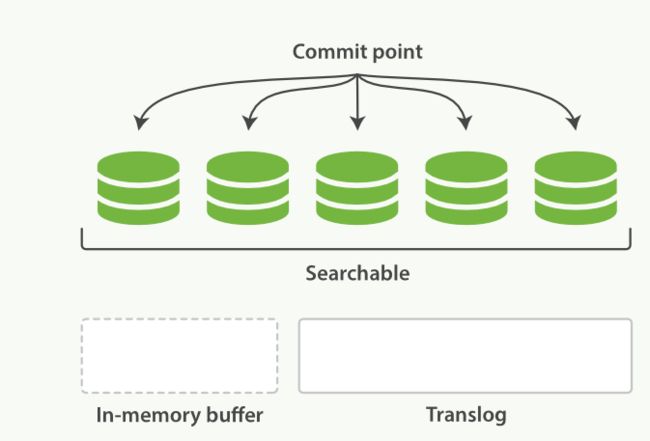
随着translog文件越来越大时要考虑把内存中的数据刷新到磁盘中,这个过程称为flush,flush过程主要做了如下操作:
- 通过refresh操作把所有在内存缓冲区中的文档写入到一个新的segment中
- 清空内存缓冲区
- 往磁盘里写入commit point信息
- 文件系统的page cache(segments) fsync到磁盘
- 删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了
flush之后的状态如下所示:
es有几个条件来决定是否flush到磁盘,不同版本的es参数有所不同,大家可以参考es对应版本的文档来查看这几个参数:es translog,这里介绍下1.7版本的flush参数:
- index.translog.flush_threshold_ops,执行多少次操作后执行一次flush,默认无限制
- index.translog.flush_threshold_size,translog的大小超过这个参数后flush,默认512mb
- index.translog.flush_threshold_period,多长时间强制flush一次,默认30m
- index.translog.interval,es多久去检测一次translog是否满足flush条件
上面的参数是es多久执行一次flush操作,在系统恢复过程中es会比较translog和segments中的数据来保证数据的完整性,为了数据安全es默认每隔5秒钟会把translog刷新(fsync)到磁盘中,也就是说系统掉电的情况下es最多会丢失5秒钟的数据。如果你对数据安全比较敏感,可以把这个间隔减小或者改为每次请求之后都把translog fsync到磁盘,但是会占用更多资源;这个间隔是通过下面2个参数来控制的:
- index.translog.sync_interval 控制translog多久fsync到磁盘,最小为100ms
- index.translog.durability translog是每5秒钟刷新一次还是每次请求都fsync,这个参数有2个取值:request(每次请求都执行fsync,es要等translog fsync到磁盘后才会返回成功)和async(默认值,translog每隔5秒钟fsync一次)
fsync指的是translog本身被写入磁盘的动作;flush指的是逻辑上的刷新,包含一系列逻辑操作。
- flush定义:事务日志 (transcation log)中的信息与存储介质之间的同步(同时清空事务日志);
- 30分钟定义:index_translog.flush_threshold_period该参数对应的默认值,它控制了强制自动事务日志刷新的时间间隔(即便是没有新数据写入)。强制进行事务日志刷新通常会导致大量的IO操作,因此有时当事务日志涉及少量数据时,更适合进行频繁的事务日志刷新操作。
- 5S的定义:index.gateway.local.sync参数的对应值,该参数定义了通过fsync系统调用同步事务日志数据的频率,默认5s一次。
三、Elastic配置文件
# /etc/elasticsearch/elasticsearch.yml
#
# ElasticSearch配置
#
cluster.name: forNe
# Node名称可以用来做路由
node.name: ne-01
node.datacenter: center
# Force all memory to be locked, forcing the JVM to never swap
bootstrap.mlockall: true
##线程池设置 ##
# 搜索池
threadpool.search.type: fixed
threadpool.search.size: 20
threadpool.search.queue_size: 100
# Bulk池
threadpool.bulk.type: fixed
threadpool.bulk.size: 60
threadpool.bulk.queue_size: 300
# 索引池
threadpool.index.type: fixed
threadpool.index.size: 20
threadpool.index.queue_size: 100
# Indices settings
indices.memory.index_buffer_size: 20%
indices.memory.min_shard_index_buffer_size: 12mb
indices.memory.min_index_buffer_size: 96mb
# Cache Sizes
indices.fielddata.cache.size: 15%
indices.fielddata.cache.expire: 6h
indices.cache.filter.size: 15%
indices.cache.filter.expire: 6h
# Indexing Settings for Writes
index.refresh_interval: 5s
index.translog.flush_threshold_ops: 50000