八. 实战:CUDA-BEVFusion部署分析-学习spconv的优化方案(Implicit GEMM conv)
目录
-
- 前言
- 0. 简述
- 1. 什么是Implicit GEMM Conv
- 2. Explicit GEMM Conv
- 3. Implicit GEMM Conv
- 4. Implicit GEMM Conv优化
- 5. spconv和Implicit GEMM Conv
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第八章——实战:CUDA-BEVFusion部署分析,一起来学习 spconv 的优化方案(Implicit GEMM conv)
Note:之前在学习杜老师的课程中有简单记录过 Sparse Convolution 的一些基础知识,感兴趣的可以看下:复杂onnx解决方案(以sparseconv为例)
课程大纲可以看下面的思维导图
0. 简述
本小节目标:理解 Implicit GEMM Conv 与 Explicit GEMM Conv 的区别,跳过 im2col 计算索引的方法,以及与 spconv 的关联性
这节给大家讲解第八章节第 5 小节,学习 spconv 的优化方案,那这一小节我们从 Implicit GEMM Conv 隐式 GEMM Conv 方式去看 spconv 是怎么加速的
1. 什么是Implicit GEMM Conv
首先我们回顾一下上节课讲的 Explicit GEMM Conv,在实现显式的 GEMM Conv 过程中我们需要做 im2col,而 im2col 会分配额外的空间,这一部分会造成一定的 overhead。但是我们回顾下之前讲的课程知道其实对于 n 维的 tensor 它都可以转化成一个二维的 Matrix,那这也就意味着二维 Matrix 上的每个点它其实都是能够通过计算的方式得到这个点到底是 tensor 中的哪一个数据,也就是说存在下面的对应关系:
- M ( i , j ) = input ( c i n , i h , i w ) M(i,j) = \text{input}(cin, ih, iw) M(i,j)=input(cin,ih,iw)
- N ( k , j ) = weight ( c o u t , c i n , k h , k w ) N(k,j) = \text{weight}(cout,cin,kh,kw) N(k,j)=weight(cout,cin,kh,kw)
- P ( i , j ) = output ( c o u t , o h , o w ) P(i,j)= \text{output}(cout,oh,ow) P(i,j)=output(cout,oh,ow)
换句话说,即便不做 im2col,只要知道这个对应关系,也就是索引,我们就可以把
input ( c i n , i h , i w ) ∗ weight ( c o u t , c i n , k h , k w ) = output ( c o u t , o h , o w ) \text{input}(cin,ih,iw) * \text{weight}(cout,cin,kh,kw)=\text{output}(cout,oh,ow) input(cin,ih,iw)∗weight(cout,cin,kh,kw)=output(cout,oh,ow)
转换成
M ( i , j ) × N ( k , j ) = P ( i , j ) M(i,j)\times N(k,j)=P(i,j) M(i,j)×N(k,j)=P(i,j)
从而避免 im2col 的额外开销,预先把数据按照索引把数据从 global memory 放到 shared memory 中做 warp 级别的加速,结合 cutlass 可以在 Tensor Core 上高速实现 GEMM 计算,这就是 Implicit GEMM Conv 的一个优势。
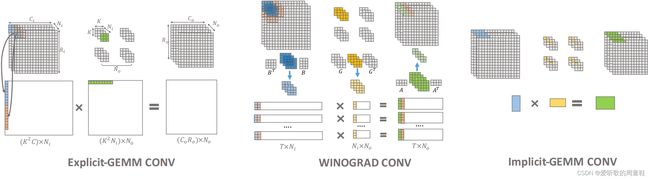
如上图所示,Explicit GEMM Conv 会有 im2col 矩阵变化这么一个操作,但是 Implicit GEMM Conv 把这个过程给 skip 掉了
那我们简单讲了 Implicit GEMM Conv 隐式计算,Implicit GEMM Conv 的关键点是如何找到这个 n 维 tensor 和 2D matrix 的对应关系,这里大家可以稍微思考一下,这个转换比较有意思。比如以 input 这个 Tensor 为例,我们要找的就是 c i n , i h , i w cin,ih,iw cin,ih,iw 和 i , k i,k i,k 之间的对应关系,这个是我们需要计算的一个东西,大家可以自己拿笔算一下这个是怎么转换的。
2. Explicit GEMM Conv
我们先来回顾一下 Explicit GEMM Conv,整个过程如下图所示:
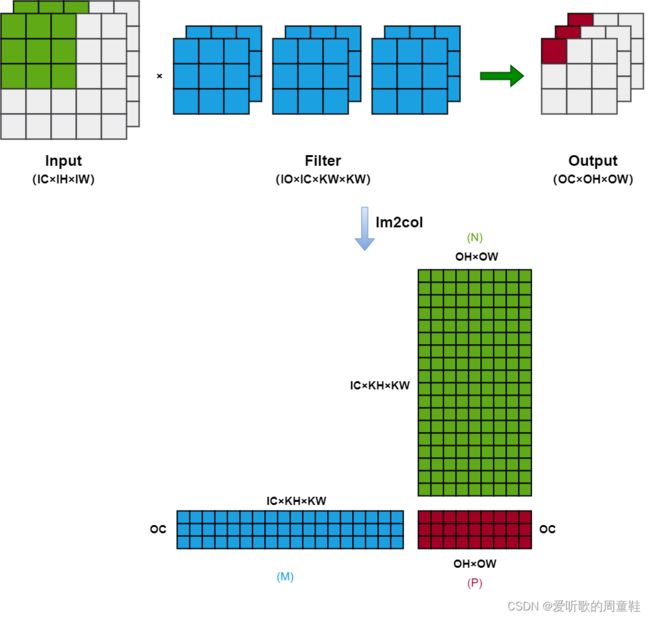
图中绿色矩阵部分是 input 转换过来的,我们记作 N N N,蓝色矩阵部分是 filter 转换过来的,我们记作 M M M,红色矩阵部分则是 output 转换过来的,我们记作 P P P。
那如果说我们有了这个对应关系之后,我们可以手动实现一个 ExplicitGEMMConv 在 im2col 之后的计算,代码如下所示:
void im2colOnHost(
float* filter, float* input, float* output,
float* M, float* N, float* P,
int IC, int IH, int IW,
int KH, int KW,
int OC, int OH, int OW)
{
// 大家感兴趣的可以实现一下
}
void ExplicitGEMMConvOnHost(
float* filter, float* input, float* output,
int IC, int IH, int IW,
int KH, int KW,
int OC, int OH, int OW)
{
float* M = (float*)malloc(OC * IC * KH * KW * sizeof(float));
float* N = (float*)malloc(OH * OW * IC * KH * KW * sizeof(float));
float* P = (float*)malloc(OC * OH * OW * sizeof(float));
im2colOnHost(
filter, input, output,
M, N, P,
IC, IH, IW,
KH, KW,
OC, OH, OW);
for (int i = 0; i < OC; i++){
for (int j = 0; j < OH * OW; j++){
float sum = 0;
for (int k = 0; k < IC * KH * KW; k++){
float a = M[i * IC * KH * KW + k];
float b = N[k * OH * OW + j];
sum += a * b;
}
P[i * OC + j] = sum;
}
}
}
首先 ExplicitGEMMConvOnHost 函数传入的是 input、filte、output 三个参数以及它们对应的各个维度值,然后我们把他们转换成矩阵,然后计算,最后把结果写回 output。
首先我们需要分配各个 tensor 所对应的二维矩阵的空间,分配之后我们开始执行 im2colOnHost 这个函数,大家感兴趣的可以自己实现一下,那实现 im2col 之后我们就得到了各个 tensor 所对应的矩阵,那么我们去遍历每一个元素再按照维度进行一个乘加运算填充到输出矩阵 P P P 中即可,那这就是 Explicit GEMM Conv 的一个计算过程。
3. Implicit GEMM Conv
下面我们来看 Implicit GEMM Conv 的计算过程,我们先规定下:
-
input, filter, output 是 n n n 维的 tensor
-
N N N, M M M, P P P 是 2 维的 matrix
-
N N N, M M M, P P P 分别是 input,filter,output 通过 im2col 得到的 matrix
-
I C IC IC, I H IH IH, I W IW IW 是 input 的 c c c, h h h, w w w 的大小
-
K H KH KH, K W KW KW 是 kernel 的 h h h, w w w 的大小
-
O C OC OC, O H OH OH, O W OW OW 是 output 的 c c c, h h h, w w w 的大小
-
i c ic ic, i h ih ih, i w iw iw 分别是 input 的 c c c, h h h, w w w 上的索引
-
k h kh kh, k w kw kw 分别是 kernel 的 h h h, w w w 上的索引
-
o c oc oc, o h oh oh, o w ow ow 分别是 output 在 c c c, h h h, w w w 上的索引
-
i i i 是 P P P 和 M M M 在 y y y 方向的索引
-
j j j 是 P P P 和 N N N 在 x x x 方向的索引
-
k k k 是 M M M 在 x x x 方向, N N N 在 y y y 方向的索引
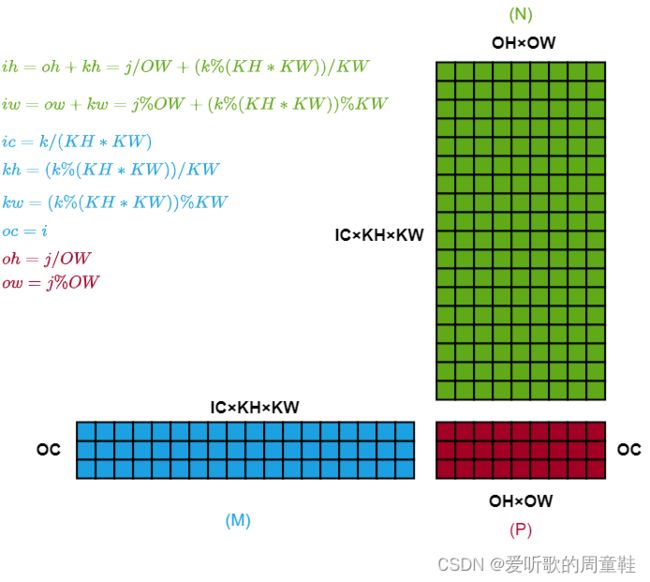
那么对于 P P P 和 output,我们可以得到如下关系:
- o c = i \color{#A20025}oc = i oc=i
- o h = j / O W \color{#A20025}oh = j/OW oh=j/OW
- o w = j % O W \color{#A20025}ow = j\%OW ow=j%OW
可以得到 P ( i , j ) = output ( o c , o h , o w ) \color{#A20025}P(i,j)=\text{output}(oc,oh,ow) P(i,j)=output(oc,oh,ow)
对于 M M M 和 filter,我们可以得到如下关系:
- i c = k / ( K H ∗ K W ) \color{#1BA1E2}ic = k / (KH * KW) ic=k/(KH∗KW)
- k h = ( k % ( K H ∗ K W ) ) / K W \color{#1BA1E2}kh = (k\%(KH * KW))/ KW kh=(k%(KH∗KW))/KW
- k w = ( k % ( K H ∗ K W ) ) % K W \color{#1BA1E2}kw = (k\%(KH * KW))\% KW kw=(k%(KH∗KW))%KW
- o c = i \color{#1BA1E2}oc = i oc=i
可以得到 M ( i , k ) = filter ( o c , i c , k h , k w ) \color{#1BA1E2}M(i,k)=\text{filter}(oc,ic,kh,kw) M(i,k)=filter(oc,ic,kh,kw)
对于 N N N 和 input,我们可以得到如下关系:
- i c = k / ( K H ∗ K W ) \color{#60A917}ic = k/(KH * KW) ic=k/(KH∗KW)
- i h = o h + k h = j / O W + ( k % ( K H ∗ K W ) ) / K W \color{#60A917}ih = oh+kh=j/OW+(k\%(KH * KW))/ KW ih=oh+kh=j/OW+(k%(KH∗KW))/KW
- i w = o w + k w = j % O W + ( k % ( K H ∗ K W ) ) % K W \color{#60A917}iw = ow+kw=j\%OW+(k\%(KH * KW))\% KW iw=ow+kw=j%OW+(k%(KH∗KW))%KW
可以得到 N ( k , j ) = input ( i c , i h , i w ) \color{#60A917}N(k,j)=\text{input}(ic,ih,iw) N(k,j)=input(ic,ih,iw)
那有了上述关系之后,我们就可以利用这个关系修改一下我们的程序,如下所示:
void ImplicitGEMMConvOnHost(
float* filter, float* input, float* output,
int IC, int IH, int IW,
int KH, int KW,
int OC, int OH, int OW)
{
for (int i = 0; i < OC; i++){
for (int j = 0; j < OH * OW; j++){
int oh = j / OW;
int ow = j % OW;
int oc = i;
int output_index = oc * OH * OW + oh * OW + ow;
float sum = 0;
for (int k = 0; k < IC * KH * KW; k++){
int ic = k / (KH * KW);
int kh = (k % (KH * KW)) / KW;
int kw = (k % (KH * KW)) % KW;
int ih = oh + kh;
int iw = ow + kw;
int filter_index = oc * IC * KH * KW + \
ic * KH * KW + kh * KW + kw;
int input_index = ic * IH * IW + ih * IW + iw;
sum += filter[filter_index] + input[input_index];
}
output[output_index] = sum;
}
}
}
可以看到 ImplicitGEMMConvOnHost 函数的输入参数和 ExplicitGEMMConvOnHost 一样,但是少了 im2col 的步骤,我们直接通过这些索引来访问 input、filter、output 的数据,然后进行计算即可。整个过程也省去了额外空间的分配,这个就是隐式 GEMM Conv 的计算方式。
那么我们来对比下 Explicit GEMM Conv 和 Implicit GEMM Conv 的代码实现,如下图所示:
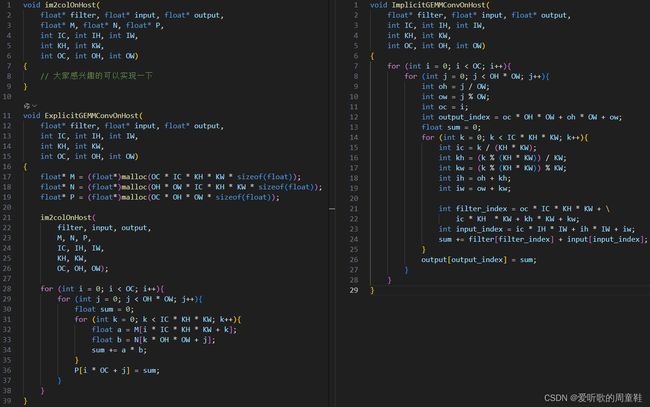
左边是 Explicit 的实现,右边是 Implicit 的实现,可以看到 Explicit 多了 im2col 这个部分,那这个其实开销还是比较大的,而 Implicit 看着就比较简单。
4. Implicit GEMM Conv优化
在 Implicit GEMM Conv 的代码中我们可以看到它其实还是串行执行的,也就是三个 for 循环,上面的代码仅仅是 CPU 上的一个模拟 ImplicitGemmConv 的实现,要在 GPU 上跑的话,需要把这个程序加速,比如说:
- 使用 tilling
- 结合硬件合理调整 grid size 和 block size
- warp GEMM 加速
- 使用 shared memory
- 更改 shared memory 上的 data layout 来避免 bank conflict
- 更改 global memory 上的 data layout 来实现合并访存
- 预处理偏移量来删除除法和求余
- 通过 wmma 调用 Tensor Core
- 使用 CUTLASS
- CUTLASS 是 NVIDIA 推出的针对矩阵乘法的模板库,里面有很多针对矩阵乘法优化的 C++ 模板库,可以自定义高效算子
- …
值得注意的是使用 CUTLASS 优化要展开讲的话会有太多的内容,目前我们只要知道 Implicit GEMM Conv 的基本思路就好,大家感兴趣的可以读一下 CUDA 的官方文档
5. spconv和Implicit GEMM Conv
OK,我们讲了这么多的 Implicit GEMM Conv,我们思考下 Implicit GEMM Conv 它跟 spconv 又有什么关联性呢?我们回顾一下稀疏点云 spconv 的处理的话,我们可以发现 spconv 的方案与 Implicit GEMM Conv 有一定的类似度,两者都是通过索引来寻找需要计算的数据,那么是否可以将 spconv 中的 rulebook 里各类 atomic operation 的数据通过类似于 LUT(Look up table)的方式保存起来后传递给 Implicit GEMM Conv 来做计算呢?这肯定是可以的
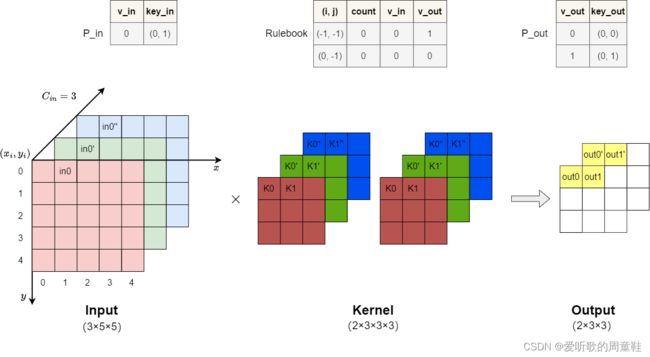
traveller59 的 spconv 也有使用 Implicit GEMM Conv 的方法,感兴趣的可以看下:https://github.com/traveller59/spconv/blob/master/example/libspconv/main.cu
CUTLASS 也提供了有关 Implicit GEMM Conv 的模版函数,方便我们自定义很多优化方案,自由度比较高。大家感兴趣的可以看下 https://github.com/NVIDIA/cutlass/blob/main/media/docs/implicit_gemm_convolution.md,里面有很多优化思路可以参考。上手难度比较高,需要有一定的优化背景。如果这篇文档里面的优化方式大家能看懂,说明前面几章内容学得很扎实,如果看不懂大家可以在搜集下相关资料来理解
一般来说 CUTLASS 的编程会比 CUBLAS 要难,因为它自由度较高,我们需要非常理解 CUDA 编程中的一些优化策略才能把 CUTLASS 写好,要不然写起来会比较困难
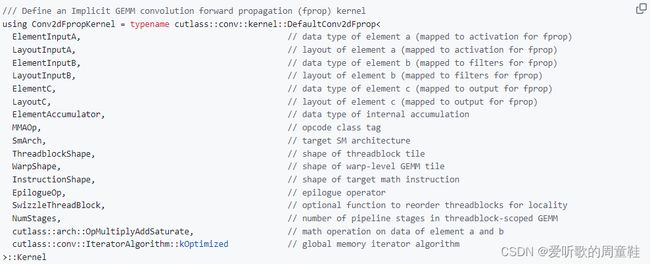
OK,关于 Implicit GEMM Conv 和 spconv 的关系我们就讲到这里,下一小节我们将会为大家讲解 BEVFusion 另一个核心的地方—BEVPool
总结
这节课程我们学习了 Implicit GEMM Conv,相比于 Explicit GEMM Conv 而言,隐式的 GEMM Conv 去除了 im2col 的操作利用索引的方式去计算,之后我们简单了解了 Implicit GEMM Conv 在 GPU 上的一些优化方式以及它与 spconv 之间的关系,我们可以将 spconv 中的 rulebook 里各类 atomic operation 的数据通过类似于 LUT(Look up table)的方式保存起来后传递给 Implicit GEMM Conv 来做计算从而实现加速
OK,以上就是第 5 小节有关 Implicit GEMM conv 优化方案的全部内容了,下节我们将去学习 BEVPool 的优化方案,敬请期待
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
- 代码和安装包下载链接【提取码:cuda】
参考
- 复杂onnx解决方案(以sparseconv为例)
- https://github.com/traveller59/spconv/blob/master/example/libspconv/main.cu
- https://github.com/NVIDIA/cutlass/blob/main/media/docs/implicit_gemm_convolution.md