【WinForm】关于屏幕截图识别文字工具的桌面程序实现方案
在使用电脑录入资料的工作中,有时需要将扫描图片里面的信息录入到电脑上,那有没有想过,用文字识别功能快速录入,这样连手动打字省了不少,网上可能有这样的程序(会要求登录),有能力的同学可以看着做,自己动手来实现。
文章目录
- 功能描述
- 截图工具
- 文字识别插件
-
- Tesseract
- 识别库文件
- 实现识别功能
-
- 识别结果显示
- 关于项目
功能描述
- 通过截图工具生成一个区域的图片(可把打开的图片文件截图),
- 使用识别功能,识别出文字输出显示,
- 识别显示结果可能不太准确(有错字少字),要自己修改一下,
- 选择复制文字,直接粘贴文字到输入框即可。
现在把以上基础的功能实现出来,如果想实现其它的功能,可以在此基础上改进吧
打开Visual Studio开发工具,新建一个WinForm项目,桌面程序,编写用C#语言
截图工具
关于桌面截图工具的实现步骤,可以看以下这篇文章来做
【截屏工具窗口简单实现原理,附详细代码】
截图工具的运行效果如下图
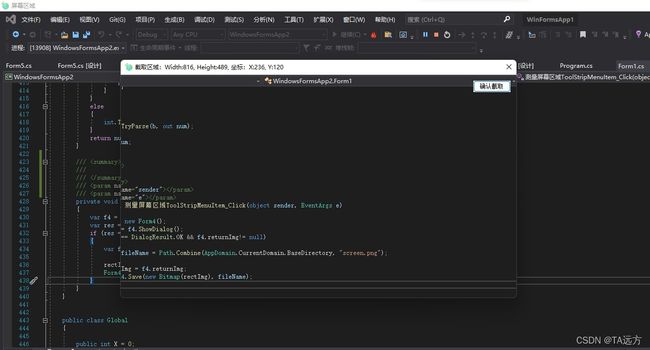
实现了截图功能后,在这基础上继续编写,添加识别文字按钮
文字识别插件
关于文字识别,有很多现成的OCR插件,可以在NuGet包管理中查到,
笔者测试了一些插件,没有可参考的文档就不拿来用了,
而有一些插件感觉还可以,在网上能找到相关学习文档,列出如下:
- Spire.OCR - 对中文识别率好;
- Tesseract - 对中文识别率一般,依赖训练的库;
- PaddleOCRSharp - 对中文识别率较好;
Tesseract
这里的工具项目是用Tesseract插件,
其它的插件根据自己的情况选择来用(只能在64位机系统环境上运行),
在解决方案资源管理面板(文件夹)下,新建一个库项目,命名为TesseractSharp,
选择这个项目名,鼠标右键选择管理NuGet程序包打开,如下图,去找一个叫Tesseract插件安装好

只是安装这个
Tesseract插件显然还不够,缺少依赖文件;
识别库文件
需要去国内开源的GitCode下载一些识别语言所需的库文件,如下:
- chi_sim.traineddata - 简体中文语言包;
- chi_sim_vert.traineddata - 简体体中文语言包,垂直向下书写方向;
- chi_tra.traineddata - 繁体中文语言包;
- chi_tra_vert.traineddata - 繁体中文语言包,垂直向下书写方向;
- osd.traineddata - 文字方向检测的;
- eng.traineddata - 英文语言包
上面语言包任选一个即可,如果开启方向检测就要用到
osd.traineddata
实现识别功能
安装好插件后,把下载好的库文件放到项目目录下的文件夹tessdata里,
这里实现调用图文识别功能,
在类库项目里面新建一个TesseractSharpTool类文件,代码如下
public class TesseractSharpTool {
private TesseractEngine engine;
public TesseractSharpTool(){
//识别库文件夹的路径
var path = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "tessdata");
// 识别引擎
var eMode = EngineMode.TesseractAndLstm;
// 中文语言包
var langFilename = "chi_sim";
// 识别引擎对象
engine = new TesseractEngine(path, langFilename, eMode);
}
//...
}
初始化识别引擎对象engine,
接下来,在类里面继续写,实现调用它的方法,代码如下
/// 返回格式化的识别结果
public string DetectText(Bitmap ocrImage, List<TextBlock> blocks)
{
using(var pix = PixConverter.ToPix(ocrImage))
{
using (var page = engine.Process(pix))
{
// 这里识别返回结果
var result = page.GetText();
if (!string.IsNullOrEmpty(result))
{
// 如果要标注识别区域的话,就继续写,
// 把获取到的识别区域添加到标注块blocks集合即可(是对数组的引用,无需返回)
// ...
}
return result;
}
}
}
接下来,在之前写好截图工具项目中去写,会引用上面的库项目,
识别结果显示
当截图完成,点击识别文字按钮的事件里,去打开一个对话框窗口,
需要新建一个对话框窗口窗体对象,新建时传入截图的一个Image对象,
设计的对话窗口如下图

传入截图的图片在左侧区域显示(标注块在图片上层);
识别的结果会在右侧区域显示,是一个多行文本框,可以修改;
窗口是可以拖动调整右侧区域大小的;
在窗口加载事件方法里,调用识别方法,代码如下
var blocks = new List<TextBlock>();
var result = string.Empty;
using (var ocr = new TesseractSharpTool())
{
//识别图片
result = ocr.DetectText(panel1.BackgroundImage as Bitmap, blocks);
}
//显示识别结果
richTextBox1.Text = result;
foreach (var block in blocks){
//...将标注块放到图片上层
}
记得要用线程处理识别结果,不然看上去会卡顿的
关于项目
写到这里,不用多讲,自己动手试试,整个项目就能做出来了,
项目运行的截图识别对话框的效果图如下
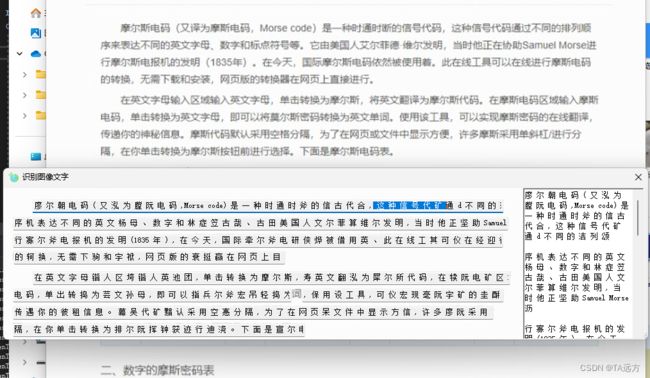
可见
Tesseract插件的识别率不是很准确,
显示的一些标注是可以选择复制的,在右侧直接修改复制识别结果;
如果是只识别一些限定内容,可以试试如下代码
//识别单个字符的模式设置,单个字母或者汉字
engine.DefaultPageSegMode = PageSegMode.SingleChar;
//设置白名单的方法
engine.SetVariable("tessedit_char_whitelist", "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ-");
或者,用一个网上找来的jTessBoxEditorFX工具制作自己的字库给它调用,以提高识别率,
在此项目上,可尝试再写一个库项目,用别的识别插件调用试试,运行效果图如下

用别的插件
PaddleOCRSharp,可见这个识别率还可以,只能运行在64位机器
想看项目源码请点此这里,或者点此去搜索截图识别,本博客站内请放心下载!
可能手机上看不到源码,请用电脑浏览器查看
