UniCOQE: Unified Comparative Opinion Quintuple Extraction as A Set
作者:Zinong Yang, Feng Xu, Jianfei Yu, and Rui Xia
单位:School of computer science and engineering
Nanjing University of Science and Technolog, Nanjing, China
School of Accountancy
Nanjing University of Finance and Economics, China
1{znyang, jfyu, rxia}@njust.edu.cn, [email protected]
摘要
比较意见五元组提取(COQE)旨在识别产品评论中的比较意见句子,提取句子中的比较意见元素,然后将其纳入五元组。现有的方法将COQE任务分解为多个主子任务,然后以管道的方式解决它们。然而,这些方法忽略了子任务之间的内在联系和阶段之间的错误传播。为了一次性解决COQE任务,本文提出了一种统一的生成模型UniCOQE。我们设计了一个生成模板,其中所有比较元组被连接作为目标输出序列。然而,多个元组本质上不是有序序列,而是无序集合。预先定义的顺序会迫使生成模型学习错误的顺序偏差,从而影响模型的训练。为了减轻这种偏见,我们引入了一种新的“预测-分配”训练范式,将黄金元组建模为一个集合。具体来说,我们利用集合匹配策略来找到元组的最优顺序。多个基准测试的实验结果表明,我们的统一生成模型明显优于SOTA方法,烧蚀实验证明了集合匹配策略的有效性。
简单来说,就是现有的方法将五元组提取任务分解为多个子任务,以pipeline也就是首尾相接的方式去解决,忽视了子任务之间存在的练习,造成前一阶段的错误传播到后一阶段。也是一种信息抽取任务。
本文提出一种统一的生成模型,使用一个生成模版去链接所有被比较元素,作为目标输出序列。
导言
比较意见挖掘是意见挖掘的一个重要分支,其目的是挖掘产品评论中的比较信息。Jindal和Liu (2006b)首先提出了比较意见挖掘的概念,并引入了两个主要子任务:比较句子识别(CSI)和比较元素提取(CEE)。前者的目的是识别给定句子是否为比较句,后者的目的是提取给定比较句中的所有比较元素。Panchenko et al(2019)进一步提出比较偏好分类(CPC)任务,该任务旨在预测提供的比较句的比较偏好(更好,更差或无)。

图1:比较意见五元组抽取(COQE)任务的一个示例。给定一个产品评论句子,COQE的目的是识别它是否是比较句子,提取所有比较元素(如果存在),并将它们合并到五元组中。
提出比较偏好分类(CPC)任务,该任务旨在预测提供的比较句的比较偏好(更好,更差或无)。
为了整合比较意见挖掘的各个子任务,Liu et al(2021)首先提出了比较意见五元抽取(COQE)任务(如图1所示)。COQE旨在识别产品评论中的比较意见句子,并提取句子中的五个比较意见元素,即比较主语(sub)、比较宾语(obj)、比较方面(ca)、比较意见(co)和比较偏好(cp)。然后将它们合并到一个五元组(sub, obj, ca, co, cp)中。刘等人(2021)采用多阶段模型,将COQE任务分解为主要子任务(前文提到的CSI、CEE和CPC),然后以流水线方式逐个求解。然而,管道模型忽略了比较意见挖掘的多个子任务之间的内部联系,并且每个阶段之间的误差传播严重影响了模型的性能。
为此,我们首次在COQE任务上使用了一种称为UniCOQE的生成提取模型。我们利用T5 (rafael et al, 2020)作为主干,并提出了一个生成模板来适应COQE任务,识别比较语句和一劳永逸地提取所有五元组。
在生成范式中,我们将所有黄金比较元组连接在一起作为模型的目标输出序列。然而,多个元组本质上不是有序序列,而是无序集合。如果施加预定义的顺序,则会引入顺序偏差,迫使生成模型学习该偏差,从而阻碍模型的训练。以图1为例,有t1、t2、t3、t4四个目标元组。理论上,A4 = 24种目标元组的排列都是正确的。在训练过程中,模型会感到“困惑”:为什么t1;t2;t3;t4是正确的,而t4;t3;t2;t1是不可接受的?
批注:识别出文章中的比较句子,提取所有比较元素。存在的问题是,多个元组本质上不是有序的,而是无序的。在生成序列中强制规定顺序,太过死板,会造成模型只认为一种答案是正确的。
为了缓解这种顺序偏差问题,我们在生成模型中引入了“预测-分配”训练范式。在训练阶段,我们首先让模型自回归预测给定句子中的比较元组。随后,我们将金元组建模为一个集合,并使用匈牙利算法(Kuhn, 1955)将金元组集合与预测序列进行匹配,以找到金元组的最优顺序。
最后,我们在三个COQE基准上验证了我们的方法的性能。实验结果表明,我们的模型明显优于SOTA方法,并通过烧蚀实验验证了集合匹配策略的有效性。
本文的贡献可以概括为以下几点:
- 为了解决以往多阶段模型的误差传播问题,提出了一种生成式比较意见五元抽取模型。
- 我们引入了基于集合匹配策略的“预测-分配”训练范式,以减轻生成模型在训练过程中的顺序偏差。
- 我们的模型明显优于以前的SOTA模型,烧蚀实验验证了集合匹配策略的有效性。
2. 相关工作
比较意见挖掘任务作为意见挖掘的一个重要子任务,最早由Jindal和Liu (2006a,b)提出,旨在识别产品评论中的对比句,提取所有对比意见元素(实体、特征、对比关键词)。具体而言,它使用类顺序规则(Hu and Liu, 2006)来识别比较句,并使用标记顺序规则来提取比较元素。
随后的一些研究集中在比较句子识别(CSI)任务上。Huang et al .(2008)使用多种特征(如关键词和顺序模式)来识别比较句。Park和Blake(2012)利用语义和语法特征来探索识别科学文本中比较句的任务。Liu et al .(2013)基于关键词、句子模板和依赖分析对中文文档的比较句进行识别。
在比较元素提取(CEE)任务上,Hou and Li(2008)使用语义角色标注(semantic role labeling, SRL)分析比较句子的结构,并训练条件随机场(conditional random field, CRF)提取比较特征。一些研究(Song et al ., 2009;Huang et al ., 2010;Wang et al ., 2015a)也使用了CRF作为提取模型。
语义角色标注(Semantic Role Labeling,简称SRL)是一种自然语言处理技术,用于分析句子中谓词(如动词、形容词等)与句子中其他成分(如名词、短语等)之间的语义关系,并将这些关系标注出来。这种标注可以帮助计算机更好地理解句子的语义结构,从而提高自然语言处理的性能。
在语义角色标注中,谓词被视为句子的中心,而其他成分则被视为与谓词有关的角色。这些角色可以是主语、宾语、定语、状语等。通过对句子进行语义角色标注,可以得到一个包含谓词和各个角色之间关系的语义结构图,这个图可以被用于各种自然语言处理任务中,如信息抽取、问答系统、文本摘要等。
条件随机场(Conditional Random Field,简称CRF)是一种常用的序列标注模型,用于处理序列数据(如文本、语音等)中的标注问题。在自然语言处理中,CRF常被用于各种序列标注任务,如分词、词性标注、命名实体识别等。
在比较元素提取(Comparative Element Extraction,简称CEE)任务中,CRF被用作提取模型,用于从比较句子中提取比较特征。具体来说,通过对比较句子进行语义角色标注,可以得到句子中各个成分之间的语义关系。然后,利用CRF模型对这些语义关系进行建模,从而提取出比较特征。这种方法可以有效地处理各种复杂的比较句子,提高比较元素提取的准确性和效率。
考虑到早期的比较意见挖掘任务不包含作者的比较偏好,Ganapathibhotla和Liu(2008)首次提出了比较偏好分类(CPC)任务,目的是在给定比较句及其比较要素的情况下,预测哪个实体更受欢迎。它利用基于关键字的方法来确定比较偏好。Panchenko等(2019)使用预训练编码器对句子进行编码,并基于XGBoost对句子的比较偏好进行分类(Chen and Guestrin, 2016)。Ma等人(2020)采用图注意网络对比较句的句法解析信息进行建模,以更好地预测比较偏好。然而,CPC任务的前提是要比较的两个实体是预先标注的,这在现实场景中应用起来很有挑战性。
Liu et al .(2021)首次引入了比较意见五元抽取(COQE)任务。
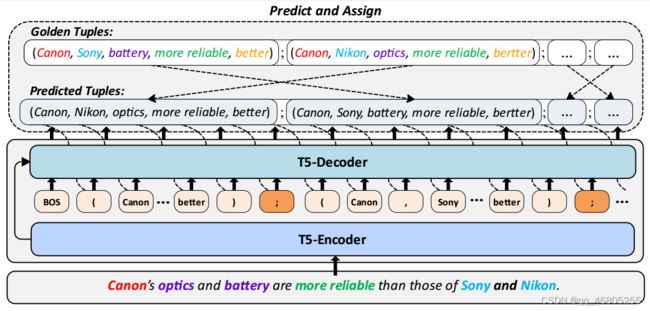
图2:UniCOQE框架的概述。我们利用T5作为生成模型的主干,并采用“预测-分配”训练范式来减轻vallina生成模型的顺序偏差。在训练过程中,我们暂时关闭模型的梯度,让模型自回归预测元组。然后,我们将金元组建模为一个集合,并使用匈牙利算法将金元组集合与预测序列进行匹配,以分配金元组的最优顺序。
其目的是提取五元组(比较主体,比较客体,比较方面,比较意见,比较偏好)。具体来说,它使用了一个基于BERT的多阶段模型(Devlin et al ., 2019),在每个阶段执行CSI、CEE和CPC任务。虽然该方法以管道的方式序列化比较意见挖掘的多个子任务,但错误在多个阶段的传播会影响模型的性能。
除了CSI、CEE、CPC、COQE等子任务外,一些研究方向也与比较意见挖掘密切相关。比较问答系统(Alhamzeh et al, 2021;Chekalina等人,2021)允许机器自动回答“相对于Z, X比Y好吗?”的比较问题。
意见元组提取(Jian et al ., 2016;传统的基于方面的情感分析中的Peng et al ., 2020)和四重提取(Cai et al ., 2021)旨在提取文本中的细粒度意见信息。
一些研究还探讨了生成模型的集匹配策略的使用。在关键词提取任务中,Ye等人(2021)将所有关键短语连接为Transformer的目标输出(Vaswani等人,2017),而无需预定义顺序。在事件参数提取任务中,Ma等人(2022)引入了BART的最佳跨度分配方案(Lewis等人,2020)。这些研究证明了集合匹配策略在生成模型中的有效性,突出了它们在提高生成lm性能方面的潜力。
3 Methodology
本节详细介绍了UniCOQE框架(如2所示)。在该框架中,我们将COQE任务建模为自然语言生成任务。我们使用生成式预训练语言模型T5 (rafael et al, 2020)作为主干模型,采用生成模板直接识别比较句子,并端到端输出比较五元组。为了进一步缓解生成模型的顺序偏差问题,我们引入了“预测-分配”训练范式。
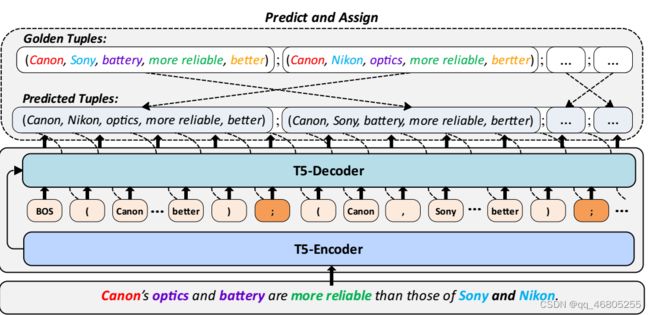 图2:UniCOQE框架的概述。我们利用T5作为生成模型的主干,并采用“预测-分配”训练范式来减轻vallina生成模型的顺序偏差。在训练过程中,我们暂时关闭模型的梯度,让模型自回归预测元组。然后,我们将金元组建模为一个集合,并使用匈牙利算法将金元组集合与预测序列进行匹配,以分配金元组的最优顺序。
图2:UniCOQE框架的概述。我们利用T5作为生成模型的主干,并采用“预测-分配”训练范式来减轻vallina生成模型的顺序偏差。在训练过程中,我们暂时关闭模型的梯度,让模型自回归预测元组。然后,我们将金元组建模为一个集合,并使用匈牙利算法将金元组集合与预测序列进行匹配,以分配金元组的最优顺序。
3.1 任务表述
首先将COQE任务表述如下,给定一个产品评审句子![]() COQE包含n个标记,旨在识别它是否是比较句,如果是,则提取其中的所有比较五元组:
COQE包含n个标记,旨在识别它是否是比较句,如果是,则提取其中的所有比较五元组:
其中k是从比较句X中提取的比较五元组的个数。
Tup = (sub, obj, ca, co, cp)是一个抽取的五元组,其中sub是主体实体,obj是客体实体,ca是被比较的方面,co是作者反映比较偏好的意见。cp∈{WORSE, EQUAL, BETTER, DIFFERENT}是作者的比较偏好。
3.2 生成范式的COQE
在本节中,我们将介绍COQE任务的生成范例。我们设计了一个T5生成模板,用于端到端抽取五元组。示例如下:
输入:佳能的光学和电池比索尼和尼康的更可靠。
目标:(佳能,索尼,光学,更可靠,更好);(佳能,索尼,电池,更可靠,更好);(佳能,尼康,光学,更可靠,更好);(佳能,尼康,电池,更可靠,更
输入:佳能的光学和电池太棒了。
目标:(未知,未知,未知,未知,未知)
在生成范式中,k个黄金五元组与“;作为模型的目标序列。如果比较元素不存在,则用单词“unknown”填充。如果目标序列为“(unknown, unknown, unknown, unknown, unknown, unknown)”,则将相应的输入句子X视为非比较句。我们称这种方法为Vallina生成范式
然而,Vallina生成范式存在一个问题:k个目标元组本质上是一个无序集合,而不是有序序列。生成模型的训练基本上是基于交叉熵损失,严重依赖于目标文本序列的顺序。在许多情况下,人为地预定义顺序可能会在训练期间引入错误的顺序偏差,从而破坏模型的性能。
待预测的元组实际上是无序的集合,例如预测元组列表为[(1,a), (2,b),(3,c)],真实标签列表为[(2,b), (1,a), (3,c)], 这时预测的正确率为100%。
人为定义真实标签列表为[(2,b), (1,a), (3,c)]顺序,会使得模型感到困扰,生成能力受限于去生成[(2,b), (1,a), (3,c)],实际上生成[(2,b), (1,a), (3,c)]中任意一种元组排列都是可以的。
3.3 Improving Generative COQE with Predict-and-Assign Paradigm
为了解决顺序偏差问题,我们引入了“预测-分配”训练范式。该范式包括两个步骤:预测步骤和分配步骤。
3.3.1 预测阶段
对于输入句子![]() ,在训练阶段,我们暂时关闭模型的梯度反向传播,将X发送到t5编码器中,得到句子的潜在表示:
,在训练阶段,我们暂时关闭模型的梯度反向传播,将X发送到t5编码器中,得到句子的潜在表示:
![]()
然后,我们使用t5解码器自回归预测所有比较五元组。在解码器的第c个时刻,henc和之前的输出令牌:t1:c−1被用作解码器的输入:
![]()
令牌tc的条件概率定义如下:
![]()

3.2.2 分配阶段
给定两个元组:p和g,我们定义p和g之间的相似度得分如下:
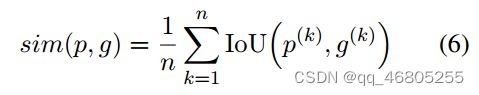
其中n是元组中元素的个数。在我们的例子中,n = 5,因为我们有5个元素(即。(sub, obj, ca, co,和cp)在比较五元组中。这里的IoU指的是两个令牌序列的“交于并”,k指的是元素的索引(例如,对于ca, k = 3)。因此,IoU(p (k), g(k))计算两个元组中第k个元素的IoU分数。我们最终将所有五个元素的平均IoU得分作为两个元组的相似性得分。例如,在图3中,我们有元组p1 =(佳能,尼康,传感器,不太稳定,更糟),g2 =(佳能,索尼,传感器,不太稳定,更糟),元素方面的IoU分数分别为1,0,1,1,1和1。所以p1和g2的相似度是0.8。
然后定义p和q之间的分配代价:
![]()
对于真元组设置Qgold = {tupgold 1,…, tupgold K},我们的目标是找到Qgold的一个排列π φ,使π φ (Qgold)在预测阶段(第3.3.1节)是与模型预测的元组最相似的序列。这本质上是一个赋值(又名二进制匹配)问题。
形式上,为了找到基真元组Qgold的最优阶,我们搜索一个使总分配代价最小的排列π;

K是Qgold中元组的个数。Π(K)是Qgold中K个元组的排列空间。
我的理解,模型预训练时已经具备了充分的通用领域知识。关闭梯度更新,相当于冻结模型参数,这时先让模型生成一些五元组试试看。
然后利用匈牙利算法,去改变真实标签的元组排列,让重排后的真实标签的元组列表,与冻结模型的预测结果,取得最高的IoU相似度匹配,这时认为真实标签是最优的。
匈牙利算法可以理解为,3位男士,3位女士,寻找他们之间以某种度量最优的一对一搭配。
π * (Qpred)是式(5)中元组的预测序列。这种寻找最优分配的过程可以用匈牙利算法(Kuhn, 1955)有效地解决。Cmatch(π∗,π})是排列π∗与排列π}之间的总成对匹配代价。分配成本可以定义如下
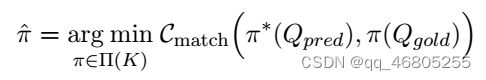
π * (Qpred)是式(5)中元组的预测序列。这种寻找最优分配的过程可以用匈牙利算法(Kuhn, 1955)有效地解决。Cmatch(π∗,π})是排列π∗与排列π}之间的总成对匹配代价。分配成本可以定义为:

where ![]() is the minimum number of tuples between
is the minimum number of tuples between ![]()

在分配黄金元组的新阶数后,我们将标签元组的新顺序作为模型的训练目标,并重新打开梯度反向传播重新开始训练。
4 实验
4.1 数据集
我们在Liu et al .(2021)发布的三个COQE数据集上进行实验:Camera-COQE、CarCOQE和Ele-COQE:
- camera - coqe包含相机领域的英文产品评论。本数据集基于Kessler和Kuhn(2014),完成了比较意见(co)和比较偏好(cp)的注释。
- Car-COQE包含汽车领域的中文产品评论。数据集以Car数据集为基础,补充了比较意见和比较偏好。
- Ele-COQE同样来源于COAE2012/2013中的电子产品评论数据集(Tan et al, 2013),该数据集包含电子产品的中文比较产品评论。
三个数据集的统计结果如表1所示。每个数据集都包含非比较句和比较句。#Comparative表示比较级句的个数,#Non-Comparative表示非比较级句的个数。multicomparison是包含多个比较的比较句的个数。
| Car-COQE | Ele-COQE | Camera-COQE | |
| #Subject | |||
| #Object | |||
| #Aspect | |||
| #Opinion | |||
| #Preference | |||
| #Comparative | |||
| #Non-Comparative | |||
| #Multi-Comparative | |||
| #Comparisons Per Sent |
4.2 Experimental Setup
我们采用T5作为骨干模型。我们对英语数据集使用T5,对中文数据集使用多语言T5 (mT5) (Xue et al, 2021)。
我们没有选择中文T5模型,因为Car-COQE和Ele-COQE中有多个非中文字符(即产品名称和版本)。我们使用Huggingface1库提供的t5-base和mt5-base进行实验。对于T5和mT5,我们分别将批大小设置为24和10。两个模型的学习率都设为3e-4。我们训练T5 60轮次,mt5 30轮次。
4.3 Evaluation Metrics
根据Liu et al(2021)的设置,对于比较句子识别(CSI)任务,我们报告了准确性度量。对于COQE任务,我们考虑三种匹配策略:精确匹配、比例匹配和二进制匹配。这三个指标在模型预测的元组上不同程度地度量F1分数。
对于三种评价指标,我们分别定义#correcte,#correctp,#correctb 如下

其中gk是黄金比较五元组的第k个元素,pk是预测比较五元组的第k个元素。Len(·)表示比较元素的长度
- #correcte:表示预测结果中与真实结果完全相同的元素数量。如果预测结果和真实结果之间存在差异(即某些元素在真实结果中存在,但在预测结果中不存在,或者存在但位置不同),则计数为0。
- #correctp:表示预测结果中与真实结果完全匹配的元素所占的比例。如果预测结果和真实结果之间存在差异,则计算差异的元素数量占真实结果元素数量的比例。
- #correctb:表示预测结果中与真实结果完全匹配的元素所占的比例,但仅在真实结果和预测结果都不为空时计算。如果真实结果或预测结果为空,则计数为0。
这些指标可用于评估模型的性能,通常用于文本生成,图像识别,语音识别等领域。
4.5 主要结果
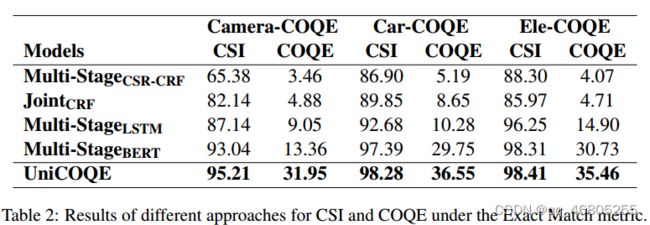
在表2中,我们报告了所有五种方法在CSI和COQE的两个任务上的性能。
三个数据集:Camera-COQE、Car-COQE和Ele-COQE。对于CSI,我们报告精确度度量。
所有的指标都是在精确匹配的情况下。
实验结果表明,在CSI任务和COQE任务上,UniCOQE模型在三种数据集上都取得了最好的性能。这两种基于crf的方法通常在这两个任务上的性能都是最低的。MultiStageLSTM实现了相对更好的性能。
在CSI任务上,Multi-StageBERT已经在三个数据集上取得了相当满意的准确率:93.04、97.39和98.31。然而,值得注意的是,我们的UniCOQE模型仍然比Multi-StageBERT高出2.17%、0.89%和0.10%。
在COQE任务中,使用UniCOQE模型在Camera-COQE、Car-COQE和EleCOQE数据集上分别实现了18.59%、6.80%和4.73%的改进。值得注意的是,我们的UniCOQE模型相对于其他模型的优势在英文数据集上比在中文数据集上更为明显。一种可能的解释是,mT5是T5的多语言版本,涉及多种语言的预训练,并且具有更广泛的词汇表,这将削弱模型在单语言数据集上的性能。
4.6 集合匹配策略的影响
在表3中,我们展示了集合匹配策略对生成模型的影响。实验结果表明,与Vallina生成模型相比,集合匹配策略提高了模型在CameraCOQE、Car-COQE和Ele-COQE数据集上的性能。结果表明,集合匹配策略确实找到了更好的元组顺序,有助于模型更好地学习数据分布。
4.7 多元组场景结果
为了衡量模型在多数据上的有效性,我们只使用测试集中的多元数据进行评估。我们在表4中演示了多个场景的结果。实验结果表明,集合匹配策略显著提高了模型在多元数据下的性能。以精确匹配度量为例,对比Valiina生成
范例中,与Camera-COQE、Car-COQE和Ele-COQE相比,UniCOQE分别获得了3.87、1.74和1.70%的改进。
4.8多元组的交换UniCOQE在训练过程中,多元组的交换次数如图4所示。
在前十个时代,元组交换的数量不断增加。在第11个历元前后,所有三个数据集都达到峰值,并且数量趋于稳定。Camera和Car上的元组交换数量都稳定在140左右。相比之下,电子数据集稳定在60左右,因为电子领域的多元数据较少。
在图5中,我们展示了双匹配策略对T5训练过程的影响。以example1为例,我们可以观察到,在模型训练的一开始(epoch 1),如果我们遵循默认的“黄金”序列顺序,计算得到的交叉熵损失为1.453。
然而,如果我们根据我们的集合匹配策略分配一个新的元组顺序,新的损失将变成0.598。随着训练时间的增加,这种现象更加明显。如例2所示,在epoch 15,默认元组顺序的损失为2.244,而新分配的顺序的损失要小得多:0.032。
在本文中,我们研究了比较意见五元抽取的任务。为了克服以往管道模型的误差传播问题,提出了一种基于生成范式的管道抽取模型。我们进一步引入了一种基于匈牙利算法的集合匹配策略,以减轻生成模型在训练过程中的顺序偏差。实验结果表明,我们的模型明显优于SOTA模型,并通过深入的实验验证了集合匹配策略的有效性。
我们总结了我们工作的局限性如下:•我们只验证了在COQE任务上生成模型的集合匹配策略的有效性。
•我们观察到COQE数据集的规模相当小,导致了模型的过拟合问题。
在未来,我们将从以下几个方面进行进一步的研究:•探索集匹配策略在多个研究方向上的进一步应用,如信息提取、情感分析等。
•利用无监督数据更好地帮助模型挖掘比较意见信息。
•设计数据增强方法,缓解数据稀疏性问题。
我们在(Liu et al ., 2021)之前建立的三个数据集上进行实验,即CameraCOQE、Car-COQE和Ele-COQE。这些数据集不包括个人信息或包含任何可能伤害个人或社区的令人反感的内容。值得注意的是,某些产品评论可能包含匿名客户给出的产品之间的主观比较,这并不一定反映本研究的偏好。
本文得到中国自然科学基金项目(No. 62076133、62006117、72001102)和江苏省青年自然科学基金项目(No. 62006117)的支持。
(BK20200463);BK20200018)。