InverseMatrixVT3D:简单高效实现三维占用预测模型!
论文标题:
InverseMatrixVT3D: An Efficient Projection Matrix-Based Approach for 3D Occupancy Prediction
论文作者:
Zhenxing Ming, Julie Stephany Berrio, Mao Shan, and Stewart Worrall
导读:本文提出了一种简单有效的方法——利用投影矩阵将环视图图像特征转换为三维体积特征,用于三维语义占用预测。该方法利用两个投影矩阵来存储静态的映射关系,并利用矩阵乘法高效地生成全局鸟瞰图特征和局部三维体积特征。在nuScenes数据集上的实验表明:该方法在三维目标检测和分割任务上取得了极具竞争力的结果。©️【深蓝AI】编译
1. 方法引出
感知周围的环境对于自动驾驶汽车来说至关重要。近年来,以环视图为输入的自动驾驶系统因为成本低、稳定性高受到越来越多的关注。这种系统在各种3D感知任务中展现出了良好的性能,包括深度估计、3D物体检测,在线高清(HD)地图构建和语义地图构建。
利用环视图像融合的3D物体检测可以在3D感知中发挥关键作用。然而,它在处理新场景方面面临诸多挑战。其中一个挑战是训练数据集中语义类的有限数量,这让深度学习模型理解新的场景变得困难许多。相比之下,通过直接重构3D场景来描述车辆周围环境是一个更实用的方法。
为了实现这一目标,一些学者提出了直接预测场景的3D占用情况的方法。这些方法将3D空间体素化并为每个体素分配一个概率以确定其是否被占用。3D占用充分表示了车辆周围的环境。这种表示本质上确保了几何一致性,并且可以准确描述被遮挡的区域。此外,它也可以处理训练数据集中不存在的物体类。尽管这些方法很有前景,但它们的内部结构相当复杂,而且需要额外的传感器来提供监督信息。
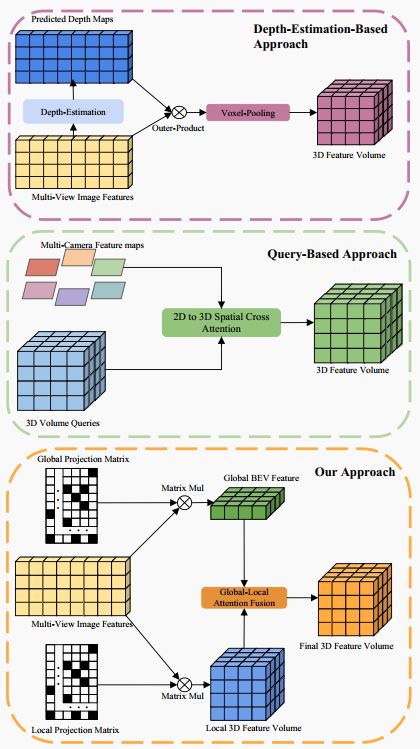
▲图1|三种方法的流程示意图:基于深度估计的方法(上部)、基于查询的方法(中部)和本文的方法(下部)。本文通过采用矩阵乘法方法简化了3D体积特征的生成。©️【深蓝AI】编译
为了简单并高效地表示3D场景的占用情况,本文提出了InverseMatrixVT3D。该方法着重于构建投影矩阵,并通过矩阵乘法在特征图与投影矩阵之间简化局部3D体积特征和全局俯瞰图(BEV)特征的生成。采用了稀疏矩阵处理技术来优化在使用这些稀疏投影矩阵时的GPU内存使用。
此外,本文引入了一个全局-局部注意力融合模块,将全局BEV特征与局部3D体积特征集成,产生最终的3D体积。本文还在每个级别应用了多尺度监督机制,从而进一步增强了性能。通过在nuScenes基准测试中将InverseMatrixVT3D 与最先进算法的比较,证明了本方法的简单性和整体优异性能。
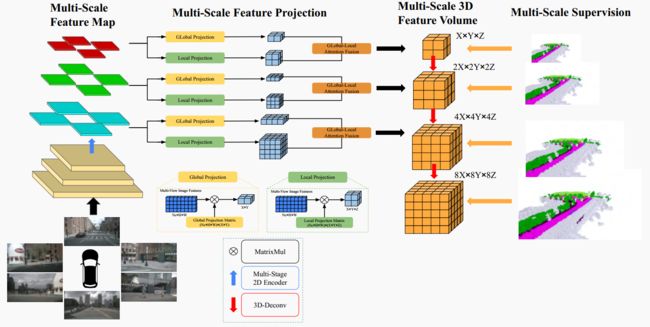 ▲图2|InverseMatrixVT3D的总体架构©️【深蓝AI】编译
▲图2|InverseMatrixVT3D的总体架构©️【深蓝AI】编译
2. 实现细节
图2展示了本文提出方法的整体架构。首先,环视图输入到2D骨干网络中,以在多尺度下提取特征。随后,采用多尺度全局-局部投影模块构建多尺度3D体积特征和BEV平面。每个级别的每个3D体积特征和BEV平面应用全局-局部注意力融合模块以获得最终3D体积。最后,每个级别的3D体积使用3D反卷积进行上采样以进行跳跃连接,并在每个级别也应用了监督信号。
■2.1 多相机图像特征提取器
多相机图像特征提取器的作用是从周围的透视图中捕获空间和语义特征。这些特征是后续3D占用预测任务的基础。
在本方法中,本文首先采用2D骨干网络来提取多尺度特征图。然后,采用特征金字塔网络(FPN)对2D骨干的不同阶段的输出特征进行进一步融合。生成的特征图分辨率分别为输入图像分辨率的1/8、1/16和1/32。分辨率较小的特征图包含丰富的语义信息,这有助于模型预测每个体素网格的语义类别。相反,分辨率较大的特征图提供更丰富的空间细节,并更好地指导模型当前体素网格是否被占用。
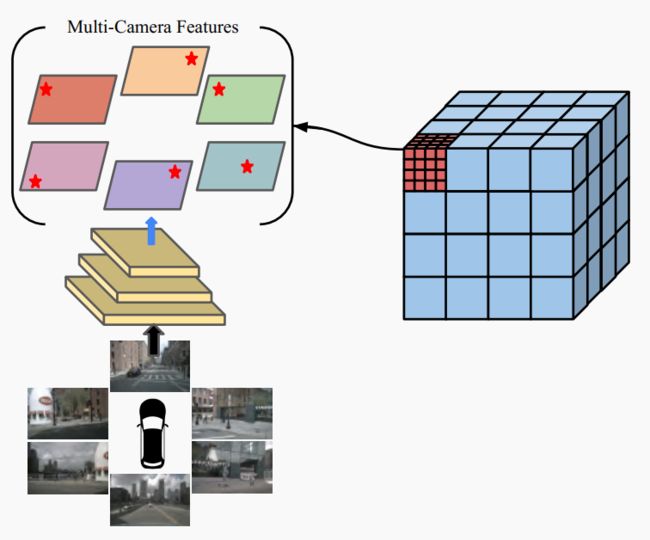
▲图3|预定义3D体积特征采样过程。每个体素网格最初沿垂直和水平方向被等分为3个子空间,每个子空间的中心被用作采样点。这些采样点会被投影到所有多视角特征图上,来聚合相应体素网格的对应特征©️【深蓝AI】编译
■2.2 全局和局部投影矩阵生成
构建全局和局部投影矩阵对于收集局部3D体积特征和全局BEV特征的信息至关重要。
首先,在以自主车为中心的坐标系下建立一组预定义的3D体积空间,用于多视角图像特征图的每个级别。3D体积内,将体素网格均等地划分为沿水平和垂直方向的子空间。每个子空间的中心用作一个采样点。因此,对于3D体积空间的每个级别,接下来,使用外在和内在参数,将来自每个体素网格的采样点投影到对应的多视角图像特征图上。超出特征图边界或生成负深度值的采样点被过滤掉,接着聚合每个采样点命中的特征,生成表示相应体素网格的特征向量。
特征抽样过程为静态映射,可以通过构建投影矩阵来表示,如图4所示。此外,高度信息也可以通过构建投影矩阵进一步压缩,如图5所示。
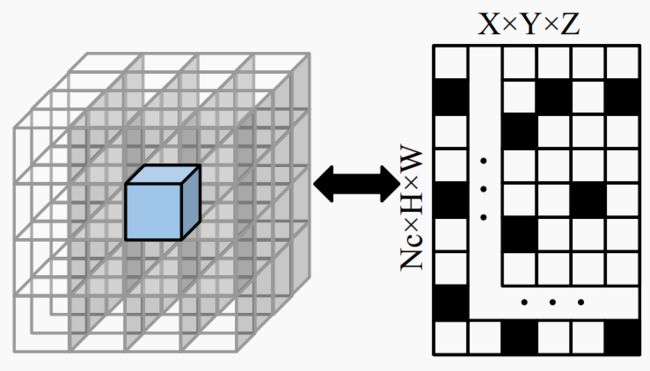 ▲图4|局部投影矩阵表示局部3D体积特征采样过程的静态映射关系。©️【深蓝AI】编译
▲图4|局部投影矩阵表示局部3D体积特征采样过程的静态映射关系。©️【深蓝AI】编译
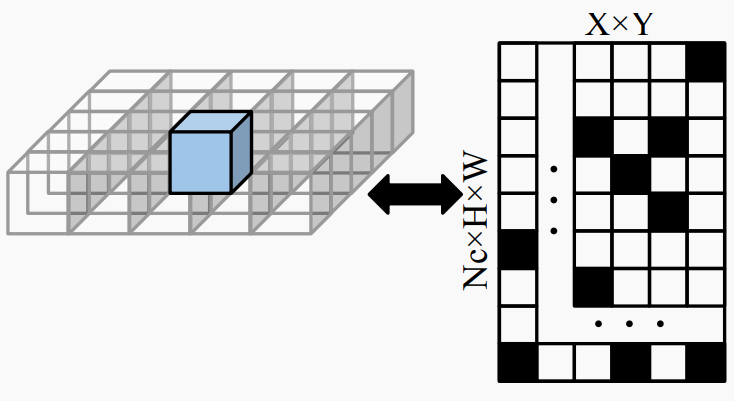 ▲图5|全局投影矩阵表示全局BEV特征采样过程的静态映射关系。©️【深蓝AI】编译
▲图5|全局投影矩阵表示全局BEV特征采样过程的静态映射关系。©️【深蓝AI】编译
在构建全局和局部投影矩阵的过程中,作者观察到这些矩阵具有稀疏性。因此,随着其分辨率的增加,构建这些矩阵所需的GPU内存利用率呈指数增长。为了优化GPU内存利用,本文利用了压缩稀疏行(CSR)技术。这种技术在构建和存储稀疏矩阵时只存储非零值和其相关索引。通过应用这种技术,可以将最高3D体积分辨率的GPU内存使用量从15GB大大减少到200MB。
■2.3 全局-局部注意力融合
为了增强最终3D体积特征同时捕获全局和局部细节的能力,作者引入了全局-局部注意力融合模块。该全局-局部注意力融合模块的详细结构如图6所示。
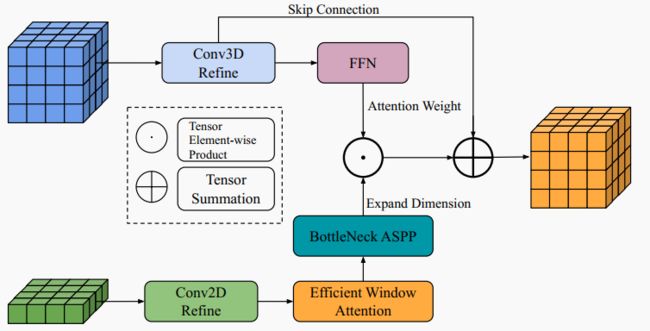
▲图6|全局-局部融合模块。全局BEV特征和局部3D体积特征使用传统卷积层进行精炼。全局BEV特征经过额外的高效窗口注意力模块和瓶颈ASPP模块增强。然后,它与局部3D体积特征合并,生成最终3D体积。©️【深蓝AI】编译
该模块首先应用传统的2D和3D卷积操作来增强全局BEV特征和局部3D体积特征。本文结合了一个高效窗口注意力模块和一个瓶颈ASPP模块,以进一步提取全局BEV特征,使其能够捕获长程全局语义信息。同时,局部3D体积特征通过前馈网络(FFN)处理以生成注意力权重。经过窗口注意力和瓶颈ASPP模块优化的BEV特征经过维度扩展并逐元素与注意力权重相乘。然后将所得特征添加到优化的局部3D体积特征中,以产生最终的3D体积特征。
3. 结果展示
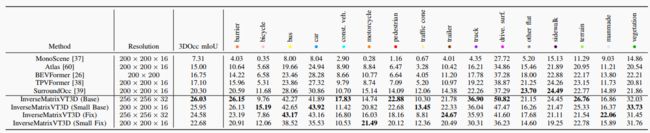 ▲表1|nuScenes验证集上的3D语义占用预测结果。©️【深蓝AI】编译
▲表1|nuScenes验证集上的3D语义占用预测结果。©️【深蓝AI】编译
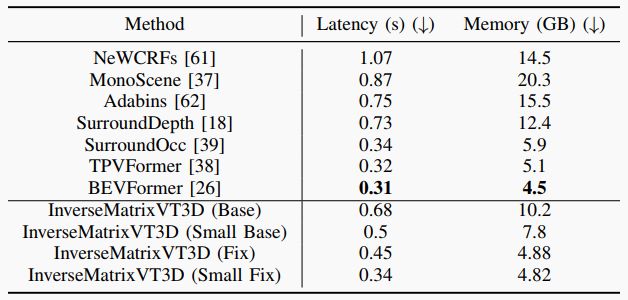 ▲表2|不同方法的模型效率比较。实验在单个RTX 3090上进行,使用六个环视图。对于输入图像分辨率,所有方法都采用1600×900。(↓:越低越好)©️【深蓝AI】编译
▲表2|不同方法的模型效率比较。实验在单个RTX 3090上进行,使用六个环视图。对于输入图像分辨率,所有方法都采用1600×900。(↓:越低越好)©️【深蓝AI】编译
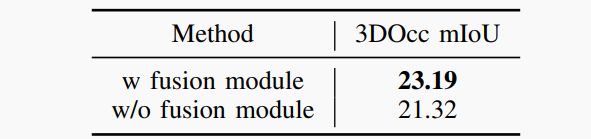 ▲表3|全局-局部注意力融合模块的消融研究©️【深蓝AI】编译
▲表3|全局-局部注意力融合模块的消融研究©️【深蓝AI】编译
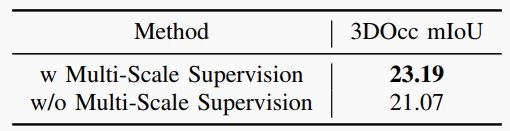 ▲表4|多尺度监督的消融研究©️【深蓝AI】编译
▲表4|多尺度监督的消融研究©️【深蓝AI】编译
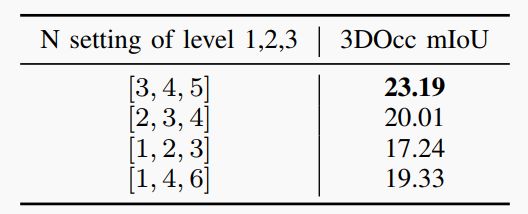 ▲表5|每个级别的划分模式的消融研究©️【深蓝AI】编译
▲表5|每个级别的划分模式的消融研究©️【深蓝AI】编译
4. 结论
在本文中,作者提出了InverseMatrixVT3D,这是一种基于视觉的3D语义占用预测方法。该方法利用预定义的每个尺度3D体积的样本点,构建投影矩阵来表示固定的采样过程。通过多尺度方式在特征图与投影矩阵之间进行矩阵乘法,生成局部3D体积特征和全局BEV特征。并且使用全局-局部融合模块合并这些特征,得到每个级别的最终3D体积。最后,使用3D反卷积层对各级3D体积进行上采样并融合。
与其他最先进算法不同,本方法不需要基于Transformer的查询或深度估计,这使得3D体积生成过程简单又高效。在nuScenes数据集上的实验结果证明了本方法的优越性。
编译|Deep蓝同学
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。