【前端必备技能java之若依框架缓存(redis)模块封装梳理与MyBatis最佳实践】
详解若依框架redis封装与MyBatis的应用
- 什么是Redis和MyBatis
-
- 极速缓存Redis
- Redis的几种特性:
- 数据持久层工具MyBatis
- MyBatis与Orm框架对比有哪些优势和缺点
-
- 优势
- 缺点
- 传统ORM框架的优势
- 传统ORM框架的缺点
- 总结(选择ORM还是MyBatis)
- 如何高效优雅的封装Redis
-
- RedisService:
- RedisTemplate
- MyBatis的最佳实践 ️
-
- 分离SQL和Java代码
- 动态SQL
- 适当使用resultMap
- PageHelper分页大批量数据
- N+1查询问题
什么是Redis和MyBatis
极速缓存Redis
下面是在redis存储数据的截图:
上面左侧是redis仓库的存储目录,这些目录由redis封装模块定定义。这些数据是存储在计算机内存上,所以读取的速度非常快,相比与数据库的读取速度要快几十甚至几百倍,因此redis通常被用作数据库、缓存和消息代理。redis支持多种类型的数据结构,如字符串(strings)、列表(lists)、集合(sets)、有序集合(sorted sets)、散列(hashes)、位图(bitmaps)、超日志(hyperloglogs)和地理空间索引(geospatial indexes)。
虽然redis存储数据在内存上,但是也可以做数据持久化,即把数据存储到硬盘上,下面会介绍几种数据持久化方式。
Redis的几种特性:
- 支持丰富的数据类型:Redis 不仅仅支持简单的key-value存储,还提供了丰富的数据类型来适应各种不同的场景。
- 持久化:尽管Redis是基于内存的,但是它可以将数据持久化到磁盘,这样即使在服务重启后数据也不会丢失。
- 原子操作:Redis支持对其数据类型进行原子操作,保证了操作的原子性,避免了并发访问的问题。
- 发布/订阅模式:Redis 支持发布/订阅模式,可以用于实现消息系统。
- Lua 脚本:Redis 支持使用 Lua 脚本执行复杂的操作,提供了更高级的控制能力和灵活性。
- 事务:Redis通过 MULTI 和 EXEC 命令提供了事务功能。
- 高可用与分布式:通过Redis哨兵(Sentinel)和Redis集群(Cluster)提供了高可用和分布式解决方案。
- 高性能:由于数据存储在内存中,Redis 有着极高的读写效率,读操作可达每秒数十万次,写操作也可达每秒数万次。
数据持久层工具MyBatis
用过Node框架的小伙伴肯定少不了与ORM框架打交道,ORM框架虽然免去了写SQL语句的繁琐但是也要熟悉ORM本身的语法学习成本也较高,MyBatis通常被认为是一个持久层框架,而不是传统意义上的完整ORM(对象关系映射)框架。它更侧重于SQL和对象之间的映射,而不是提供完全的对象数据库抽象。
MyBatis与Orm框架对比有哪些优势和缺点
优势
- SQL 控制:MyBatis允许开发者编写原生SQL语句,这样可以更精确地控制执行的SQL操作,适合需要进行复杂查询和优化的场景。
- 轻量级:MyBatis的学习曲线相对平缓,配置简单,启动速度快,资源消耗较少。
- 灵活性:MyBatis不会像完全的ORM框架那样强制要求对象遵循特定的模式,因此在遗留系统中集成使用可能会更容易。
映射控制:提供了复杂映射的支持,包括嵌套结果和动态SQL语句。
缺点
- 数据模型:由于MyBatis更偏向于SQL映射,它没有提供完整的对象关系映射,开发者需要自己维护对象和数据库表之间的关系。
- 数据库移植性:由于使用原生SQL,当切换不同的数据库时,SQL语言的差异可能导致需要重写或调整SQL语句。
- 一致性:没有自动化的一致性校验功能,所有的校验和转换都需要手工处理。
传统ORM框架的优势
- 对象关系映射:自动处理Java对象和数据库表之间的映射,减少了手工编码的工作。
- 数据库无关性:可以无需修改代码而切换不同的数据库,因为SQL是由框架生成的。
- 缓存机制:通常带有一级和二级缓存,可以提高应用程序的性能。
- 事务管理:支持声明式的事务管理,简化了事务代码。
传统ORM框架的缺点
- 性能问题:自动生成的SQL可能不是最优的,可能需要调整和优化。
- 学习曲线:功能丰富但相应地更复杂,新手可能需要花费更多时间来学习和理解其工作原理。
- 隐蔽的SQL:自动生成的SQL可能导致开发者对正在执行的SQL操作不够清晰,难以进行调试和优化。
- 启动时间:由于框架需要分析映射和创建代理对象,启动时间可能长于轻量级框架。
总结(选择ORM还是MyBatis)
- 如果需要高度优化的SQL或对数据库操作有特殊要求,MyBatis提供的细粒度控制可能更适合。
- 如果应用需要快速开发且业务逻辑不复杂,使用ORM框架可能更高效。
- 对于复杂的数据库交互,诸如多表联合、嵌套查询等,MyBatis能够提供更灵活的处理方式。
- 简单CRUD(创建、读取、更新、删除)操作,ORM框架通常能够更快捷地完成。
- ORM框架通过映射对象来简化数据层代码,有利于代码的整洁和可维护性。
- MyBatis需要编写和维护较多的XML或注解配置,可能增加工作量。
- 如果预计将来可能切换到不同的数据库系统,使用ORM框架可能更有优势,因为ORM框架能够屏蔽不同数据库之间的差异。
- 考虑到事务管理的复杂性,某些ORM框架提供了比MyBatis更高级的事务支持。
- 如果项目可能需要频繁地根据不同的业务情况进行定制化开发,MyBatis可能会提供更好的灵活性。
- ORM框架则可能在扩展上存在一定的限制。
若依系统采用的是MyBatis,下文梳理MyBatis在若依框架中的使用与封装。
如何高效优雅的封装Redis

上图是若依Redis工具类项目结构
RedisService:
import org.springframework.data.redis.core.RedisTemplate;
public class RedisService
{
@Autowired
public RedisTemplate redisTemplate;
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @param value 缓存的值
* @param timeout 时间
* @param timeUnit 时间颗粒度
*/
public <T> void setCacheObject(final String key, final T value, final Long timeout, final TimeUnit timeUnit)
{
redisTemplate.opsForValue().set(key, value, timeout, timeUnit);
}
/**
* 设置有效时间
*
* @param key Redis键
* @param timeout 超时时间
* @param unit 时间单位
* @return true=设置成功;false=设置失败
*/
public boolean expire(final String key, final long timeout, final TimeUnit unit)
{
return redisTemplate.expire(key, timeout, unit);
}
/**
* 获得缓存的基本对象。
*
* @param key 缓存键值
* @return 缓存键值对应的数据
*/
public <T> T getCacheObject(final String key)
{
ValueOperations<String, T> operation = redisTemplate.opsForValue();
return operation.get(key);
}
/**
* 删除集合对象
*
* @param collection 多个对象
* @return
*/
public boolean deleteObject(final Collection collection)
{
return redisTemplate.delete(collection) > 0;
}
/**
* 缓存List数据
*
* @param key 缓存的键值
* @param dataList 待缓存的List数据
* @return 缓存的对象
*/
public <T> long setCacheList(final String key, final List<T> dataList)
{
Long count = redisTemplate.opsForList().rightPushAll(key, dataList);
return count == null ? 0 : count;
}
/**
* 获得缓存的list对象
*
* @param key 缓存的键值
* @return 缓存键值对应的数据
*/
public <T> List<T> getCacheList(final String key)
{
return redisTemplate.opsForList().range(key, 0, -1);
}
}
RedisTemplate
上面是一个简化的封装方法,这里有一个特殊依赖 RedisTemplate,主要是理解什么是RedisTemplate,有哪些作用:
实际上RedisTemplate来自于 org.springframework.data.redis.core.RedisTemplate包, 他是 Spring Data Redis 提供的一个中心类,简化了 Redis 数据访问代码。
以下是 RedisTemplate 的一些关键特性:
- 连接管理:RedisTemplate 处理与 Redis 服务器的连接管理,用户不需要手动管理连接的开启和关闭。
- 序列化:支持各种类型的序列化策略,如 String 序列化、JDK 序列化、JSON
序列化等,确保数据在网络上传输之前以及保存到Redis时能够被正确地序列化和反序列化。 - 异常处理:RedisTemplate 封装了错误处理策略,将 Redis 异常转换为 Spring 统一的数据访问异常。
- API丰富:提供对各种Redis数据结构的操作方法,比如值(Value)、散列表(Hash)、列表(List)、集合(Set)和有序集合(Sorted
Set/ZSet)。 - 事务支持:通过使用 multi、exec 和 discard 命令,支持 Redis 中的事务操作。
- 脚本支持:可以执行 Lua 脚本来进行复杂的操作。
- 发布订阅:提供了发布(publish)和订阅(subscribe)功能。
在上述的RedisConfig.java文件中自定义了RedisTemplate的一些默认配置:
@Configuration
@EnableCaching
@AutoConfigureBefore(RedisAutoConfiguration.class)
public class RedisConfig extends CachingConfigurerSupport
{
@Bean
@SuppressWarnings(value = { "unchecked", "rawtypes" })
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory)
{
//调用RedisTemplate的构造函数来创建一个新的RedisTemplate实例
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);// 创建和管理与Redis服务器的连接
// Object.class:这个参数指示了序列化器处理的对象类型。在这里使用Object.class暗示序列化器可以用于任意类型的Java对象。
FastJson2JsonRedisSerializer serializer = new FastJson2JsonRedisSerializer(Object.class);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
// Hash的key也采用StringRedisSerializer的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
// 确保所需属性被设置后能正确地初始化RedisTemplate
template.afterPropertiesSet();
return template;
}
}
@AutoConfigureBefore注解标明RedisConfig 会优先RedisAutoConfiguration加载,以确保用户自定义的配置会覆盖自动配置项。
在redisTemplate方法中:
- 通过@Autowired注入RedisConnectionFactory,这是一个连接工厂,用于创建与Redis服务器的连接。
- 创建一个新的RedisTemplate
- 设置键(key)的序列化器为StringRedisSerializer,这样所有key都会被转换成字符串类型。
- 值(value)和Hash值的序列化器使用了自定义的FastJson2JsonRedisSerializer,这是一种基于Fastjson库的序列化器,它能够将Java对象序列化为JSON格式的字符串,也可以将JSON字符串反序列化回Java对象。
- 这段代码同时还设置了Hash的键(key)使用StringRedisSerializer进行序列化。
- 调用afterPropertiesSet方法是为了确保所需属性被设置后能正确地初始化RedisTemplate。
上面是一个封装好的redis工具类,看一下具体应用场景。
在上一篇介绍网关模块时应用到了缓存事例如下:
redisService.setCacheObject(verifyKey, code, Constants.CAPTCHA_EXPIRATION, TimeUnit.MINUTES);
- verifyKey:存储的键名
- code:存储的键值
- Constants.CAPTCHA_EXPIRATION:存储时长这里的值是2
- TimeUnit.MINUTES:存储时长的时间单位这里值的是分钟
下面是redis中存储验证码值的截图:
 模块封装梳理与MyBatis最佳实践】_第4张图片](http://img.e-com-net.com/image/info8/b5955369e1b844cdb79248ec736fd5a0.jpg)
将SQL语句放在XML映射文件中,而不是注解里,以保证SQL的清晰性和可维护性。
举例

动态SQL
MyBatis的动态SQL是指可以根据传入的参数动态生成SQL语句的一种机制。通过使用MyBatis提供的各种XML标签,你可以在映射文件中编写能够根据不同条件自适应改变的SQL。这些标签包括:
<if>:根据条件判断是否包含某个SQL片段。
, , :类似于Java中的switch语句,根据不同的条件执行不同的SQL片段。
, , <set>:用于动态地添加或去除SQL语句的前缀或后缀,如WHERE、SET关键字或逗号。
<foreach>:对集合进行遍历,常用于构建IN查询。
:允许创建一个变量并将其绑定到当前上下文,可用于复杂的表达式。
比如下面的简单例子:
<select id="selectUserList" parameterType="SysUser" resultMap="SysUserResult">
select u.user_id, u.dept_id, u.nick_name, u.user_name, u.email, u.avatar, u.phonenumber, u.sex, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by, u.create_time, u.remark, d.dept_name, d.leader from sys_user u
left join sys_dept d on u.dept_id = d.dept_id
where u.del_flag = '0'
<if test="userId != null and userId != 0">
AND u.user_id = #{userId}
if>
<if test="userName != null and userName != ''">
AND u.user_name like concat('%', #{userName}, '%')
if>
<if test="status != null and status != ''">
AND u.status = #{status}
if>
<if test="phonenumber != null and phonenumber != ''">
AND u.phonenumber like concat('%', #{phonenumber}, '%')
if>
<if test="params.beginTime != null and params.beginTime != ''">
AND date_format(u.create_time,'%y%m%d') >= date_format(#{params.beginTime},'%y%m%d')
if>
<if test="params.endTime != null and params.endTime != ''">
AND date_format(u.create_time,'%y%m%d') <= date_format(#{params.endTime},'%y%m%d')
if>
<if test="deptId != null and deptId != 0">
AND (u.dept_id = #{deptId} OR u.dept_id IN ( SELECT t.dept_id FROM sys_dept t WHERE find_in_set(#{deptId}, ancestors) ))
if>
${params.dataScope}
select>
上述例子中条件判断语句如果存在userId ,userName ,status ,phonenumber ,beginTime ,endTime ,deptId 则分别在Sql语句中拼接对应的查询条件。
语义解析:
<select id="selectUserList" ...>:定义了一个ID为selectUserList的查询操作,这个ID在Mapper接口中被引用。
parameterType="SysUser":指明传入参数的类型是SysUser类。
resultMap="SysUserResult":指定了返回结果的映射规则。
SQL查询语句:
- 从 sys_user(别名为 u)表中选择多个列,包括用户ID、部门ID、昵称等。
- 使用 LEFT JOIN 将 sys_dept(别名为 d)表连接到 sys_user 表上,以便获取部门相关信息,如果 sys_user
表中的某行没有匹配的 sys_dept 表中的记录,仍然会显示该用户的信息,但是部门相关的字段会被设置为 NULL。 - WHERE u.del_flag = ‘0’ 过滤条件,用于返回未被标记为删除的用户(假设 del_flag 字段为 '0’表示用户有效)。
至于什么是left join 或者如何写sql后面会单独找机会分享。
适当使用resultMap
在MyBatis中,resultMap是一种高级的结果映射机制,,resultMap提供了更多的灵活性和控制能力,特别是当处理复杂的关联或嵌套结果时。
比如下面的resultMap:
<resultMap type="SysUser" id="SysUserResult">
<id property="userId" column="user_id" />
<result property="deptId" column="dept_id" />
<result property="userName" column="user_name" />
<result property="nickName" column="nick_name" />
<result property="email" column="email" />
<result property="phonenumber" column="phonenumber" />
<result property="sex" column="sex" />
<result property="avatar" column="avatar" />
<result property="password" column="password" />
<result property="status" column="status" />
<result property="delFlag" column="del_flag" />
<result property="loginIp" column="login_ip" />
<result property="loginDate" column="login_date" />
<result property="createBy" column="create_by" />
<result property="createTime" column="create_time" />
<result property="updateBy" column="update_by" />
<result property="updateTime" column="update_time" />
<result property="remark" column="remark" />
<association property="dept" javaType="SysDept" resultMap="deptResult" />
<collection property="roles" javaType="java.util.List" resultMap="RoleResult" />
resultMap>
在举例动态SQL的时候里面的*resultMap=“SysUserResult”*就是指的上面的结构。
下面看一下接口请求时候返回的数据:
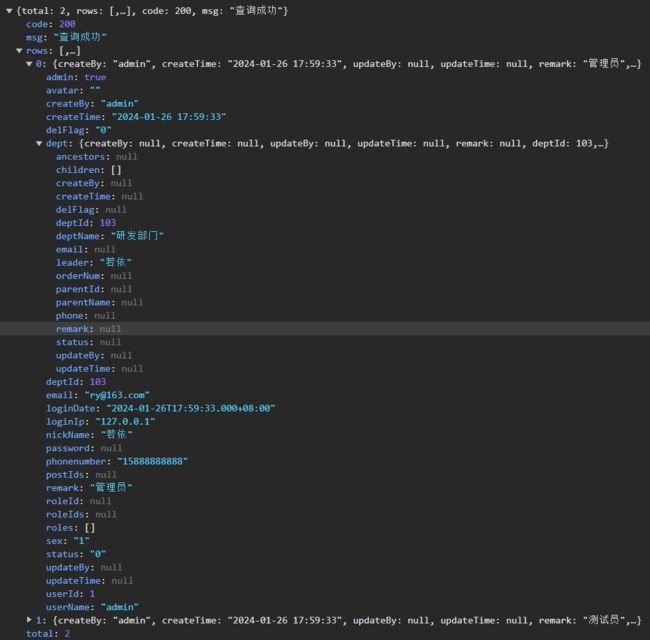
resultMap解析:
- id标签: 表示主键字段。
- column: 指定了结果集中的列名(数据库查询出来的名称)。
- property: 指定了要映射到Java对象的属性名(既返回接口中现实的名称)。
- type: 表示这个resultMap将会映射到哪一个Java类。在这个例子中,它映射到com.example包下的SysUser类
- id属性:用与匹配select查询
PageHelper分页大批量数据
PageHelper的使用请参考若依的实现,这里简明说一下使用方法:
PageUtils类中定义了两个静态方法:startPage和clearPage。
startPage() 方法
此方法将根据传递给TableSupport.buildPageRequest()的请求参数来设置分页信息。
- pageDomain:封装了分页请求的各种参数(如页码、每页数量、排序规则等)。
- pageNum和pageSize:从PageDomain获取当前页码和页面大小。
- orderBy:获取排序字段,并通过SqlUtil.escapeOrderBySql进行转义,以确保SQL注解是安全的,防止SQL注入攻击。
- PageHelper.startPage是PageHelper分页插件提供的方法,它将开始对接下来第一个MyBatis查询进行分页处理。
- setReasonable(reasonable)设置是否合理化分页参数,如果为true,当pageNum<=0时会返回第一页数据,pageNum>总页数时返回最后一页数据;默认false。
- clearPage() 方法调用PageHelper.clearPage()来清除线程局部变量中的分页参数。
下面是一个查询用户数据的写法:
/**
* 获取用户列表
*/
@RequiresPermissions("system:user:list")
@GetMapping("/list")
public TableDataInfo list(SysUser user)
{
startPage(); // 会自动对下面的查询做分页处理
List<SysUser> list = userService.selectUserList(user);
return getDataTable(list);
}
N+1查询问题
N+1问题简单的理解就是如何最大程度的减少Sql查询次数,尤其是在做关联查询的时候。
其实在本例子中的resultMap 中已经解决了这个问题:
<association property="dept" javaType="SysDept" resultMap="deptResult" />
<collection property="roles" javaType="java.util.List" resultMap="RoleResult" />
association 用来处理一对一的关系,在定义时需要指明属性名(property)、Java类型(javaType)以及映射规则(resultMap 或 column + select)。通过 association,可以将查询的结果集中的一部分列映射到一个关联的对象属性中。
上面表示有一个名为 dept 的属性,它是一个 SysDept 类型的对象。resultMap=“deptResult” 指出了如何将 sys_dept 表的数据映射到 SysDept 对象中。必须已经在某处定义了一个 ID 为 deptResult 的 resultMap。
collection 用来处理一对多的关系,也就是一个属性对应多个对象构成的列表。同样,collection定义时需要指明属性名、Java类型以及相关联的 resultMap。
上面表示有一个名为 roles 的属性,它是一个 List 类型,存放的是多个 角色 对象。resultMap=“roleResult” 指出了如何将 sys_role 表的数据映射到角色对象列表中。同样地,必须存在一个 ID 为 roleResult 的 resultMap 来描述角色对象的映射方式。
上面的语句可以理解为这样的需要:
有一个用户类 SysUser,它与一个部门类 SysDept 有一个一对一关系,同时与角色类 Role 存在一对多关系。
上班期间码这么多字太离谱了