【程序员的自我修养11】栈与函数调用过程

绪论
大家好,欢迎来到【程序员的自我修养】专栏。正如其专栏名,本专栏主要分享学习《程序员的自我修养——链接、装载与库》的知识点以及结合自己的工作经验以及思考。编译原理相关知识本身就比较有难度,我会尽自己最大的努力,争取深入浅出。若你希望与一群志同道合的朋友一起学习,也希望加入到我们的学习群中。文末有加入方式。
介绍
首先我们来看一张Linux进程中经典的内存布局图:
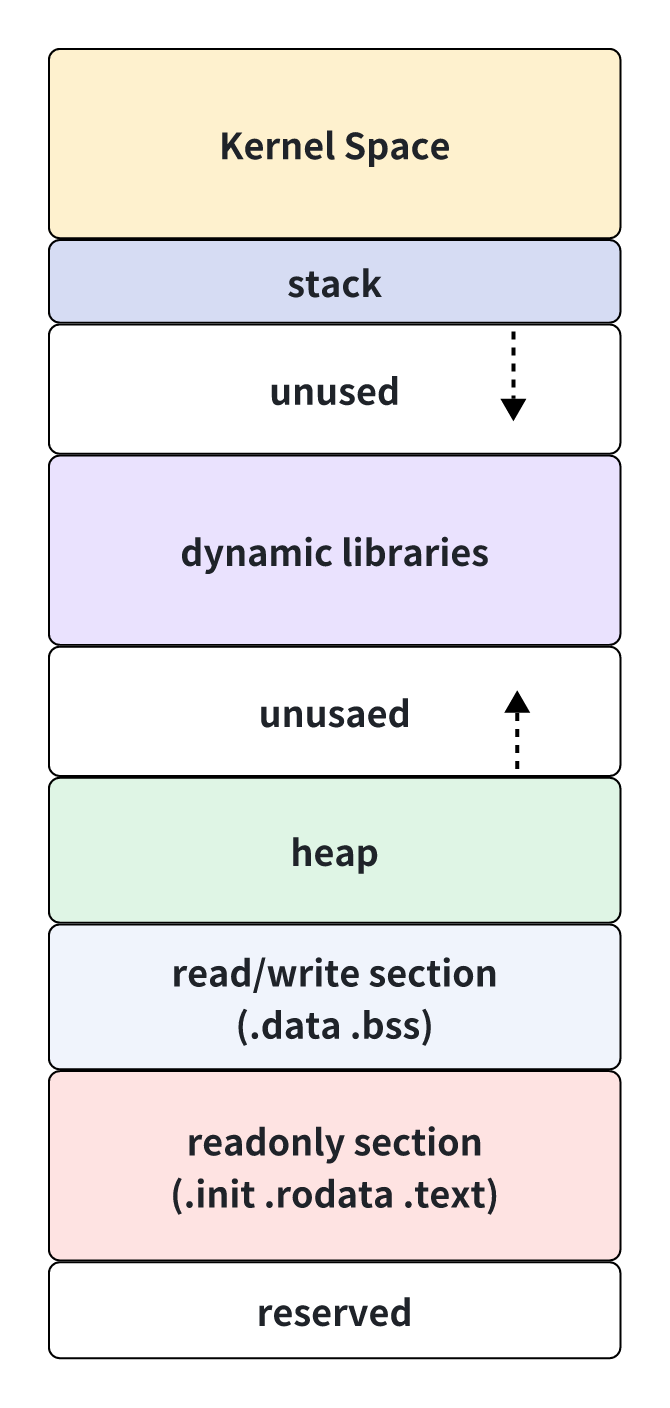
分析:
- 内核空间:是操作系统内核运行的区域,它是内核中一个重要的部分,专门为内核以及与内核直接相关的操作和进程提供服务。用户空间无法直接访问内核空间。
- 栈:栈用于维护函数调用的上下文。离开了栈,函数调用就无法实现。栈通常在用户空间的最高地址处分配,通常大小为8M。往地址方向生长。
- 堆:堆是用来容纳应用程序动态分配的内存区域,当程序使用
malloc或new分配内存时,得到的内存来自堆里。往高地址生长。 - 动态库:用于程序运行时,动态链接器或在程序运行过程中通过
dlopen加载的动态库,其代码段都会保存在该内存空间。 - 可读写段:用保存程序或动态库的全局变量或静态变量。
- 只读段:用于保存程序的代码段或只读数据区等。
- 保留区:是对内存中受到保护而禁止访问的内存区域的总称。比如地址NULL。
通过前面的章节,我们已经介绍了可执行程序和动态库加载到内存的过程。目前只有栈和堆没有介绍,本章主要介绍Linux下,函数的调用过程及其栈的变化。强烈建议大家认真理解,本章内容在一些特定调试场景非常有用。
栈
我们先看一个示例:
int setReg(long* reg)
{
*reg = 1;
return 0;
}
int main()
{
long reg1 = 0xfff0001;
long reg2 = reg1;
setReg((long*)reg2);
return 0;
}
编译:
yihua@ubuntu:~/test/stack$ gcc main.c -o main
yihua@ubuntu:~/test/stack$
假如在这样的一个场景:你对外提供setReg接口,用于设置寄存器值。但是由于调用者传入一个非法寄存器,导致程序异常,生成coredump。如何确定传入的寄存器是多少呢?因为main程序编译过程没有增加-g选项,因此gdb无法通过info locals查看局部变量信息。如下:
yihua@ubuntu:~/test/stack$ gdb main
GNU gdb (Ubuntu 8.1.1-0ubuntu1) 8.1.1
Copyright (C) 2018 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from main...(no debugging symbols found)...done.
(gdb) r
Starting program: /home/yihua/test/stack/main
Program received signal SIGSEGV, Segmentation fault.
0x000055555555461b in setReg ()
(gdb) bt
#0 0x000055555555461b in setReg ()
#1 0x0000555555554608 in main ()
(gdb) f 0
#0 0x000055555555461b in setReg ()
(gdb) info locals
No symbol table info available.
我们知道coredump 保存了进程崩溃一瞬间的所有内存信息,那么栈空间的内容理应也被保存下来了,而函数的局部变量和入参也是保存在栈空间的。顺着这个思路,我们是否可以通过了解栈空间的布局,从而解答上面的疑问呢?
堆栈帧
在x86-64环境下,栈顶是由rsp寄存器进行定位,压栈就是使rsp寄存器减小,出栈就是让rsp寄存器增大。如下:
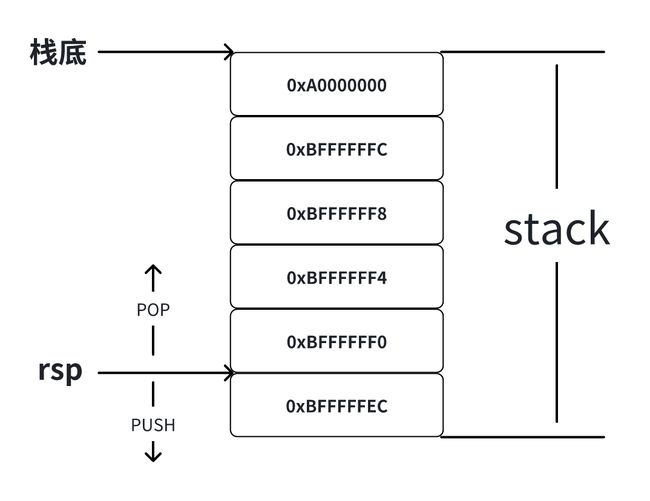
而栈中保存了一个函数调用所有需要的维护信息,其通常称为堆栈帧或活动记录,包含以下信息:
- 函数的返回地址和参数。
- 临时变量。比如函数非静态局部变量以及编译器自动生成的其它临时变量。
- 保存函数上下文。比如寄存器内容,需要确保函数调用后,相关寄存器恢复原样。
在x86-64环境中,一个函数的堆栈帧通过rbp和rsp两个寄存器划定范围。
rsp寄存器始终指向栈的顶部,同时也就指向了当前函数的活动记录的顶部。rbp寄存器指向了活动页的固定位置,又称为帧指针。
函数的调用流程总是以下流程:
- 把所有或一部分参数压入到栈或寄存器中。
- 把当前指令的下一条指令的地址压入栈中。
- 跳转到函数体中执行。
注:其中第二步和第三步是由指令call一起执行的。
函数体的标准开头大致如下:
push rbp:把rbp寄存器压入栈中。mov rbp,rsp:即rbp=rsp(这时rbp指向栈顶,而此时栈顶就是old rbp)。- 【可选】
sub rsp,XXX:在栈上分配XXX字节的临时空间。 - 【可选】
push XXX,如有必要,保存名为XXX寄存器在栈中。(可重复多个)
分析:把rbp压入栈中,是为了在函数返回的时候便于恢复以前的rbp值。而之所以可能要保存一些寄存器,在于编译器可能要求某些寄存器在调用前后保持不变,那么函数就可以在调用开始时将这些寄存器的值压入栈中,在结束后再去除。
函数体的标准结尾大致如下:
- 【可选】
pop XXX:如有必要,恢复保存过的寄存器。(可重复多个)。 mov rsp,rbp:恢复rsp,同时回收栈空间。pop rbp:从栈中恢复保存的rbp值。ret:从栈中取得返回地址,并跳转到该位置。
由以上内容,我们可知一个常见的活动页记录大致如下图:

现在我们再回过头,来分析如何从gdb中获取传入参数的值。分析:
第一步:main函数在调用setReg时,需要将入参保存到栈中或寄存器。那么我们如何确定该值是保存在寄存器还是栈中呢?分析汇编:objdump -d main,输出大致如下:
...
00000000000005fa :
5fa: 55 push %rbp
5fb: 48 89 e5 mov %rsp,%rbp
5fe: 48 89 7d f8 mov %rdi,-0x8(%rbp)
602: 48 8b 45 f8 mov -0x8(%rbp),%rax
606: 48 c7 00 01 00 00 00 movq $0x1,(%rax)
60d: b8 00 00 00 00 mov $0x0,%eax
612: 5d pop %rbp
613: c3 retq
0000000000000614 :
614: 55 push %rbp
615: 48 89 e5 mov %rsp,%rbp
618: 48 83 ec 10 sub $0x10,%rsp
61c: 48 c7 45 f0 01 00 ff movq $0xfff0001,-0x10(%rbp)
623: 0f
624: 48 8b 45 f0 mov -0x10(%rbp),%rax
628: 48 89 45 f8 mov %rax,-0x8(%rbp)
62c: 48 8b 45 f8 mov -0x8(%rbp),%rax
630: 48 89 c7 mov %rax,%rdi
633: e8 c2 ff ff ff callq 5fa
638: b8 00 00 00 00 mov $0x0,%eax
63d: c9 leaveq
63e: c3 retq
63f: 90 nop
...
由main函数汇编可知,在callq setReg前,main函数通过mov %rax,%rdi进行传参,即将实参传入到了%rdi寄存器中。同理setReg的汇编语句中 mov %rdi,-0x8(%rbp),将%rdi寄存器的值保存到了栈中,因此基本确定main与setReg之间是通过%rdi寄存器进行传参的。

通过info registers查看寄存器值,可知rdi寄存器值为0xfff0001,与预期相符。同理若通过汇编语句,发现实参是通过栈空间传递的,那我们可以通过x /16xg $rbp打印栈内容,从而分析实参内容。
调用惯例
上述流程能够正常执行的依据是,函数的调用方和被调用方对函数调用有着统一的理解。比如,若main函数默认通过寄存器进行传参,但是setReg认为是通过栈空间进行传参。那么最终的结果肯定是错误的。
因此函数的调用方和被调用方对于如何调用必须要有一个明确的约定,只有双方都遵守同样的约定,函数才能被正确地调用。这样的约定称为调用惯例。一般会固定以下几方面:
- 函数参数的传递方式和方式
函数参数的传递由很多种方式,最常见的一种是通过栈传递。函数的调用方将参数压入栈中,函数自己再从栈中将参数去除。对于有多个参数的函数,调用惯例要规定函数调用方将参数压栈的顺序:是从左至右,还是从右至左。有些调用惯例还允许使用寄存器传递参数,以提高性能。比如x86-64。
- 栈的维护方式
在函数将参数压栈之后,函数体会被调用,此后需要将压入栈中的参数全部弹出,以使得栈在函数调用前后保持一致。这个弹出的工作可以由函数的调用方完成,也可以由函数本身完成。
- 名字修饰的策略
为了链接的时候对调用惯例进行区分,调用惯例需要对函数本身的名字进行修饰。不同调用惯例有不同的名字修饰策略。
常见的调用惯例如下,其中C语言默认是cdecl。
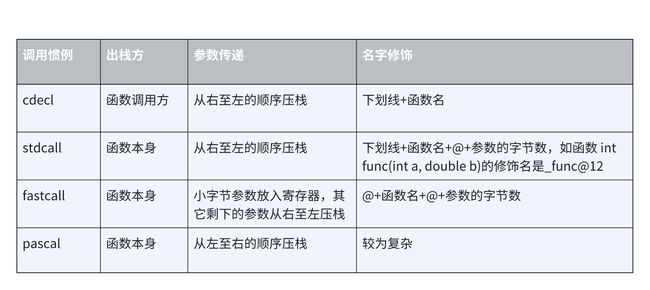
因此,为了代码的可移植性,我们应避免写出func(i++,i++)的代码,因为不同的调用惯例,实参的执行顺序是不同的,可能会导致预期不一样。
总结
通过本文,大致了解了栈空间的分布,以及函数调用过程栈内存的部分。通过了解函数调用过程,我们可以在一些特定场景,去获取更多的有用信息。这在调试阶段,非常适用。可参考Linux 调试进阶(多场景覆盖)。
若我的内容对您有所帮助,还请关注我的公众号。不定期分享干活,剖析案例,也可以一起讨论分享。
我的宗旨:
踩完您工作中的所有坑并分享给您,让你的工作无bug,人生尽是坦途

