C语言-4
排序算法简介
/*
学习内容:
冒泡排序(最基本的排序方法)
选择排序(冒泡的优化)
插入排序(在合适的位置插入合适的数据)
*/
/*
排序分类:
1.内部排序
待需要进行排序的数据全部存放到内存中,再进行排序
2.外部排序
在排序过程中,需要对外存进行访问
待排序的数据数量很大,内存无法全部容纳所有的数据
*/
冒泡排序
/*
冒泡排序:
---思路分析(以升序为例)
在一排数据中,将第一个与第二个比较大小
如果后面的数据比前面的小,就交换它们的位置(冒泡一次)
然后比较第二个和第三个
...
直到比较第 n-1 个数据和第 n 个
每一次比较都将较大的一个数据向后移动
所以第 n 个是最大的
所以就排好了一个数据(冒泡一趟)
*/
# include
int main()
{
// 定义一个无序一维数组
int arr[] = { 5, 7, 9, 1, 6, 2, 4, 3, 0, 8 };
// 遍历,打印数组
printf("数组,排序前:\n");
for (int i = 0; i < 10; i++)
{
printf("%-3d", arr[i]);
}
// 冒泡排序(升序:由小到大)
int temp;
for (int i = 0; i < 9; i++)
{
for (int j = 0; j < 9 - i; j++)
{
if (arr[j] > arr[j + 1])
{
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
// 展示排序后,数组当前的结果
printf("数组,排序后:\n");
for (int i = 0; i < 10; i++)
{
printf("%-3d", arr[i]);
}
}
选择排序
/*
选择排序:
---思路分析(以升序为例)
选择排序可以看作是冒泡排序的优化
不再多次交换值,而是选择当前趟数的最大(或最小值),最后再交换
在 n 个数里,先找到最大的数,并且记录下标,然后将这个数与第 n 个数交换
如果第 n 个数是最大的,那就不需要交换,重复比较,直到所有的数据排好序
*/
# include
int main()
{
// 定义一个无序一维数组
int arr[] = { 5, 7, 9, 1, 6, 2, 4, 3, 0, 8 };
// 遍历,打印数组
printf("\n 数组,排序前:\n");
for (int i = 0; i < 10; i++)
{
printf("%-3d", arr[i]);
}
// 选择排序(升序:由小到大)---> 选择排序:选择一个你认为最大的数
int temp;
int maxIndex;
for (int i = 9; i > 0; i--)
{
maxIndex = 0; // 每次我都认为第一个最大,选择第一个,并记录下第一个的序号
for (int j = 0; j <= i; j++)
{
if (arr[maxIndex] < arr[j])
{
maxIndex = j;
}
}
if (maxIndex != i)
{
temp = arr[i];
arr[i] = arr[maxIndex];
arr[maxIndex] = temp;
}
}
// 展示排序后,数组当前的结果
printf("\n 数组,排序后:\n");
for (int i = 0; i < 10; i++)
{
printf("%-3d", arr[i]);
}
}
插入排序
/*
插入排序:
---思路分析(以升序为例)
以第一个数为基准,后面的所有数都向着第一个数的方向,插队前进(这种插队不能跳着插队,只能插完一个继续接着插,前提是满足条件才能插队)
其本质原理:依靠数与数之间的“相对关系”,从而将其整体排好序!
1.轮到第一个数发挥 第一个数无法插队,它只能站着不动,停止插队
2.轮到第二个数发挥 它和前面的数比较大小,若满足条件,则插一个队,然后停止插队(即:最多能够插队1次)
3.轮到第三个数发挥 和前面的数比较大小,若满足条件,则插一个队,再继续和前面的数比较大小,若满足条件,则再插一个队,然后停止插队(即:最多能够插队2次)
4.轮到第四个数发挥 比较大小,若可以,插一个队,再继续比较大小,若可以,再插一个队......(即:最多能够插队3次)
5.轮到第五个数发挥 ......(即:最多能够插队4次)
6.轮到第六个数发挥 ......(即:最多能够插队5次)
*/
# include
int main()
{
// 定义一个无序一维数组
int arr[] = { 7, 5, 9, 1, 6, 2, 4, 3, 0, 8 };
// 遍历,打印数组
printf("\n 数组,排序前:\n");
for (int i = 0; i < 10; i++)
{
printf("%-3d", arr[i]);
}
// 插入排序(升序:由小到大)
int temp = 0;
for (int i = 1; i < 10; i++) // 轮到第 ?个数发挥
{
for (int j = i - 1; j >= 0; j--) // 【比较、插队】,再【比较、插队】,再再【比较、插队】......
{
if (arr[j + 1] < arr[j]) // 满足插队条件
{
temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
}
else // 不满足插队条件
{
break; // 没有达到"最多能插队的次数",就停止插队了,请马上自我了断,不要再进行无意义的比较,从而提高效率
}
}
}
// 展示排序后,数组当前的结果
printf("\n 数组,排序后:\n");
for (int i = 0; i < 10; i++)
{
printf("%-3d", arr[i]);
}
return 0;
}
线性表
/*
1.线性表:
---数据结构中最简单的一种存储结构,专门用于存储逻辑关系为"一对一"的数据
2.线性表存储结构,可细分为"顺序存储结构"和"链式存储结构",即如下所示
线性表:
1.顺序表(顺序存储结构)
2.链表(链式存储结构)
3.存储的类型要求
使用线性表存储的数据,如同向数组中存储数据那样要求数据类型必须一致
线性表存储的数据,要么全部都是整型,要么全部都是字符串
一半整型,另一半是字符串的一组数据无法使用线性表存储
4.前驱与后继:
一组数据中的每个个体被称为“数据元素”(简称为“元素”)
1.前驱
某一元素的左侧相邻元素称为“直接前驱”,位于此元素左侧的所有元素都统称为“前驱元素”
2.后继
某一元素的后侧相邻元素称为“直接后继”,位于此元素右侧的所有元素都统称为“后继元素”
*/
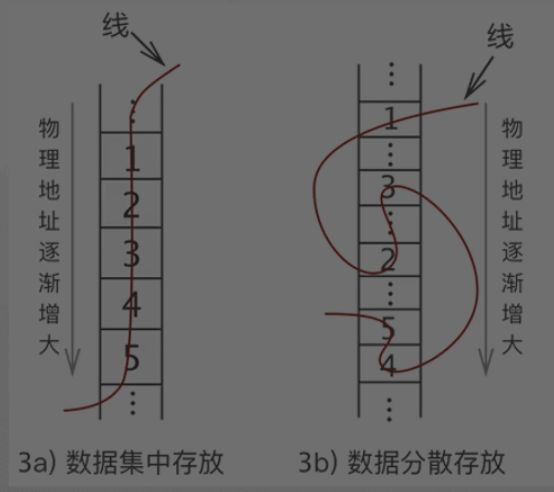

顺序表
/*
顺序表:
---它对数据的物理存储结构有要求
顺序表存储数据时,会提前申请一块足够大小的内存
然后将数据依次存储起来
存储时做到数据元素之间不留一丝缝隙(即:连续)
*/
初始化顺序表
# include
# include
// 定义表格类型
typedef struct
{
int* head; // 指针,存储申请的内存首地址
int length; // 当前数据个数
int size; // 元素个数(最大容量)
}Table;
// 生成表格的函数
Table tableFunc()
{
Table t; // 定义一个变量 t ,其类型为“表格类型”
// t 表格的初始化
t.size = 5; // 表格最大容量(元素个数) = 5
t.length = 0; // 表格当前数据个数(元素个数)= 0
t.head = (int*)calloc(t.size,sizeof(int)); // 为表格开辟内存,并把内存首地址赋值给 t.head
// 注意!上面的申请内存操作可能会出现申请失败的情况,返回值为 NULL
if (!NULL)
{
printf("申请内存失败,程序终止!\n");
exit(0);
}
return t; // 返回 t 表格
}
int main()
{
Table myTab = tableFunc();
printf("%d \n", myTab.size);
printf("%d \n", myTab.length);
printf("%X \n", myTab.head); // 内存地址一般用 %X 十六进制展示
return 0;
}
顺序表的增删查改
/*
顺序表元素:
1.查(可以使用查找算法: 1.顺序查找 2.二分法查找)
2.改
3.增(增加到前面、中间、后面)------知识点补充:扩容函数:realloc(需要扩容的指针"*p",扩容后总的大小)
4.删
*/
链表
/*
1.链表:
1.链表是通过指针,将不连续的内存连接起来,实现链式存储的
2.内存实际上是不同时机申请的,地址不一定连续,但是可以通过指针联系起来
3.链表是数据结构中线性表的一种,其中的每个元素实际上是一个“单独的结构体变量”,
所有变量都“通过”每个元素中的“指针”连接在一起。
4.以结构体为节点,将一个结构体看成“数据域”和“指针域”两个部分,
“数据域”用于“存储数据”,“指针域”用于“连接下一个节点”,链表中每个结构体对象叫做节点,
其中,第一个数据节点,叫做链表的“首元结点”。
5.如果第一个节点不用于存储数据,只用于代表链表的起始点,则这个结点称为链表的“头结点”。
2.链表特点:
1.没有固定长度
2.可以快速的插入和删除链表中的节点
3.链表分很多种,单链表是其中最简单的一种(如下图)
*/

单链表
/*
<单链表>
1.链表节点一般是自定义的结构体类型
2.结构体一般包含两部分:数据、指针
数据:当前节点里面需要的数据
指针:指向下一个节点(最后一个节点置空 为“尾节点”)
*/

创建单链表
-
项目结构

-
源代码
// main.c
# include
# include "myList.h"
int main()
{
Node* pList=CreateList(5); // 创建一个可以存储5个东西的链表,并将返回值“地址”赋值给变量 pList
showList(pList); // 展示链表
return 0;
}
// myList.c
# include
# include "myList.h"
# include // 申请内存时候要用
/*
创建链表
参 数:长度
返回值:头指针
*/
Node* CreateList(int length)
{
// 判断长度
if (length <= 0)
{
printf("Length Error!\n");
return NULL;
}
// 开始创建链表
// 1.创建头指针和尾指针
Node *phead, *ptail;
phead = ptail = NULL;
// 2.申请内存:头结点
phead = (Node*)malloc(sizeof(Node));
// 3.处理异常情况
if (NULL == phead)
{
perror("malloc failed!");
exit(EXIT_FAILURE);
}
// 4.给头结点初值
phead->pnext = NULL; // 等价于 (*phead).pnext = NULL;
phead->num = 0;
// 5.尾指针
ptail = phead;
// 6.向头结点后面添加结点
Node* p;
DataType n;
for (int i = 0; i < length; i++)
{
// 6.1 申请一个结点,检测,给值
p= (Node*)malloc(sizeof(Node));
if (NULL == p)
{
perror("malloc failed!");
exit(EXIT_FAILURE);
}
p->pnext = NULL;
printf("请输入数值>>>");
scanf("%d", &n);
p->num = n;
// 6.2 将新申请的结点添加到链表中
ptail->pnext = p;
ptail = p; // 更新尾结点
}
return phead; // 9.返回头指针
}
/*
遍历链表
参 数:头指针
返回值:空
*/
void showList(const Node* const p)
{
// 从首元结点开始遍历,而不是头结点(因为我们不使用头结点去存储值)
Node* temp = p->pnext;
if (NULL == temp)
{
printf("List is NULL!\n");
return ;
}
printf("\n*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*\n");
printf("当前链表数据:\n");
while (temp)
{
printf("%-5d", temp->num);
temp = temp->pnext;
}
printf("\n*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*\n");
}
// myList.h
#ifndef _MYLIST_ // 防止重复定义
#define _MYLIST_
typedef int DataType; // 可以灵活改变数据类型
struct node
{
struct node* pnext; // 指针域
DataType num; // 数据域
};
typedef struct node Node; // 给结构体类型取别名
/*
创建链表
参 数:长度
返回值:头指针
*/
Node* CreateList(int length);
/*
遍历链表
参 数:头指针
返回值:空
*/
void showList(const Node* const p);
#endif // _MYLIST_ 定义结束
单链表的查改增删
/*
单链表的查、改、增、删
1.查:确定查找方式,查找之后一般会返回“结点首地址”或者返回 NULL
2.改:找到目标元素,直接修改该元素的值
3.增:一定注意不能丢失指针指向
4.删:记得释放内存
*/
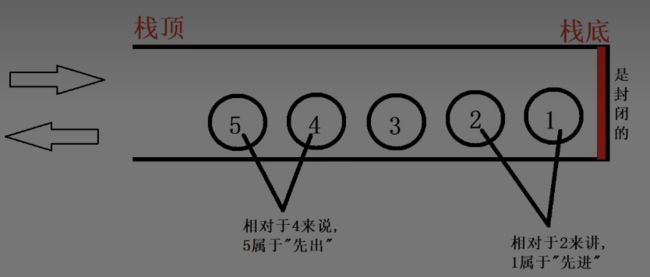
栈
/*
栈的定义:
---栈是一种只能从表的一端存储数据,且遵循“先进后出”原则的"线性存储结构"
1.栈只能从一端(栈顶)取出,另一端(栈底)是封闭的
2.在栈中,都必须从“栈顶”存储数据,且遵循“先进后出”原则
入栈和出栈:
1.入栈:将数据存到栈里面去
2.出栈:将数据从站里面取出来
栈的实现方法:
---栈:“特殊”的线性存储结构
1.顺序表:顺序栈(顺序存储结构)
2.链 表:链 栈(链式存储结构)
*/
实现顺序栈
# include
/* 1.元素入栈 */
// 参 数:存储结构,栈顶 top,数据 value
// 返回值: top
int putEle(int* arr, int top, int value)
{
arr[++top] = value;
return top;
}
/* 2.元素入栈 */
// 参 数:存储结构,栈顶 top
// 返回值: top
int takeEle(int* arr, int top)
{
// 先判断
if (top <= -1)
{
printf("操作失败!空栈!\n");
return -1;
}
printf("当前出栈元素的值:%d\n", arr[top]);
top--;
return top;
}
int main()
{
// 顺序表:为了理解简单化,我们使用列表
int a[100];
// top (记录栈顶)
int top = -1;
// 入栈(入5个)
top = putEle(a, top, 1);
top = putEle(a, top, 2);
top = putEle(a, top, 3);
top = putEle(a, top, 4);
top = putEle(a, top, 5);
// 出栈(出6个)
top = takeEle(a, top);
top = takeEle(a, top);
top = takeEle(a, top);
top = takeEle(a, top);
top = takeEle(a, top);
top = takeEle(a, top);
return 0;
}
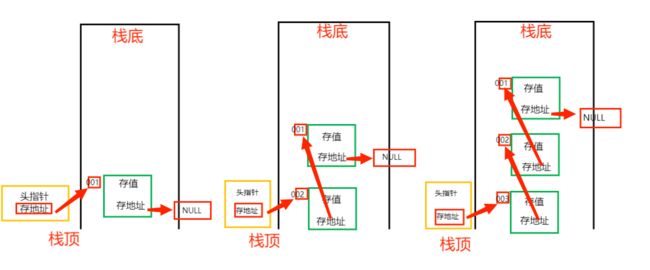
实现链栈
/*
链栈:
一般来说,我们将链表的“头结点”作为栈顶,“尾结点”作为栈底,这样的效率高一些(如图所示)
注意事项:
“头结点”是不断更新的,即“头结点”永远是“刚进来”的那个
“尾结点”是不会更新的,即“尾结点”永远是“第一个进来”的那个
---如果用另外一种方式:
头结点”作为栈底,“尾结点”作为栈顶,这种方式,每次新的元素入栈,都要从栈底遍历一遍到栈顶,才能入栈成功
将会遍历很多次,效率非常低下
*/
#include
#include
typedef struct Node
{
int data;
struct Node* pnext;
}Node;
// 入栈函数
Node* eleIn(Node* p, int num)
{
Node* temp = (Node*)malloc(sizeof(Node));
temp->data = num;
temp->pnext = p;
p=temp;
printf("当前进栈元素的值:%d\n", num);
return p;
}
// 出栈函数
Node* eleOut(Node* p)
{
if (p)
{
Node* temp = p;
printf("当前出栈元素的值:%d\n", temp->data);
p = temp->pnext;
free(temp);
temp = NULL;
}
else
{
printf("栈是空的!\n");
}
return p;
}
int main()
{
Node* p = NULL;
// 进栈(5次)
p = eleIn(p, 1);
p = eleIn(p, 2);
p = eleIn(p, 3);
p = eleIn(p, 4);
p = eleIn(p, 5);
printf("*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*\n");
// 出栈(6次)
p = eleOut(p);
p = eleOut(p);
p = eleOut(p);
p = eleOut(p);
p = eleOut(p);
p = eleOut(p);
return 0;
}
队列
/*
<队列>
1. 什么是队列
队列:两端“开口”
要求:只能从一端进入队列,另一端出队列
2.队头和队尾
队头:数据出队列的一端
队尾:数据进队列的一端
3.实现队列
1.顺序表:顺序队列
2.链表:链式队列
*/

顺序队列
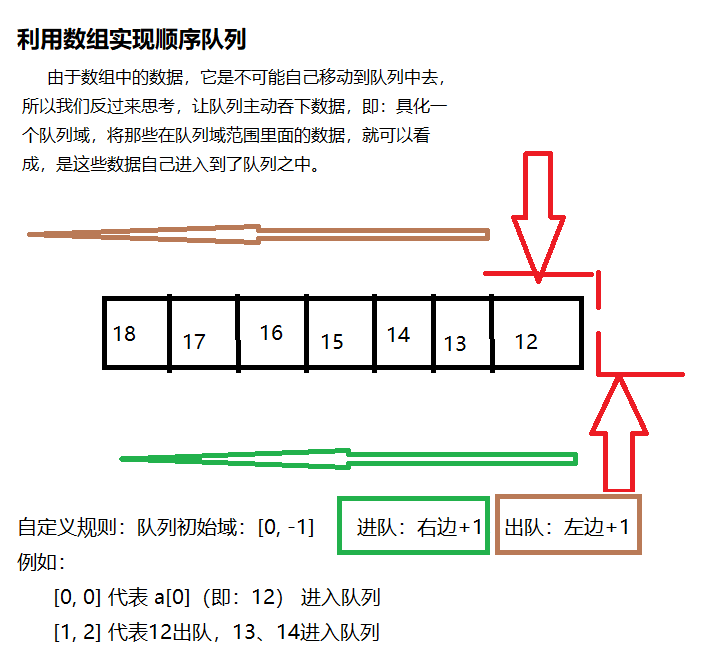
#include
// 进队函数
int eleIn(int* arr,int tail,int num)
{
arr[++tail] = num;
printf("当前进入队列元素的值:%d\n", num);
return tail;
}
// 出队(全部出队)
void allOut(int* arr, int head, int tail)
{
while (head != tail)
{
printf("当前离开队列元素的值:%d\n", arr[head++]);
}
printf("当前离开队列元素的值:%d\n", arr[head++]);
}
int main()
{
int a[10]; // 定义数组,用于存储数据
int head = 0;
int tail = -1;
// 入队(进入5)
tail = eleIn(a, tail, 1);
tail = eleIn(a, tail, 2);
tail = eleIn(a, tail, 3);
tail = eleIn(a, tail, 4);
tail = eleIn(a, tail, 5);
printf("*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*\n");
// 出队(全出去)
allOut(a, head, tail);
return 0;
}
链式队列
#include