教授LLM思考和行动:ReAct提示词工程
ReAct:论文主页
原文链接:Teaching LLMs to Think and Act: ReAct Prompt Engineering
在人类从事一项需要多个步骤的任务时,而步骤和步骤之间,或者说动作和动作之间,往往会有一个推理过程。让LLM把内心独白说出来,然后再根据独白做相应的动作,来提高LLM答案的准确性。---ReAct的核心思想
普林斯顿大学的教授和谷歌的研究人员最近发表了一篇论文,描述了一种新颖的提示工程方法,该方法使大型语言模型(例如 ChatGPT)能够在模拟环境中智能地推理和行动。 这种 ReAct 方法模仿了人类在现实世界中的运作方式,即我们通过口头推理并采取行动来获取信息。 人们发现,与各个领域的其他提示工程(和模仿学习)方法相比,ReAct 表现良好。 这标志着朝着通用人工智能(AGI)和具体语言模型(像人类一样思考的机器人)迈出了重要一步。
1、背景
在本节中,我将讨论大型语言模型、提示工程和思维链推理。
1.1 大型语言模型
大型语言模型 (LLM) 是一种机器学习 Transformer 模型,已在巨大的语料库或文本数据集(例如互联网上的大多数网页)上进行训练。 在训练过程中,需要大量时间(和/或 GPU)、能源和水(用于冷却),采用梯度下降来优化模型参数,使其能够很好地预测训练数据。
本质上,LLM学习在给定一系列先前单词的情况下预测最可能的下一个单词。 这可用于执行推理(查找模型生成某些文本的可能性)或文本生成,ChatGPT 等LLM用它来与人交谈。 一旦 LLM 完成训练,它就会被冻结,这意味着它的参数被保存,并且不会向其训练数据添加输入或重新训练 - 这样做是不可行的,正如我们从 Microsoft 的 Tay 聊天机器人成为纳粹分子中了解到的那样 ,无论如何,最好不要向用户学习。
值得注意的是,LLM仍然从他们的训练数据中学习到偏见,而 ChatGPT 背后的 OpenAI 必须添加保护措施——使用来自人类反馈的强化学习 (RLHF)——试图防止模型生成有问题的内容。 此外,由于LLM默认情况下只是根据他们所看到的内容生成最有可能的下一个单词,而不进行任何类型的事实检查或推理,因此他们很容易产生幻觉,或编造事实和推理错误(例如在做时) 简单的数学)。
自从 ChatGPT 的公开发布风靡全球以来,LLM 就一直风靡一时。 这些模型的新兴智能及其在我们生活的许多方面的应用使它们成为一种非常受欢迎的工具,每个公司都想从中分一杯羹。 除了聊天机器人、编码和写作助手之外,LLM还被用来创建与模拟环境(包括互联网)交互的代理。 ReAct 就是一个如何将LLM转变为此类代理的示例。
1.2 提示工程
如果你尝试过 ChatGPT,就会知道有时它会拒绝回答问题或回答不好,但如果你重新表述问题,可能会得到更好的结果。 这是提示工程的艺术——通过修改你的输入,让提示工程按照你想要的方式做出反应。
我们的想法是,LLM接受了如此多的人类生成数据的训练,以至于他们几乎可以被视为人类——而不是在特定问题领域训练新模型,而是可以尝试从现有的冻结模型中得出正确的响应。 LLM 通过提出一些事实来“唤起它的记忆”或告诉它一个新领域。 这称为上下文学习(in-context learning),主要有两种类型:零样本学习和少样本学习。 零样本学习为LLM提供了一个提示,其中可以在问题/命令之前包含一些背景信息,以帮助LLM找到良好的答案。 少样本学习为LLM提供了一些提示示例和理想的响应,然后提出了一个新的提示,LLM将以示例的形式做出响应。
提示工程是自然语言处理 (NLP) 的未来。 该领域正在从定制模型转向定制提示,因为LLM比任何人无需花费大量时间和精力就可以自己制作的东西要好得多。 当LLM与正确的提示工程技术相结合时,它通常可以做专业模型可以做的任何事情。
1.3 思维链推理
思想链推理是一种流行的提示工程技术,旨在解决推理错误。 它涉及向LLM提供一个或多个示例(少量学习),说明如何通过口头推理解决问题,然后为其提供一个不同的问题以这种方式解决。 这可以帮助解决推理错误,但它仍然会产生幻觉,而幻觉的“事实”可以通过推理传播,导致模型无论如何都得出错误的结论。
在下面的 ReAct 论文中的图片中,针对需要多个推理步骤才能弄清楚的问题,将标准提示(仅提出问题)与思维链 (CoT) 提示(尽管未显示附加输入)进行了比较 。
标准提示的LLM猜测是 iPod,这是不正确的。 有CoT提示的LLM有更令人信服的回应,但它仍然是错误的。 尽管推理无懈可击,LLM却幻觉 Apple Remote 最初是为与 Apple TV 配合使用而设计的(它实际上是为 Front Row 项目设计的),这导致其得出错误的结论。
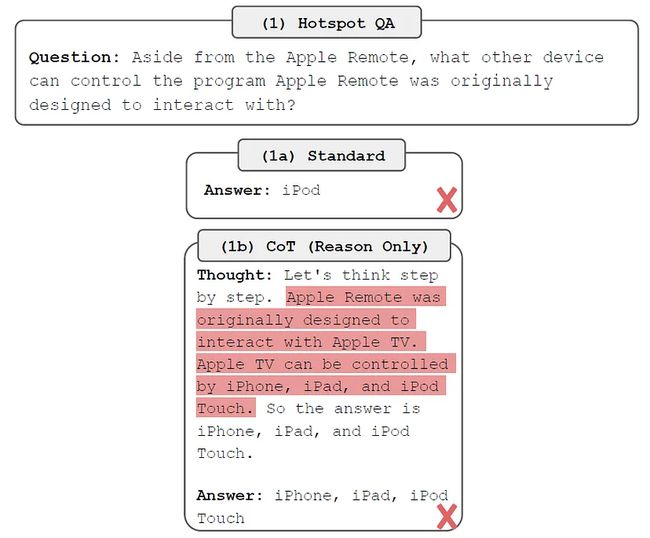
Yao et al. (2023)
由于幻觉的问题,CoT 推理是不可靠的。 如果LLM要成为一个有用的工具,他们就不能左右编造事实,因为那样我们就永远不能相信他们,最好自己做研究。 ReAct 旨在通过允许LLM采取搜索维基百科等行动来解决这个问题,以便从中找到事实和理由。
2、方法
与思维链推理一样,ReAct 是一种提示工程方法,它使用小样本学习来教导模型如何解决问题。 CoT 应该模仿人类思考问题的方式,ReAct 也包含这种推理元素,但它更进一步,允许代理文本操作,使其也与其环境进行交互。
人类使用言语推理(说话或思考)来帮助我们制定策略和记住事情,但我们也可以采取行动来获取更多信息并实现我们的目标。 这是ReAct 的基础。 ReAct 提示包括带有操作的示例、通过采取这些操作获得的观察结果以及人类在该过程中各个步骤中转录的想法(推理策略)。
LLM学习模仿这种交叉思考和行动的方法,使其成为其环境中的代理。 下面是 ReAct 代理如何运行的说明,其中有一个以等宽字体显示的悲惨示例(按想法 -> 行动 -> 观察顺序)。

重要的是要记住,观察结果不是由 LLM 生成的,而是由环境生成的,环境是一个单独的模块,LLM 只能通过特定的文本操作与之交互。 因此,为了实现ReAct,你需要:
- 一个环境,它执行文本操作(从一组可以根据环境的内部状态更改的潜在操作中)并返回文本观察。
- 一个输出解析器框架,一旦代理编写了有效的操作,它就会停止生成文本,在环境中执行该操作,并返回观察结果(将其附加到迄今为止生成的文本并提示LLM)。
- 人类生成的环境中混合思想、行动和观察的示例,用于小样本学习。
示例的数量及其细节由你决定。 ReAct 提示中使用的示例的开头如下所示。

Yao et al. (2023)
在这里,你可以看到想法、行动和观察都被清楚地标记为这样,并且这些行动使用特殊的格式 - 查询在括号中 - 这样代理将学习以这种方式编写它们,然后输出解析器可以 轻松提取查询。
3、结果
对于他们冻结的LLM,yao等人 使用PaLM-540B。 他们使用该LLM在两项知识密集型推理任务和两项决策任务上测试了 ReAct 提示。 我将依次讨论每一个。
3.1 知识密集型推理任务
此任务区域中使用的两个域是 HotPotQA(使用维基百科段落进行多跳问答)和 FEVER(事实验证)。 该代理能够使用以下操作与特意简单的维基百科 API 进行交互:
- 搜索:按名称或最相似结果列表查找页面。
- 查找:在页面中查找字符串。
- 完成:以答案结束任务。
在这些领域中,ReAct 与以下技术进行了比较:
- Standard:提示中不包含思考、行动或观察。
- CoT:提示中不包含行动或观察。
- CoT-SC(自洽):CoT 提示。 对LLM的一定数量的回复进行抽样,并选择大多数作为答案。
- Act:提示中不包含思考。
- ReAct -> CoT-SC:以 ReAct 方式启动,但如果开始不稳定,则切换到 CoT-SC。
- CoT-SC -> ReAct:以 CoT-SC 启动,但如果开始不稳定,则切换到 ReAct。
成功是通过 HotPotQA 中 FEVER 和 EM 的准确性来衡量的。 下图显示了每个域中的结果作为 CoT-SC 采样响应数量的函数。

Yao et al. (2023)
ReAct 在 HotPotQA 中表现不佳,但在 FEVER 中表现优于 CoT。 ReAct 比 CoT 更不容易产生幻觉,但推理错误率更高。 尽管 ReAct 确实有这个缺点,但 ReAct -> CoT-SC 和 CoT-SC -> ReAct 方法是这组方法中最成功的。 下面是本文开头的同一个问题以及 ReAct 的回答,这是正确的。

Yao et al. (2023)
3.2 决策任务
此任务区域中使用的两个域是 ALFWorld 和 WebShop。 我将分别解释每个域。
ALFWorld 是一款具有现实环境的基于文本的游戏。 它具有用于在模拟世界中移动并与之交互的文本操作,例如“打开抽屉 1”。 智能体的目标可能是在房子里找到特定的物体,因此常识推理有助于了解通常会在哪里找到这样的物体。 ReAct 在此领域中比较的基线是:
- Act:提示中不包含思考。
- BUTLER:一种模仿学习方法。
- ReAct-IM(内心独白):只能思考环境以及距离目标有多近。
成功的衡量标准是达到目标的试验的百分比。 ReAct 的表现优于基线。
WebShop 是一个模拟在线购物网站,其数据是从亚马逊爬取的。 这是一个具有挑战性的领域,因为它有大量用于浏览网站和搜索产品的操作。 目标是找到符合用户规格的商品。 ReAct 在此领域中比较的基线是:
- Act:提示中不包含思考。
- IL:一种模仿学习方法。
- IL + RL:一种模仿和强化学习方法。
衡量成功的标准是所选项目与用户想要的隐藏项目的接近程度。 ReAct 的表现优于基线。
4、结束语
ReAct虽然由于其推理错误而本身并不完美,但它仍然是一种强大的提示工程方法,它克服了思想链推理的事实幻觉问题,并且还允许LLM成为可以与其环境交互的代理。 此外,它是一种非常可解释的方法,因为代理在其行动时输出其思维过程。
我相信 ReAct 是迈向通用人工智能 (AGI) 和具体语言模型(像人类一样思考的机器人)的一步。 如果机器人有一种方法可以根据熟悉的特征对外部环境进行建模并使用该模型创建提示,那么它就可以(至少尝试)在多种领域中自行行动,而无需人工制作的示例。 它还需要某种记忆,或者从经验中学习的能力,以使其变得更像人类。 目前尚不清楚 AGI 的创建是否会帮助或伤害人类,但具有常识知识的机器人,只要解决了推理错误和幻觉等错误,可能会对我们有很大帮助(作为消防员, 实例)。
LLM 代理已经商业化,并被用于各种任务,从创建网站到订购披萨。 还有非商业应用,比如毁灭人类。 我只希望这些工具也能发挥作用。 一个以找出如何解决世界问题为目标的智能体可能会很好。