阿里云 -- 测测你的一见钟情
都是使用网格搜索进行调优
这是用神经网络跑的
import os
from sklearn import metrics
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, precision_score, f1_score
from sklearn.model_selection import GridSearchCV, StratifiedKFold
import imblearn as ibl
from sklearn.metrics import make_scorer, recall_score
from sklearn.metrics import accuracy_score
os.chdir(r'D:\文件项目\测测你的一见钟情指数')
data = pd.read_csv('speed_dating_train.csv', encoding='gbk')
dating_test = pd.read_csv('speed_dating_test.csv', encoding='gbk')
#删除缺失值大于80的
missing_percent = data.isnull().sum() * 100 / len(data)
missing_columns = missing_percent[missing_percent > 80].index
data.drop(columns=missing_columns, inplace=True)
# 使用众数填充缺失值
mode_values = data.mode().iloc[0]
data= data.fillna(mode_values)
missing_percent = data.isnull().sum() * 100 / len(data)
print(missing_percent.sort_values())
# 第一张图:通过该活动成功脱单的人
plt.subplot(1, 2, 1)
groupSize_matched = data.match.value_counts().values
signs = ['Single:' + str(round(groupSize_matched[0] * 100 / sum(groupSize_matched), 2)) + '%', 'Matched:' + str(round
(groupSize_matched[1] * 100 /sum(groupSize_matched), 2)) + '%']
plt.pie(groupSize_matched, labels = signs)
# 第二张图:女生中成功脱单的人与男生中成功脱单的人
plt.subplot(1, 2, 2)
groupSize_genderMatched = data[data.match == 1].gender.value_counts().values
maleMatchedPercent = groupSize_genderMatched[0] * 100 / sum(groupSize_genderMatched)
femaleMatchedPercent = groupSize_genderMatched[1] * 100 / sum(groupSize_genderMatched)
signs = ['Male:' + str(round(maleMatchedPercent, 2)) + '%', 'Female:' + str(round(femaleMatchedPercent, 2)) + '%']
plt.pie(groupSize_genderMatched, labels = signs)
# plt.savefig('Figure0.png')
plt.show()
plt.subplot(1, 1, 1)
# 参加该活动的人的年龄分布情况
age = data[np.isfinite(data['age'])]['age']
plt.hist(age, bins = 35)
plt.xlabel('Age')
plt.ylabel('Frequency')
# plt.savefig('Figure1.png')
plt.show()
date_data = data[['gender', 'condtn', 'round', 'position', 'match', 'int_corr', 'samerace', 'age_o', 'race_o',
'pf_o_att', 'dec_o', 'field_cd', 'mn_sat', 'tuition', 'race', 'imprace', 'zipcode', 'income',
'goal', 'career_c', 'sports', 'tvsports', 'exercise', 'dining', 'art', 'hiking', 'gaming', 'clubbing',
'reading', 'tv', 'theater', 'movies', 'concerts', 'music', 'shopping', 'yoga', 'exphappy',
'expnum', 'attr1_1', 'sinc1_1', 'intel1_1', 'fun1_1', 'amb1_1', 'shar1_1', 'attr2_1', 'sinc2_1',
'fun2_1', 'shar2_1', 'attr3_1', 'sinc3_1', 'intel3_1', 'fun3_1', 'amb3_1', 'attr4_1', 'sinc4_1',
'intel4_1', 'fun4_1', 'amb4_1', 'shar4_1', 'attr5_1', 'sinc5_1','intel5_1', 'fun5_1', 'amb5_1']]
plt.subplots(figsize = (25, 20))
corr = date_data.corr()
sb.heatmap(corr, xticklabels = corr.columns.values, yticklabels = corr.columns.values)
# plt.savefig('Heatmap.png')
plt.show()
# 构建模型,使用神经网络
choice=data[['attr', 'sinc', 'intel', 'fun', 'amb', 'shar', 'like', 'prob', 'met', 'attr_o', 'sinc_o', 'intel_o',
'fun_o', 'amb_o', 'shar_o', 'like_o', 'prob_o', 'met_o','attr1_3', 'sinc1_3', 'intel1_3', 'fun1_3', 'amb1_3', 'shar1_3', 'attr7_3', 'sinc7_3', 'intel7_3',
'fun7_3', 'amb7_3', 'shar7_3', 'attr4_3', 'sinc4_3', 'intel4_3', 'fun4_3', 'amb4_3', 'shar4_3',
'attr2_3', 'sinc2_3', 'intel2_3', 'fun2_3', 'amb2_3', 'shar2_3', 'attr3_3', 'sinc3_3', 'intel3_3',
'fun3_3', 'amb3_3', 'attr5_3', 'sinc5_3', 'intel5_3', 'fun5_3', 'amb5_3','match','numdat_2'
]]
x = choice.drop(columns=['match'])
y = choice['match']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
定义参数空间
hidden_layers_sizes=[(256, 512, 512, 256)]
activations=["logistic","tanh", "relu","identity"]
solvers=["adam", "sgd"]
alphas=[0.0001, 0.001]
learning_rates=["constant", "adaptive"]
max_score = 0
max_score2=0
max_score3=0
max_score4=0
best_params= {}
best_params2={}
best_params3={}
best_params4={}
for solver in solvers:
for activation in activations:
for alpha in alphas:
for learning_rate in learning_rates:
for hidden_layer_sizes in hidden_layers_sizes:
# 创建MLPClassifier模型
model = MLPClassifier(solver=solver, activation=activation, alpha=alpha,learning_rate=learning_rate,hidden_layer_sizes=hidden_layer_sizes)
# 训练模型
model.fit(x_train, y_train)
# 在验证集上进行预测
y_pred = model.predict(x_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
precision = precision_score(y_test, y_pred,zero_division=1)
f1 = f1_score(y_test, y_pred)
print("solver:", solver, ",activation:", activation, ",alpha:", alpha, ",learning_rate:", learning_rate,",hidden_layer_sizes:", hidden_layer_sizes,",accuracy:", accuracy,",recall:",recall,",precision:",precision,",f1_score:",f1)
# 更新最佳参数组合
if accuracy > max_score :
max_score = accuracy
best_params['solver'] = solver
best_params['activation'] = activation
best_params['alpha']=alpha
best_params['learning_rate'] = learning_rate
best_params['hidden_layer_sizes'] = hidden_layer_sizes
if recall > max_score2 :
max_score2 = recall
best_params2['solver'] = solver
best_params2['activation'] = activation
best_params2['alpha'] = alpha
best_params2['learning_rate'] = learning_rate
best_params2['hidden_layer_sizes'] = hidden_layer_sizes
if precision > max_score3 :
max_score3 = precision
best_params3['solver'] = solver
best_params3['activation'] = activation
best_params3['alpha'] = alpha
best_params3['learning_rate'] = learning_rate
best_params3['hidden_layer_sizes'] = hidden_layer_sizes
if f1 > max_score4 :
max_score4 = f1
best_params4['solver'] = solver
best_params4['activation'] = activation
best_params4['alpha'] = alpha
best_params4['learning_rate'] = learning_rate
best_params4['hidden_layer_sizes'] = hidden_layer_sizes
# 输出最佳参数组合和评分
print("accuracy最佳参数组合:", best_params)
print("最佳得分:", max_score)
print("recall最佳参数组合:", best_params2)
print("最佳得分:", max_score2)
print("accuracy最佳参数组合:{'solver': 'sgd', 'activation': 'relu', 'alpha': 0.0001, 'learning_rate': 'adaptive', ‘hidden_layer_sizes': (256,512,512,256)}")
print("最佳得分: 0.8774154589371981")
print("recall最佳参数组合:{'solver': 'sgd', 'activation': 'tanh', 'alpha':0.0001, 'learning_rate': 'adaptive', 'hidden_layer_sizes': (256,512,512,256)}")
print("最佳得分: 0.7551867219917012")
print("precision最佳参数组合: {'solver': 'sgd', 'activation': 'logistic', 'alpha': 0.0001, 'learning_rate': 'constant', 'hidden_layer_sizes': (256,512,512,256)}")
print("最佳得分: 0.7479862450156121")
print("最佳参数组合f1_score: {'solver': 'sgd', 'activation': 'identity', 'alpha':0.001, 'Learning_rate': 'constant', 'hidden_layer_sizes': (256,512,512,256)}")
print("最佳得分: 0.5061946902654867")
acc_per = 0
y_test = np.array(y_test)
for i in range(len(y_test)):
if y_test[i][0] == predict[i]:
acc_per += 1
acc_per = acc_per * 100 / len(y_test)
print('预测准确率:%d%%'%acc_per)
使用训练出来的模型进行预测
# 读取预测数据集
pred_data = pd.read_csv('/Users/liuyuanxi/学习/华为智能基座/huawei-smart-base-learning/一见钟情指数/数据集/speed_dating_test.csv'
, encoding = 'UTF-8')
print('预测集数据:', pred_data)
choice_pred_data = pred_data[['age_o', 'gender', 'attr_o', 'intel_o', 'fun_o', 'amb_o', 'shar_o', 'sinc_o',
'uid', 'music', 'sports', 'goal', 'race_o', 'position']]
# 处理缺失值
# choice_pred_data.dropna(inplace = True)
choice_pred_data = choice_pred_data.fillna(axis = 1, method = 'ffill')
x_pred = choice_pred_data[['age_o', 'gender', 'attr_o', 'intel_o', 'fun_o', 'amb_o', 'shar_o', 'sinc_o', 'music'
, 'sports', 'goal', 'race_o', 'position']]
y_pred = model.predict(x_pred)
print('预测结果:\n', y_pred)
# 将预测结果写入 CSV 文件
predict_result = pd.DataFrame({'uid': choice_pred_data['uid'], 'match': y_pred}, dtype = int)
predict_result.to_csv('predict_result.csv', index = False, sep = ',')
项目难点分析
1,赛题所提供的数据集是csv表格,存有当时相亲实验的志愿者的各种信息。这些信息有的是数字,有的是字符串,而且有大量字段缺失。因此需要首先对数据集进行一些处理,使其适用于机器学习。
2. 特征选择:数据集中可能包含大量的特征,但并非所有特征都对相亲成功与否有实质性影响。选择合适的特征对模型的准确性至关重要。难点在于如何进行有效的特征选择,避免过度拟合或者选择无关紧要的特征。
3. 类别不平衡:在“match”字段中,成功和不成功的样本分布可能存在不均衡。这可能导致模型倾向于预测样本数量较多的类别,而忽略数量较少的类别,从而影响模型的泛化能力。
4. 特征之间的复杂关系:特征之间可能存在复杂的非线性关系,例如交叉影响、多重共线性等。部分算法可能难以捕捉到这些复杂关系,导致预测性能下降。
5. 超参数调优:对于DecisionTree和ExtraTreesClassifier这样的基于树的算法,需要对树的深度、
叶子节点数等超参数进行调优。过度调优或不当的调优可能导致模型在训练集上表现良好,
但在测试集上泛化能力不佳。
6. 模型解释:LogisticRegression相对于决策树算法而言更容易解释,
但对于DecisionTree和ExtraTreesClassifier这样的基于树的模型,其预测结果可能难以解释,尤其是
在特征较多或者存在交叉影响的情况下。克服这些难点需要进行仔细的数据预处理、特征工程和
模型评估。同时,合理地选择算法、进行交叉验证、调整超参数以及采用集成学习等方法也可以
提高模型的性能和鲁棒性。
因为是一个二分类问题 ,核心就是从各项数据维度判别match值为0或1 故我们采用逻辑回归,还有决策树的两种方法
以下是实现模型都具有的评价指标的:
准确率:
准确率(Accuracy)是指分类模型预测正确的样本数占总样本数的比例。它可以用以下公式表示:
准确率 = (TP + TN) / (TP + TN + FP + FN)
召回率:
召回率(Recall),也称为敏感性(Sensitivity)或真正类率(True Positive Rate,TPR),是指分类模型正确预测为正类的样本数占实际正类样本数的比例。它可以用以下公式表示:
召回率 = TP / (TP + FN)
精确率:
精确率(Precision)是指分类模型正确预测为正类的样本数占预测为正类的样本数的比例。它可以用以下公式表示:
精确率 = TP / (TP + FP)
F1值:
F1值是综合考虑了精确率和召回率的指标,它可以用以下公式表示:
F1值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
这些指标在机器学习和数据分析中常用于评估模型的性能和准确度。
以下是逻辑回归模型后期添加的评价指标:
均方误差:
均方误差(Mean Squared Error,MSE)是用来衡量回归模型预测结果与真实值之间差距的指标。它可以用以下公式表示:
MSE = (1/n) * Σ(y - ŷ)^2
其中,y 是真实值,ŷ 是模型预测值,n 是样本数量。
均方根误差:
均方根误差(Root Mean Square Error,RMSE)是用来衡量回归模型预测结果与真实值之间差距的指标,它是均方误差(MSE)的平方根。均方根误差常用于评估连续型变量的预测准确度。
均方根误差可以用以下公式表示:
RMSE = sqrt((1/n) * Σ(y - ŷ)^2)
其中,y 是真实值,ŷ 是模型预测值,n 是样本数量。
RMSE 的计算过程包括以下步骤:
1. 计算每个样本的预测值与真实值之差的平方。
2. 将所有样本的平方差累加求和。
3. 对总和除以样本数量 n。
4. 取结果的平方根。
RMSE 的值越小,表示模型的预测准确度越高。与均方误差相比,RMSE 的值更直观,因为它与原始数据具有相同的单位。
ROC曲线
ROC(Receiver Operating Characteristic)曲线是用于评估二分类模型性能的一种常用工具。ROC曲线描述了在不同分类阈值下,真正类率(True Positive Rate,TPR,也称为召回率)与假正类率(False Positive Rate,FPR)之间的关系。
决策树还有交叉验证率
交叉验证率
因为逻辑回归预测精确率低,而准确率高,造成假阳性现象。
假阳性现象指的是,在二分类问题中,模型将实际上属于负类的样本预测为正类的现象。换句话说,模型错误地将负类样本预测为正类。这通常是由于模型对训练集过拟合或者样本不平衡等原因造成的。在实际应用中,假阳性现象可能会导致误诊、误判和决策失误等问题,因此需要针对具体情况采取相应的措施,比如调整模型参数、增加样本量、使用更好的特征等。因为数据集中match值的负值比例较高,所以造成假阳性现象,逻辑回归采用欠采样,随机删除0.5~0.7的match负值,但是最后实现效果不是很好,精确率仅仅提升2~4%
其次,我们还尝试过自适应的随机搜索算法,在逻辑回归模型上进行实验,发现效果大同小异,故没有在其他模型上进行实验:
自适应的随机搜索算法是一种优化算法,用于在搜索空间中找到最优解或接近最优解的解。它结合了随机性和自适应性,能够在搜索过程中灵活地调整搜索策略。
自适应的随机搜索算法的基本思想是通过随机生成一系列解,并根据每个解的评估结果来调整产生下一个解的方式。算法会根据当前搜索进展情况自适应地调整生成解的方式,以更有可能地探索到最优解所在的区域。
自适应的随机搜索算法的优点在于它能够在搜索过程中根据当前情况进行自适应调整,从而更有效地探索搜索空间。它灵活性强,能够适应不同的问题和搜索空间。然而,由于其随机性质,算法的收敛性和全局最优性无法保证,可能会陷入局部最优解。因此,在使用自适应的随机搜索算法时,需要合理设置算法参数,并结合其他优化方法进行综合应用,以提高搜索效果和结果质量。
还尝试过使用方差选择的特征提取方式,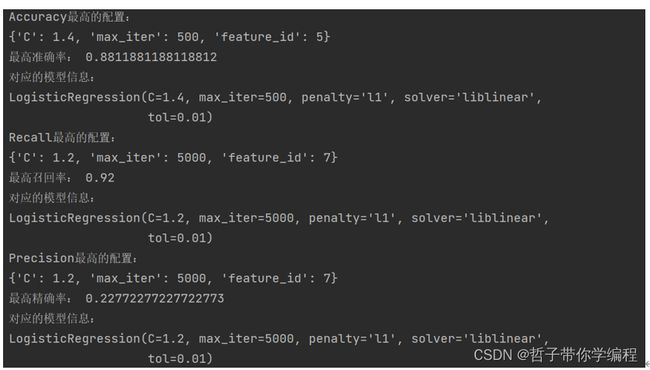

模型指标运行展示:
逻辑回归


决策树
随机森林

对比分析: 逻辑回归的精确率偏低,因为数据集中match的负值比例太高,造成假阳性现象,
采用欠采样,随机删除0.5~0.7的
数据样本,效果仅仅提升精确率1~3%,故逻辑回归采用了多种评价指标
例如ROC曲线等。
采用其他模型决策树和随机森林,效果很好,精确率提升很大,分别为决策树89.73%,
随机森林尤其效果好,达到100%。
决策树的召回率88.11%和f1值86.68%效果好,而随机森林的召回率低,仅为28%,
f1仅为43.75。这说明了不同模型处理的效果各有偏重。
逻辑回归代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
# 载入数据
def load_data():
data_train_frame = pd.read_csv("../../data/speed_dating_train.csv")
data_test_frame = pd.read_csv("../../data/speed_dating_test.csv")
return data_train_frame, data_test_frame
# 语义无关列的清除
def get_irrelevant_data():
return ['dec_o', 'dec', 'iid', 'id', 'gender', 'idg',
'condtn', 'wave', 'round', 'position', 'positin1',
'order', 'partner', 'pid', 'field', 'tuition', 'career','undergra','from',]
# 数据集中清除无关特征
def remove_irrelevant_data(data):
irrelevant_data = get_irrelevant_data()
data = data.drop(irrelevant_data, axis=1)
return data
# ground truth
def get_ground_truth(data):
"""
描述:get ground truth for the data
:param data: 全局参数,测试数据
:return: 测试数据
"""
data['match'] = (data['dec'].astype("bool") & data['dec_o'].astype("bool"))
return data
# 处理缺省值-数据清洗
def handle_missing(data, percent):
percent_missing = data.isnull().sum() / len(data)
missing_df = pd.DataFrame({'column_name': data.columns, 'percent_missing': percent_missing})
missing_show = missing_df.sort_values(by='percent_missing')
print(missing_show[missing_show['percent_missing'] > 0].count())
print('----------------------------------')
print(missing_show[missing_show['percent_missing'] > percent])
columns = missing_show.index[missing_show['percent_missing'] > percent]
data = data.drop(columns=columns, axis=1)
return data
# 特征列选取
def select_data(data, columns):
data = data[columns]
return data
# 补全样本缺失值
def fill_loss_data(data):
data = data.copy(deep=False)
for column in data.columns:
data[column].fillna(data[column].mode()[0], inplace=True)
return data
# 分析特征相关性
def display_corr(data):
plt.subplots(figsize=(20, 15))
axis = plt.axes()
axis.set_title("Correlation HeatMap")
corr = data.corr(method="spearman")
columns_save = []
for index in corr['match'].index.values:
if abs(corr['match'][index]) >= 0.1:
columns_save.append(index)
data = data[columns_save]
corr = data.corr(method='spearman')
sns.heatmap(corr, xticklabels=corr.columns.values, annot=True)
plt.show()
def remove_feature(features, base_feature):
'''
描述:从一群特征中去除某些特征(比如取消所有sinc/attr这种)
参数:特征列表,你要去除的
返回:新的特征列表
'''
new_features = []
for string in features:
if re.match(base_feature, string) == None:
new_features.append(string)
return new_features
# 特征分组
def corr_feature(feature_id):
# 保留相关系数0.15以上
# 定义特征组合
group_0 = ['match']
group_1 = ['attr', 'sinc', 'intel', 'fun', 'amb', 'shar', 'like', 'prob', 'met', 'attr_o', 'sinc_o', 'intel_o',
'fun_o', 'amb_o', 'shar_o', 'like_o', 'prob_o', 'met_o']
group_2 = ['satis_2', 'attr7_2', 'sinc7_2', 'intel7_2', 'fun7_2', 'amb7_2', 'shar7_2', 'attr1_1', 'sinc1_1',
'intel1_1', 'fun1_1', 'amb1_1', 'shar1_1', 'attr4_1', 'sinc4_1', 'intel4_1', 'fun4_1', 'amb4_1',
'shar4_1', \
'attr2_1', 'sinc2_1', 'intel2_1', 'fun2_1', 'amb2_1', 'shar2_1', 'attr3_1', 'sinc3_1', 'fun3_1',
'intel3_1', 'amb3_1', 'attr5_1', 'sinc5_1', 'intel5_1', 'fun5_1', 'amb5_1']
group_3 = ['attr1_3', 'sinc1_3', 'intel1_3', 'fun1_3', 'amb1_3', 'shar1_3', 'attr7_3', 'sinc7_3', 'intel7_3',
'fun7_3', 'amb7_3', 'shar7_3', 'attr4_3', 'sinc4_3', 'intel4_3', 'fun4_3', 'amb4_3', 'shar4_3', \
'attr2_3', 'sinc2_3', 'intel2_3', 'fun2_3', 'amb2_3', 'shar2_3', 'attr3_3', 'sinc3_3', 'intel3_3',
'fun3_3', 'amb3_3', 'attr5_3', 'sinc5_3', 'intel5_3', 'fun5_3', 'amb5_3']
if feature_id == 1:
# 采用group 0+1
columns = group_0 + group_1
elif feature_id == 2:
# 采用group 0+2
columns = group_0 + group_2
elif feature_id == 3:
# 采用group 0+3
columns = group_0 + group_3
elif feature_id == 4:
# 采用group 0+1+2
columns = group_0 + group_1 + group_2
elif feature_id == 5:
# 采用group 0+1+3
columns = group_0 + group_1 + group_3
elif feature_id == 6:
# 采用group 0+2+3
columns = group_0 + group_2 + group_3
elif feature_id == 7:
# 采用group 0+1+2+3
columns = group_0 + group_1 + group_2 + group_3
elif feature_id == 8:
# 采用group 0+1, 去掉attr
new_group_1 = remove_feature(group_1, 'attr')
columns = group_0 + new_group_1
elif feature_id == 9:
# 采用group 0+1, 去掉sinc
new_group_1 = remove_feature(group_1, 'sinc')
columns = group_0 + new_group_1
elif feature_id == 10:
# 采用group 0+1, 去掉intel
new_group_1 = remove_feature(group_1, 'intel')
columns = group_0 + new_group_1
elif feature_id == 11:
# 采用group 0+1, 去掉fun
new_group_1 = remove_feature(group_1, 'fun')
columns = group_0 + new_group_1
elif feature_id == 12:
# 采用group 0+1, 去掉amb
new_group_1 = remove_feature(group_1, 'amb')
columns = group_0 + new_group_1
elif feature_id == 13:
# 采用group 0+1, 去掉shar
new_group_1 = remove_feature(group_1, 'shar')
columns = group_0 + new_group_1
return columns
if __name__ == '__main__':
train_data, test_data = load_data()
print(train_data.columns)
train_data = handle_missing(train_data, 0.7)
train_data = remove_irrelevant_data(train_data)
train_data = fill_loss_data(train_data)
# display_corr(data=train_data)
from sklearn.tree import DecisionTreeRegressor
from data_process import *
from sklearn.linear_model import LogisticRegression
from numpy import ravel
from sklearn.metrics import recall_score, mean_squared_error
import math
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
import random
from sklearn.model_selection import cross_val_score
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# init data
def init_data(train_data, test_data, feature_id):
columns = corr_feature(feature_id=feature_id)
train_data = select_data(train_data, columns)
test_data = select_data(test_data, columns)
train_data = fill_loss_data(train_data)
test_data = fill_loss_data(test_data)
# 欠采样:随机删除一部分match为0的负样本
#negative_samples = train_data[train_data['match'] == 0]
#positive_samples = train_data[train_data['match'] == 1]
#negative_samples = negative_samples.sample(frac=0.7) # 删除50%的负样本
#train_data = pd.concat([positive_samples, negative_samples])
x_train = train_data.drop(['match'], axis=1)
y_train = train_data[['match']]
x_test = test_data.drop(['match'], axis=1)
y_test = test_data[['match']]
return x_train, y_train, x_test, y_test
# obtain accuracy and recall
def compute_accuracy_recall(sample, data, param):
if len(sample) != len(data):
return 'wrong'
for i in range(0, len(sample) - 1):
if sample[i] > param:
sample[i] = 1
else:
sample[i] = 0
acc_number = 0
true_positive = 0
for i, a in zip(range(0, len(sample) - 1), data.values):
if sample[i] == a:
acc_number += 1
if sample[i] == 1:
true_positive += 1
precision = true_positive / len(sample)
recall = recall_score(data, sample)
accuracy = acc_number / len(sample)
if precision + recall == 0:
f1 = 0
else:
f1 = 2 * (precision * recall) / (precision + recall)
return accuracy, recall, precision, f1
# train model
def train_model(feature_id, train_data, test_data, C, max_iter,cv_scores):
x_train, y_train, x_test, y_test = init_data(train_data, test_data, feature_id)
model = LogisticRegression(penalty='l1', dual=False, tol=0.01, C=C, fit_intercept=True,
intercept_scaling=1, solver='liblinear', max_iter=max_iter)
model.fit(x_train, ravel(y_train))
# 计算训练集准确率和召回率
y_pred_train = model.predict(x_train)
train_accuracy, train_recall, train_precision, train_f1 = compute_accuracy_recall(y_pred_train, y_train, 0.7)
# 计算测试集准确率和召回率
y_pred_test = model.predict(x_test)
test_accuracy, test_recall, test_precision, test_f1 = compute_accuracy_recall(y_pred_test, y_test, 0.7)
cv_scores.append(train_accuracy)
# 计算均方误差
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
# 计算均方根误差
rmse_train = math.sqrt(mse_train)
rmse_test = math.sqrt(mse_test)
# 计算测试集预测概率
y_pred_test_prob = model.predict_proba(x_test)[:, 1]
# 计算FPR、TPR和阈值
fpr, tpr, thresholds = roc_curve(y_test, y_pred_test_prob)
# 计算AUC
roc_auc = auc(fpr, tpr)
print("训练准确率:%.4f" % (train_accuracy * 100))
print("测试准确率:%.4f" % (test_accuracy * 100))
print("训练召回率:%.4f" % (train_recall * 100))
print("测试召回率:%.4f" % (test_recall * 100))
print("训练精确率:%.4f" % (train_precision * 100))
print("测试精确率:%.4f" % (test_precision * 100))
print("训练F1值:%.4f" % train_f1)
print("测试F1值:%.4f" % test_f1)
print("训练均方误差:%.4f" % mse_train)
print("测试均方误差:%.4f" % mse_test)
print("训练均方根误差:%.4f" % rmse_train)
print("测试均方根误差:%.4f" % rmse_test)
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_pred_test)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
#plt.show()
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
rmse_train = math.sqrt(mse_train)
rmse_test = math.sqrt(mse_test)
return model, train_accuracy, test_accuracy, train_recall, test_recall, train_precision, test_precision, train_f1, test_f1, mse_train, mse_test, rmse_train, rmse_test, rmse_train, rmse_test
def grid_search():
train_data, test_data = load_data()
test_data = get_ground_truth(test_data)
Cs = [0.8, 1.0,1.2,1.4,1.6 ]
max_iters = [100, 500,1000,2000,5000]
feature_ids = [i for i in range(1, 14)]
best_acc = 0.0
best_recall = 0.0
best_precision = 0.0
best_f1 = 0.0
best_mse = float('inf')
best_rmse = float('inf')
best_log_acc = {
'C': 0.0,
'max_iter': 0,
'feature_id': 1
}
best_log_recall = {
'C': 0.0,
'max_iter': 0,
'feature_id': 1
}
best_log_f1 = {
'C': 0.0,
'max_iter': 0,
'feature_id': 1
}
best_log_precision = {
'C': 0.0,
'max_iter': 0,
'feature_id': 1
}
best_model_precision = None
best_model_acc = None
best_model_recall = None
best_model_f1 = None
# 定义 x_train 和 y_train
x_train, y_train, _, _ = init_data(train_data, test_data, feature_ids[0])
accuracy_scores = []
for feature_id in feature_ids:
cv_scores = [] # 新增代码
for C in Cs:
for max_iter in max_iters:
print("feature_id:", feature_id, ",C:", C, ",max_iter:", max_iter)
model, train_acc, test_acc, train_recall, test_recall, train_precision, test_precision, train_f1, test_f1, mse_train, mse_test, rmse_train, rmse_test, rmse_train, rmse_test = train_model(
feature_id, train_data, test_data, C, max_iter,cv_scores)
accuracy_scores.append([feature_id, C, max_iter, test_acc])
if best_acc < test_acc:
best_acc = test_acc
best_log_acc['C'] = C
best_log_acc['max_iter'] = max_iter
best_log_acc['feature_id'] = feature_id
best_model_acc = model
if best_recall < test_recall:
best_recall = test_recall
best_log_recall['C'] = C
best_log_recall['max_iter'] = max_iter
best_log_recall['feature_id'] = feature_id
best_model_recall = model
if best_precision < test_precision:
best_precision = test_precision
best_log_precision['C'] = C
best_log_precision['max_iter'] = max_iter
best_log_precision['feature_id'] = feature_id
best_model_precision = model
if best_f1 < test_f1:
best_f1 = test_f1
best_log_f1['C'] = C
best_log_f1['max_iter'] = max_iter
best_log_f1['feature_id'] = feature_id
best_model_f1 = model
if best_mse > mse_test:
best_mse = mse_test
best_rmse = rmse_test
if best_mse > mse_test:
best_mse = mse_test
best_rmse = rmse_test
print("Accuracy最高的配置:")
print(best_log_acc)
print("最高准确率:", best_acc)
print("对应的模型信息:")
print(best_model_acc)
print("交叉验证准确率:", cv_scores) # 新增代码
print("对应的模型信息:")
print(best_model_acc)
print("Recall最高的配置:")
print(best_log_recall)
print("最高召回率:", best_recall)
print("对应的模型信息:")
print(best_model_recall)
print("Precision最高的配置:")
print(best_log_precision)
print("最高精确率:", best_precision)
print("对应的模型信息:")
print(best_model_precision)
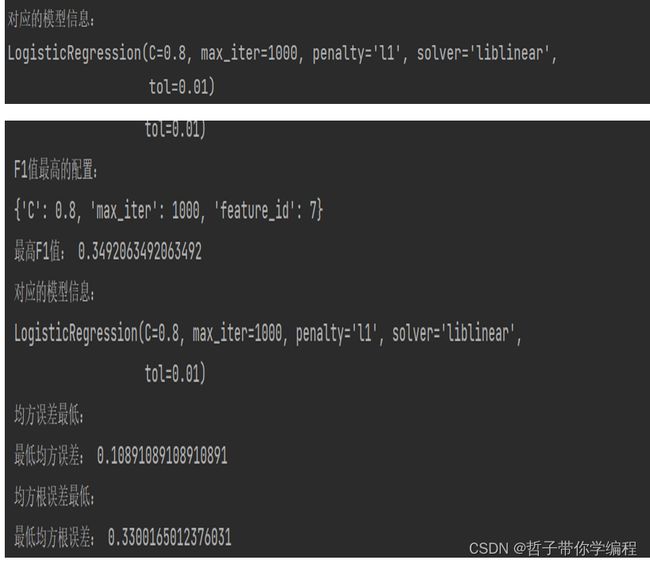
print("F1值最高的配置:")
print(best_log_f1)
print("最高F1值:", best_f1)
print("对应的模型信息:")
print(best_model_f1)
print("均方误差最低:")
print("最低均方误差:", best_mse)
print("均方根误差最低:")
print("最低均方根误差:", best_rmse)
accuracy_scores = np.array(accuracy_scores)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_trisurf(accuracy_scores[:, 0], accuracy_scores[:, 1], accuracy_scores[:, 3], cmap='jet')
ax.set_xlabel('Feature ID')
ax.set_ylabel('C')
ax.set_zlabel('Accuracy')
plt.show()
if __name__ == '__main__':
grid_search()
决策树
from utils import *
import graphviz
def main():
test_data = read_test_data()
data = read_data()
print('---- test data shape ----', test_data.shape)
data, test_data = missing_handle(data, test_data)
data, test_data = do_vectorizer(data, test_data)
data, test_data = feature_select(data, test_data)
print('-------------test data-------------', test_data)
best_params3 = {'criterion': 'gini', 'max_depth': 3, 'splitter': 'random', 'min_samples_split': 16,
'min_samples_leaf': 4, 'min_weight_fraction_leaf': 0, 'random_state': 0, 'min_impurity_decrease': 0}
best_params4 = {'criterion': 'entropy', 'max_depth': 3, 'splitter': 'random', 'min_samples_split': 2,
'min_samples_leaf': 8, 'min_weight_fraction_leaf': 0, 'random_state': 233,
'min_impurity_decrease': 0}
run_model(data, tree.DecisionTreeClassifier(**best_params4))
clf = tree.DecisionTreeClassifier(**best_params4)
calc_validation_accurcy(clf, data.drop(columns=['match']), data['match'], test_data.drop(columns=['match']),
test_data['match'])
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=data.drop(columns=['match']).columns,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.view()
params = {
'criterion': ['entropy'],
'max_depth': [4, 7, 10, 13],
'splitter': ['best', 'random'],
'min_samples_split': [2, 4, 8, 16],
'min_samples_leaf': [1, 2, 4, 8, 16],
'min_weight_fraction_leaf': [0, 0.1, 0.2, 0.3],
'random_state': [0, 233, None],
'min_impurity_decrease': [0, 0.1, 0.2, 0.3],
}
if __name__ == "__main__":
main()
# best: {'criterion': 'entropy', 'max_depth': 7, 'splitter': 'best', 'min_samples_split': 8, 'min_samples_leaf': 16, 'min_weight_fraction_leaf': 0, 'max_features': 8}
import pandas as pd
import sklearn as skl
import sklearn.tree as tree
import numpy as np
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.metrics import precision_score
from sklearn.metrics import precision_score, f1_score
def missing(data: pd.DataFrame):
"""
Report the missing situation.
:param data:
:return:
"""
missing_rate: pd.DataFrame = data.isnull().sum() / len(data)
missing_rate = -(-missing_rate).sort_values()
return missing_rate
def read_test_data():
test_data_file_path_name = "../../data/speed_dating_test.csv"
df = pd.read_csv(test_data_file_path_name)
df = df.drop(columns=['uid'])
y_pre = ((df['dec'] + df['dec_o']) / 2).values
df = pd.concat([df, pd.DataFrame({'match': np.floor(y_pre)})], axis=1)
print('--------------- test data init --------------------', df)
return df
def calc_validation_accurcy(model, X_train, y_train, X_test, y_test):
import time
t0 = time.time()
model.fit(X_train, y_train)
t1 = time.time()
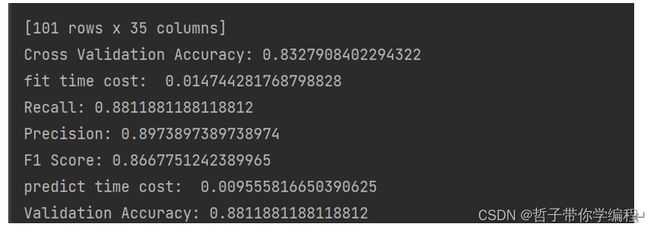
print("fit time cost: ", t1 - t0)
predict_test_lrc = model.predict(X_test)
recall = skl.metrics.recall_score(y_test, predict_test_lrc, average='weighted')
print('Recall:', recall)
precision = precision_score(y_test, predict_test_lrc, average='weighted')
print('Precision:', precision)
f1 = f1_score(y_test, predict_test_lrc, average='weighted')
print('F1 Score:', f1)
t2 = time.time()
print("predict time cost: ", t2 - t1)
validate_accuracy = skl.metrics.accuracy_score(y_test, predict_test_lrc)
print('Validation Accuracy:', validate_accuracy)
def read_data():
"""
:return: Dataframe.
"""
train_data_file_path_name = "../../data/speed_dating_train.csv"
print("\033[0;32mRead Train Data:\033[0m \033[4m{filename}\033[0m".format(filename=train_data_file_path_name))
df = pd.read_csv(train_data_file_path_name)
print("Read finished.")
print("\033[0;32mData Shape:\033[0m ", df.shape)
print("\033[0;32mColumns:\033[0m ", df.columns)
return df
def run_model(df: pd.DataFrame, model, print_result=True) -> (int, int):
x = df.drop(columns=['match'])
y = df['match']
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, x, y, cv=5)
validate_accuracy = sum(scores) / len(scores)
if print_result:
print('Cross Validation Accuracy:', validate_accuracy)
return 0, validate_accuracy
def do_vectorizer(data: pd.DataFrame, test_data: pd.DataFrame):
char_params = [
'goal', 'career_c',
]
data[char_params] = data[char_params].astype('str')
test_data[char_params] = test_data[char_params].astype('str')
print(data[char_params].dtypes)
vec = DictVectorizer(sparse=False)
print('------ vectorizer ------')
print(vec.fit_transform(data.to_dict(orient='records')))
print('------ feature name ------', vec.get_feature_names_out())
data['is_test'] = 0
test_data['is_test'] = 1
data_all = pd.concat([data, test_data], axis=0)
print("--------- data all before vectorizer ----------", data_all)
data_all = pd.DataFrame(vec.fit_transform(data_all.to_dict(orient='records')))
data_all.columns = vec.get_feature_names_out()
data = data_all.loc[data_all['is_test'] == 0]
test_data = data_all.loc[data_all['is_test'] == 1]
print("--------- test data after vectorizer ----------", test_data)
print("--------- data after vectorizer ----------", data)
return data, test_data
def feature_select(data: pd.DataFrame, test_data: pd.DataFrame):
run_model(data, ExtraTreesClassifier())
clf = ExtraTreesClassifier()
from sklearn.feature_selection import SelectFromModel
x = data.drop(columns=['match'])
y = data['match']
clf.fit(x, y)
model = SelectFromModel(clf, prefit=True)
x_new = model.transform(x)
data = pd.concat([pd.DataFrame(x_new), data[['match']]], axis=1)
print('--------- feature params -----------', model.get_params())
test_data_x = test_data.drop(columns=['match'])
test_data_y = np.array(test_data['match'])
test_data_x_new = model.transform(test_data_x)
test_data_y = pd.DataFrame({'match': test_data_y})
print('--------- test data y after feature ---------', test_data_y)
test_data = pd.concat([pd.DataFrame(test_data_x_new), test_data_y], axis=1)
return data, test_data
def missing_handle(data: pd.DataFrame, test_data: pd.DataFrame):
"""
:param data:
:return:
"""
data = data.drop(columns=['career', 'field', 'undergra', 'from', 'mn_sat', 'tuition', 'zipcode', 'income', 'dec', 'dec_o'])
test_data = test_data.drop(columns=['career', 'field', 'undergra', 'from', 'mn_sat', 'tuition', 'zipcode', 'income', 'dec', 'dec_o'])
from sklearn.impute import SimpleImputer
from numpy import nan
imputation_transformer1 = SimpleImputer(missing_values=nan, strategy="constant", fill_value=-1)
data[data.columns] = imputation_transformer1.fit_transform(data[data.columns])
test_data[test_data.columns] = imputation_transformer1.fit_transform(test_data[test_data.columns])
print("\033[0;32mmissing rate before missing handle:\033[0m ", missing(data))
print(data)
data = data.dropna()
test_data = test_data.dropna()
print("\033[0;32mmissing rate after missing handle:\033[0m ", missing(data))
print(data)
return data, test_data
class search_best_params:
max_vc = 0
best_params = {}
case_total = 1
case_finished = 0
def __init__(self, params_dict: dict):
for values in params_dict:
self.case_total *= len(params_dict[values])
self.case_finished = 0
self.params_dict = params_dict
print("----- case total: %d-----" % self.case_total)
def exec(self):
self.case_finished = 0
self.best_params = {}
self.run(params_dict=self.params_dict)
def run(self, params_dict: dict):
iter_ing = False
for key in params_dict:
v = params_dict[key]
if type(v) == list:
for value in v:
new_dict = dict(params_dict)
new_dict[key] = value
self.run(new_dict)
iter_ing = True
break
if not iter_ing:
t_ac, v_ac = run_model(data, tree.DecisionTreeClassifier(**params_dict), print_result=False)
self.case_finished += 1
if v_ac > self.max_vc:
self.max_vc = v_ac
self.best_params = params_dict
if self.case_finished * 1000 // self.case_total != \
(self.case_finished + 1) * 1000 // self.case_total:
print("done: %d/%d, " % (self.case_finished, self.case_total), self.max_vc, self.best_params)
基于Adaboost的集成
'''
数据清洗,
'''
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from utils import *
def load_data(args, the_type):
'''
描述:读取数据
参数:全局参数,类型(train, test两种)
返回:数据dataframe
'''
if the_type == 'train':
place = args.data_place_train
elif the_type == 'test':
place = args.data_place_test
df = pd.read_csv(place, encoding = 'gbk')
return df
def remove_useless_feature(args, data):
'''
描述:移除语义上和结果无关的feature
参数:全局参数,训练数据
返回:移除feature后的训练数据
'''
useless_feature = get_useless_columns()
data = data.drop(useless_feature, axis = 1)
return data
def remove_loss_feature(args, data):
'''
描述:输出并且移除丢失信息太多的feature
参数:全局参数,训练数据
返回:移除feature后的训练数据
'''
percent_missing = data.isnull().sum() / len(data)
missing_value_df = pd.DataFrame({
'percent_missing': percent_missing
})
missing_value_df.sort_values(by = 'percent_missing')
columns_removal = missing_value_df.index[missing_value_df.percent_missing > args.loss_removal_threshold].values
data = data.drop(columns_removal, axis = 1)
if args.test == 1:
print("Ratio of missing values:")
print(missing_value_df)
print('-' * 100)
print("The columns to be removed:")
print(columns_removal)
print('-' * 100)
print("Current data:")
print(data)
return data
def filt_correleation(args, data):
'''
描述:求数据间的相关性,移除和match没啥关系的数据并且绘图
参数:全局参数,数据
返回:清理后的数据
'''
plt.subplots(figsize = (20, 30))
axis= plt.axes()
axis.set_title("Correlation Heatmap")
corr = data.corr(method = 'spearman')
columns_save = []
for index in corr['match'].index.values:
if abs(corr['match'][index]) >= args.corr_removal_threshold:
columns_save.append(index)
data = data[columns_save]
corr = data.corr(method = 'spearman')
if args.test:
print("The columns to be saved:")
print(columns_save)
print("Current data:")
print(data)
sns.heatmap(corr, xticklabels = corr.columns.values, cmap = "Blues")
plt.show()
return data
def get_test_data_ground_truth(args, test_data):
'''
描述:计算出test数据的ground truth
参数:全局参数,测试数据
返回:测试数据
'''
#先求出test data的match
test_data['match'] = (test_data['dec'].astype("bool") & test_data['dec_o'].astype("bool"))
if args.test:
print(test_data)
return test_data
def filt_data(args, data, columns):
'''
描述:提取特征的部分列
参数:全局参数,数据,选取的列
返回:选取的数据
'''
data = data[columns]
if args.test:
print(data)
return data
def filt_test_data(args, train_data, test_data):
'''
描述:根据训练数据处理方式,处理测试数据
参数:全局参数,训练数据,测试数据
返回:测试数据
'''
columns = train_data.columns
test_data = test_data[columns]
if args.test:
print(test_data)
return test_data
def fill_loss_data(args, data):
'''
描述:补全训练数据/测试数据的缺失
参数:全局参数,训练数据
返回:补全后的数据
'''
if args.test:
print("original data:")
print(data)
for column in data.columns:
data[column].fillna(data[column].mode()[0],inplace = True)
if args.test:
print("filled data:")
print(data)
return data
from utils import *
from data import *
import pandas as pd
import time
import re
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import recall_score, precision_score
import matplotlib.pylab as plt
def output_result(args, y_result):
"""
描述:输出结果到csv
参数:全局参数,结果y
返回:无
"""
uid = []
for i in range(len(y_result)):
uid.append(i)
result_df = pd.DataFrame({
'uid': uid,
'match': y_result
})
result_df.to_csv(args.grid_search_place, index=False)
def train_test(args, logger, x_train, y_train, x_test, y_test, n_estimators, max_depth, min_samples_split,
min_samples_leaf, max_features):
"""
训练测试模型
:param args: 全局参数
:param n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features: 超参数们
:return: model, y_result, train_accuracy, test_accuracy, train_time, test_time, test_recall
"""
logger.debug("*" * 100)
if n_estimators is None:
n_estimators = 100
if max_features is None:
max_features = "auto"
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf, max_features=max_features)
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time()
train_time = end_time - start_time
start_time = time.time()
y_result = model.predict(x_test)
end_time = time.time()
test_time = end_time - start_time
train_accuracy = 100 * model.score(x_train, y_train)
test_accuracy = 100 * model.score(x_test, y_test)
test_recall = recall_score(y_test, y_result) * 100
test_precision = precision_score(y_test, y_result) * 100
logger.debug("Train Accuracy: {:.4}%".format(train_accuracy))
logger.debug("Test Accuracy: {:.4}%".format(test_accuracy))
logger.debug("Test Recall: {:.4}%".format(test_recall))
logger.debug("Test Precision: {:.4}%".format(test_precision))
logger.debug("Train Time: {:.4}s".format(train_time))
logger.debug("Test Time: {:.4}s".format(test_time))
return model, y_result, train_accuracy, test_accuracy, train_time, test_time, test_recall, test_precision
def random_forest_classify(args):
"""
训练模型的主函数
:param args: 全局参数
:return: 无
"""
logger = init_logging(args)
best_acc = 0.0
best_dictionary = {'model': None, 'result': None, 'train_accuracy': 0.0,
'test_accuracy': 0.0, 'train_time': 0.0, 'test_time': 0.0,
'n_estimators': -1, 'max_depth': -1, 'min_samples_split': -1,
'min_samples_leaf': -1, "max_features": -1}
# 定义超参数组合
n_estimatorses = [100]
max_depths = [10]
min_samples_splits = [2]
min_samples_leaves = [1]
max_features = ["sqrt"]
# 遍历处理
for n_estimators in n_estimatorses:
for max_depth in max_depths:
for min_samples_split in min_samples_splits:
for min_samples_leaf in min_samples_leaves:
for max_feature in max_features:
x_train, y_train, x_test, y_test = handle_data(args)
model, result, train_accuracy, test_accuracy, train_time, test_time, test_recall, test_precision = train_test(
args, logger, x_train, y_train, x_test, y_test, n_estimators, max_depth,
min_samples_split, min_samples_leaf, max_feature)
if test_accuracy > best_acc:
best_acc = test_accuracy
best_dictionary = update_best_dictionary(model, result, train_accuracy, test_accuracy,
train_time, test_time, test_recall,
test_precision, n_estimators,
max_depth, min_samples_split,
min_samples_leaf, max_feature)
print_best_dictionary(logger, best_dictionary)
output_result(args, best_dictionary['result'])
def update_best_dictionary(model, result, train_accuracy, test_accuracy, train_time, test_time, test_recall,
test_precision, n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features):
"""
更新最优状态
:param model, result, features, train_accuracy, test_accuracy, train_time, test_time: model params
:param n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features: super params
:return: 最优状态
"""
best_dictionary = {'model': model, 'result': result, 'train_accuracy': train_accuracy,
'test_accuracy': test_accuracy, 'train_time': train_time, 'test_time': test_time,
'test_recall': test_recall, 'test_precision': test_precision,
'n_estimators': n_estimators, 'max_depth': max_depth,
'min_samples_split': min_samples_split, 'min_samples_leaf': min_samples_leaf,
"max_features": max_features}
return best_dictionary
def print_best_dictionary(logger, best_dictionary):
"""
描述:打印最佳情况
参数:logger, 最佳情况
返回:无
"""
logger.debug("*" * 100)
logger.debug("The Best Model:")
logger.debug("Train Accuracy: {:.4}%".format(best_dictionary['train_accuracy']))
logger.debug("Test Accuracy: {:.4}%".format(best_dictionary['test_accuracy']))
logger.debug("Test Recall: {:.4}%".format(best_dictionary['test_recall']))
logger.debug("Test Precision: {:.4}%".format(best_dictionary['test_precision']))
logger.debug("Train Time: {:.4}s".format(best_dictionary['train_time']))
logger.debug("Test Time: {:.4}s".format(best_dictionary['test_time']))
logger.debug("Current Hyper Parameters: ")
logger.debug("Random Forest Estimators: " + str(best_dictionary['n_estimators']))
logger.debug("Trees Max Depth: " + str(best_dictionary['max_depth']))
logger.debug("Trees Min Samples Split: " + str(best_dictionary['min_samples_split']))
logger.debug("Trees Min Samples Leaf: " + str(best_dictionary['min_samples_leaf']))
logger.debug("Trees Min Features: " + str(best_dictionary['max_features']))
def remove_feature(features, base_feature):
"""
处理无用数据
:param features: 参数列表
:param base_feature: 需要去除的参数列表
:return: 新的参数列表
"""
new_features = []
for string in features:
if re.match(base_feature, string) is None:
new_features.append(string)
return new_features
def handle_data(args):
"""
处理数据
:param args:
:param train_data:
:param test_data:
:return:
"""
train_data = load_data(args, 'train')
test_data = load_data(args, 'test')
test_data = get_test_data_ground_truth(args, test_data)
train_data = remove_useless_feature(args, train_data)
test_data = remove_useless_feature(args, test_data)
train_data = fill_loss_data(args, train_data)
test_data = fill_loss_data(args, test_data)
x_train = train_data.drop(['match'], axis=1)
y_train = train_data[['match']]
x_test = test_data.drop(['match'], axis=1)
y_test = test_data[['match']]
x_test = x_test.drop(['uid'], axis=1)
return x_train, y_train, x_test, y_test
from utils import *
from data import *
import pandas as pd
import time
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
def handle_data(args, train_data, test_data):
'''
描述:清洗数据
参数:全局参数,训练数据, 测试数据
返回:清洗后的数据x_train, y_train, x_test, y_test
'''
test_data = get_test_data_ground_truth(args, test_data)
train_data = remove_useless_feature(args, train_data)
test_data = remove_useless_feature(args, test_data)
train_data = remove_loss_feature(args, train_data)
train_data = filt_correleation(args, train_data)
train_data = fill_loss_data(args, train_data)
test_data = filt_test_data(args, train_data, test_data)
test_data = fill_loss_data(args, test_data)
x_train = train_data.drop(['match'], axis = 1)
y_train = train_data[['match']]
x_test = test_data.drop(['match'], axis = 1)
y_test = test_data[['match']]
return x_train, y_train, x_test, y_test
def train_test(args, x_train, y_train, x_test, y_test):
'''
描述:训练-测试模型
参数:全局参数,清洗后的数据x_train, y_train, x_test, y_test
返回:模型,结果
'''
model = AdaBoostClassifier(DecisionTreeClassifier(max_depth = args.max_depth, min_samples_split = args.min_samples_split, min_samples_leaf = args.min_samples_leaf),
n_estimators = args.n_estimators, learning_rate = args.learning_rate, random_state = args.seed)
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time()
train_time = end_time - start_time
start_time = time.time()
y_result = model.predict(x_test)
end_time = time.time()
test_time = end_time - start_time
train_accuracy = 100 * model.score(x_train, y_train)
test_accuracy = 100 * model.score(x_test, y_test)
print("Train Accuracy: {:.4}%".format(train_accuracy))
print("Test Accuracy: {:.4}%".format(test_accuracy))
print("Train Time: {:.4}s".format(train_time))
print("Test Time: {:.4}s".format(test_time))
return model, y_result
def output_result(args, y_test, y_result):
'''
描述:输出结果到csv
参数:全局参数,测试y(ground truth),结果y
返回:无
'''
uid = []
for i in range(len(y_test['match'])):
uid.append(i)
ground_truth_df = pd.DataFrame({
'uid': uid,
'match': y_test['match']
})
result_df = pd.DataFrame({
'uid': uid,
'match': y_result
})
ground_truth_df.to_csv(args.ground_truth_place, index = False)
result_df.to_csv(args.result_place, index = False)
if __name__ == '__main__':
args = init_args()
train_data = load_data(args, 'train')
test_data = load_data(args, 'test')
x_train, y_train, x_test, y_test = handle_data(args, train_data, test_data)
model, y_result = train_test(args, x_train, y_train, x_test, y_test)
output_result(args, y_test, y_result)
'''
常用的函数集合
'''
import argparse
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import logging
def init_args():
'''
描述:初始化全局参数
参数:无
返回:全局参数args
'''
parser = argparse.ArgumentParser(description = "Arguments of the project.")
#数据读取相关
parser.add_argument("--seed", type = int, default = 1111)
parser.add_argument("--data_dir", type = str, default = os.path.join('..', '..', 'data'), help = "The directory of datas")
parser.add_argument("--data_name_train", type = str, default = 'speed_dating_train.csv', help = "The file name of train data")
parser.add_argument("--data_name_test", type = str, default = 'speed_dating_test.csv', help = "The file name of test data")
parser.add_argument("--data_name_submit", type = str, default = 'sample_submission.csv', help = "The file name of submit data")
parser.add_argument("--result_dir", type = str, default = os.path.join('..', '..', 'result'), help = "The directory of results")
parser.add_argument("--ground_truth_name", type = str, default = 'ground_truth.csv', help = "The file name of ground truth")
parser.add_argument("--result_name", type = str, default = 'result.csv', help = "The file name of result")
parser.add_argument("--grid_search_name", type = str, default = 'grid_search.csv', help = "The file name of result")
parser.add_argument("--log_name", type = str, default = 'log.log', help = "The file name of result")
#是否输出测试结果和显示可视化结果,0否1是
parser.add_argument('--test', type = int, default = 0)
#各种丢弃特征的threshold
parser.add_argument("--loss_removal_threshold", type = float, default = 0.5)
parser.add_argument("--corr_removal_threshold", type = float, default = 0.1)
#算法参数
parser.add_argument("--max_depth", type = int, default = 1)
parser.add_argument("--min_samples_split", type = int, default = 5)
parser.add_argument("--min_samples_leaf", type = int, default = 20)
parser.add_argument("--n_estimators", type = int, default = 200)
parser.add_argument("--learning_rate", type = float, default = 0.5)
#是否复现最优结果
parser.add_argument("--best", type = int, default = 0)
args = parser.parse_args()
#计算得到文件位置
args.data_place_train = os.path.join(args.data_dir, args.data_name_train)
args.data_place_test = os.path.join(args.data_dir, args.data_name_test)
args.data_place_submit = os.path.join(args.data_dir, args.data_name_submit)
args.ground_truth_place = os.path.join(args.result_dir, args.ground_truth_name)
args.result_place = os.path.join(args.result_dir, args.result_name)
args.grid_search_place = os.path.join(args.result_dir, args.grid_search_name)
args.log_place = os.path.join(args.result_dir, args.log_name)
return args
def init_logging(args):
'''
描述:创建logging
参数:全局参数
返回:logger
'''
# 创建Logger
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# 创建Handler
# 终端Handler
consoleHandler = logging.StreamHandler()
consoleHandler.setLevel(logging.DEBUG)
# 文件Handler
fileHandler = logging.FileHandler(args.log_place, mode = 'w', encoding = 'UTF-8')
fileHandler.setLevel(logging.NOTSET)
# Formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
consoleHandler.setFormatter(formatter)
fileHandler.setFormatter(formatter)
# 添加到Logger中
logger.addHandler(consoleHandler)
logger.addHandler(fileHandler)
return logger
def get_useless_columns():
"""
描述:返回没有意义的特征
参数:无
返回:一个数组,没有意义的特征
"""
return ['dec_o', 'dec', 'iid', 'id', 'gender', 'idg', 'condtn', 'wave', 'round', 'position', 'positin1', 'order',
'partner', 'pid', 'field', 'tuition', 'career', 'field', 'from', 'career','undergra']
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from utils import *
def load_data(args, the_type):
"""
读取数据
:param args: 全局参数
:param the_type: 'train' or 'test'
:return: 数据dataframe
"""
if the_type == 'train':
place = args.data_place_train
elif the_type == 'test':
place = args.data_place_test
df = pd.read_csv(place, encoding='gbk')
return df
def remove_useless_feature(args, data):
"""
移除语义上和结果无关的数据特征
:param args: 全局参数
:param data: 原数据
:return: 处理后数据
"""
useless_feature = get_useless_columns()
data = data.drop(useless_feature, axis=1)
return data
def remove_loss_feature(args, data):
"""
移除丢失信息太多的数据特征
:param args: 全局参数
:param data: 原数据
:return: 处理后数据
"""
useless_feature = get_useless_columns()
percent_missing = data.isnull().sum() / len(data)
missing_value_df = pd.DataFrame({
'percent_missing': percent_missing
})
missing_value_df.sort_values(by='percent_missing')
columns_removal = missing_value_df.index[missing_value_df.percent_missing > args.loss_removal_threshold].values
data = data.drop(columns_removal, axis=1)
if args.test == 1:
print("Ratio of missing values:")
print(missing_value_df)
print('-' * 100)
print("The columns to be removed:")
print(columns_removal)
print('-' * 100)
print("Current data:")
print(data)
# 如果"undergra"在数据中,则删除该列
if "undergra" in data.columns:
data = data.drop("undergra", axis=1)
data = data.drop(useless_feature, axis=1)
return data
def fill_loss_data(args, data):
"""
补全数据丢失
:param args:全局参数
:param data: 训练数据
:return: 补全后数据
"""
if args.test:
print("original data:")
print(data)
for column in data.columns:
data[column].fillna(data[column].mode()[0], inplace=True)
if args.test:
print("filled data:")
print(data)
return data
def get_test_data_ground_truth(args, test_data):
"""
描述:计算出test数据的ground truth
参数:全局参数,测试数据
返回:测试数据
"""
# 先求出test data的match
test_data['match'] = (test_data['dec'].astype('int') & test_data['dec_o'].astype('int'))
return test_data
from utils import *
from data import *
import pandas as pd
import time
import re
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
import matplotlib.pylab as plt
from sklearn.metrics import f1_score
def output_result(args, y_result):
"""
描述:输出结果到csv
参数:全局参数,结果y
返回:无
"""
uid = []
for i in range(len(y_result)):
uid.append(i)
result_df = pd.DataFrame({
'uid': uid,
'match': y_result
})
result_df.to_csv(args.grid_search_place, index=False)
def train_test(args, logger, x_train, y_train, x_test, y_test, n_estimators, max_depth, min_samples_split,
min_samples_leaf, max_features):
"""
训练测试模型
:param args: 全局参数
:param n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features: 超参数们
:return: model, y_result, train_accuracy, test_accuracy, train_time, test_time, test_precision
"""
logger.debug("*" * 100)
if n_estimators is None:
n_estimators = 100
if max_features is None:
max_features = "auto"
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf, max_features=max_features)
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time()
train_time = end_time - start_time
start_time = time.time()
y_result = model.predict(x_test)
end_time = time.time()
test_time = end_time - start_time
train_accuracy = 100 * model.score(x_train, y_train)
test_accuracy = 100 * model.score(x_test, y_test)
test_recall = recall_score(y_test, y_result) * 100
test_precision = precision_score(y_test, y_result) * 100
test_f1 = f1_score(y_test, y_result) * 100
logger.debug("Train Accuracy: {:.4}%".format(train_accuracy))
logger.debug("Test Accuracy: {:.4}%".format(test_accuracy))
logger.debug("Test Precision: {:.4}%".format(test_precision))
logger.debug("Test recall: {:.4}%".format(test_recall))
logger.debug("Test f1: {:.4}%".format(test_f1))
logger.debug("Train Time: {:.4}s".format(train_time))
logger.debug("Test Time: {:.4}s".format(test_time))
return model, y_result, train_accuracy, test_accuracy, train_time, test_time, test_precision,test_recall,test_f1
def update_best_dictionary(model, result, train_accuracy, test_accuracy, train_time, test_time, test_recall,test_precision,test_f1,
n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features):
"""
更新最优状态
:param model, result, features, train_accuracy, test_accuracy, train_time, test_time: model params
:param n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features: super params
:return: 最优状态
"""
best_dictionary = {'model': model, 'result': result, 'train_accuracy': train_accuracy,
'test_accuracy': test_accuracy, 'train_time': train_time, 'test_time': test_time,
'test_recall': test_recall,'test_f1': test_f1 , 'test_precision': test_precision, 'n_estimators': n_estimators, 'max_depth': max_depth,
'min_samples_split': min_samples_split, 'min_samples_leaf': min_samples_leaf,
"max_features": max_features}
return best_dictionary
def print_best_dictionary(logger, best_dictionary):
"""
描述:打印最佳情况
参数:logger, 最佳情况
返回:无
"""
logger.debug("*" * 100)
logger.debug("The Best Model:")
logger.debug("Train Accuracy: {:.4}%".format(best_dictionary['train_accuracy']))
logger.debug("Test Accuracy: {:.4}%".format(best_dictionary['test_accuracy']))
logger.debug("Test Precision: {:.4}%".format(best_dictionary['test_precision']))
logger.debug("Test recall: {:.4}%".format(best_dictionary['test_recall']))
#logger.debug("Test f1: {:.4}%".format(best_dictionary['test_f1']))
logger.debug("Test f1: {:.4f}%%".format(best_dictionary['test_f1']))
logger.debug("Train Time: {:.4}s".format(best_dictionary['train_time']))
logger.debug("Test Time: {:.4}s".format(best_dictionary['test_time']))
logger.debug("Current Hyper Parameters: ")
logger.debug("Random Forest Estimators: " + str(best_dictionary['n_estimators']))
logger.debug("Trees Max Depth: " + str(best_dictionary['max_depth']))
logger.debug("Trees Min Samples Split: " + str(best_dictionary['min_samples_split']))
logger.debug("Trees Min Samples Leaf: " + str(best_dictionary['min_samples_leaf']))
logger.debug("Trees Min Features: " + str(best_dictionary['max_features']))
def remove_feature(features, base_feature):
"""
处理无用数据
:param features: 参数列表
:param base_feature: 需要去除的参数列表
:return: 新的参数列表
"""
new_features = []
for string in features:
if re.match(base_feature, string) is None:
new_features.append(string)
return new_features
def handle_data(args):
"""
处理数据
:param args:
:param train_data:
:param test_data:
:return:
"""
train_data = load_data(args, 'train')
test_data = load_data(args, 'test')
test_data = get_test_data_ground_truth(args, test_data)
train_data = remove_useless_feature(args, train_data)
test_data = remove_useless_feature(args, test_data)
train_data = fill_loss_data(args, train_data)
test_data = fill_loss_data(args, test_data)
x_train = train_data.drop(['match'], axis=1)
y_train = train_data[['match']]
x_test = test_data.drop(['match'], axis=1)
y_test = test_data[['match']]
x_test = x_test.drop(['uid'], axis=1)
return x_train, y_train, x_test, y_test
def random_forest_classify(args):
"""
训练模型的主函数
:param args: 全局参数
:return: 无
"""
logger = init_logging(args)
best_acc = 0.0
best_dictionary = {'model': None, 'result': None, 'train_accuracy': 0.0,
'test_accuracy': 0.0, 'train_time': 0.0, 'test_time': 0.0,
'n_estimators': -1, 'max_depth': -1, 'min_samples_split': -1,
'min_samples_leaf': -1, "max_features": -1}
# 定义超参数组合
n_estimatorses = [100]
max_depths = [10]
min_samples_splits = [2]
min_samples_leaves = [1]
max_features = ["sqrt"]
# 遍历处理
for n_estimators in n_estimatorses:
for max_depth in max_depths:
for min_samples_split in min_samples_splits:
for min_samples_leaf in min_samples_leaves:
for max_feature in max_features:
x_train, y_train, x_test, y_test = handle_data(args)
model, result, train_accuracy, test_accuracy, train_time, test_time, test_precision ,test_recall ,test_f1= train_test(
args, logger, x_train, y_train, x_test, y_test, n_estimators, max_depth,
min_samples_split, min_samples_leaf, max_feature)
if test_accuracy > best_acc:
best_acc = test_accuracy
best_dictionary = update_best_dictionary(model, result, train_accuracy, test_accuracy, train_time, test_time, test_recall,test_precision,test_f1,
n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features)
print_best_dictionary(logger, best_dictionary)
output_result(args, best_dictionary['result'])
if __name__ == '__main__':
args = init_args()
random_forest_classify(args)
"""
常用的函数集合
"""
import argparse
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import logging
def init_args():
"""
描述:初始化全局参数
参数:无
返回:全局参数args
"""
parser = argparse.ArgumentParser(description="Arguments of the project.")
# 数据读取相关
parser.add_argument("--seed", type=int, default=1111)
parser.add_argument("--data_dir", type=str, default=os.path.join('..', '..', 'data'), help="The directory of datas")
parser.add_argument("--data_name_train", type=str, default='speed_dating_train.csv',
help="The file name of train data")
parser.add_argument("--data_name_test", type=str, default='speed_dating_test.csv',
help="The file name of test data")
parser.add_argument("--data_name_submit", type=str, default='sample_submission.csv',
help="The file name of submit data")
parser.add_argument("--result_dir", type=str, default=os.path.join('..', '..', 'result'),
help="The directory of results")
parser.add_argument("--ground_truth_name", type=str, default='ground_truth.csv',
help="The file name of ground truth")
parser.add_argument("--result_name", type=str, default='result.csv', help="The file name of result")
parser.add_argument("--grid_search_name", type=str, default='grid_search.csv', help="The file name of result")
parser.add_argument("--log_name", type=str, default='log.log', help="The file name of result")
# 是否输出测试结果和显示可视化结果,0否1是
parser.add_argument('--test', type=int, default=0)
# 各种丢弃特征的threshold
parser.add_argument("--loss_removal_threshold", type=float, default=0.5)
parser.add_argument("--corr_removal_threshold", type=float, default=0.1)
# 算法参数
parser.add_argument("--max_depth", type=int, default=1)
parser.add_argument("--min_samples_split", type=int, default=5)
parser.add_argument("--min_samples_leaf", type=int, default=20)
parser.add_argument("--n_estimators", type=int, default=200)
parser.add_argument("--learning_rate", type=float, default=0.5)
# 是否复现最优结果
parser.add_argument("--best", type=int, default=0)
args = parser.parse_args()
# 计算得到文件位置
args.data_place_train = os.path.join(args.data_dir, args.data_name_train)
args.data_place_test = os.path.join(args.data_dir, args.data_name_test)
args.data_place_submit = os.path.join(args.data_dir, args.data_name_submit)
args.ground_truth_place = os.path.join(args.result_dir, args.ground_truth_name)
args.result_place = os.path.join(args.result_dir, args.result_name)
args.grid_search_place = os.path.join(args.result_dir, args.grid_search_name)
args.log_place = os.path.join(args.result_dir, args.log_name)
return args
def init_logging(args):
"""
描述:创建logging
参数:全局参数
返回:logger
"""
# 创建Logger
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# 创建Handler
# 终端Handler
consoleHandler = logging.StreamHandler()
consoleHandler.setLevel(logging.DEBUG)
# 文件Handler
fileHandler = logging.FileHandler(args.log_place, mode='w', encoding='UTF-8')
fileHandler.setLevel(logging.NOTSET)
# Formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
consoleHandler.setFormatter(formatter)
fileHandler.setFormatter(formatter)
# 添加到Logger中
logger.addHandler(consoleHandler)
logger.addHandler(fileHandler)
return logger
def get_useless_columns():
"""
描述:返回没有意义的特征
参数:无
返回:一个数组,没有意义的特征
"""
return ['dec_o', 'dec', 'iid', 'id', 'gender', 'idg', 'condtn', 'wave', 'round', 'position', 'positin1', 'order',
'partner', 'pid', 'field', 'tuition', 'career', 'field', 'undergra', 'from', 'career', ]