Architecture Lab:Part C【流水线通用原理/Y86-64的流水线实现/实现IIADDQ指令】
目录
任务描述
知识回顾
流水线通用原理
Y86-64流水线实现(PIPE-与PIPE)
开始实验
IIADDQ指令的添加
优化 ncopy.ys
仅用第四章知识,CEP=11.55
8x1展开,CPE=9.35
8x1展开+2x1展开+消除气泡,CPE=8.10
流水线化通过让不同的阶段并行操作,改进了系统的吞吐量性能。
在任意一个给定的时刻,多条指令被不同的阶段处理。在引入这种并行性的过程中,我们必须非常小心,以提供与程序的顺序执行相同的程序级行为。通过重新调整SEQ各个部分的顺序,引入流水线,我们得到SEQ+,接着添加流水线寄存器,创建出 PIPE-流水线。
然后,添加了转发逻辑,加速了将结果从一条指令发送到另一条指令,从而提高了流水线的性能。有几种特殊情况需要额外的流水线控制逻辑来暂停或取消一些流水线阶段。
任务描述
Your task in Part C is to modify ncopy.ys and pipe-full.hcl with the goal of making ncopy.ys
run as fast as possible.
翻译过来就是:
第一步,首先要把 pipe-full.hcl 中加入 iaddq 指令。
第二步,优化 ncopy.ys ,使CEP降到7.5
知识回顾
流水线通用原理

就像下图流水线图上方指明的那样,流水线阶段之间的指令转移是由时钟信号来控制的。每隔120ps, 信号从0上升至1,开始下一组流水线阶段的计算。
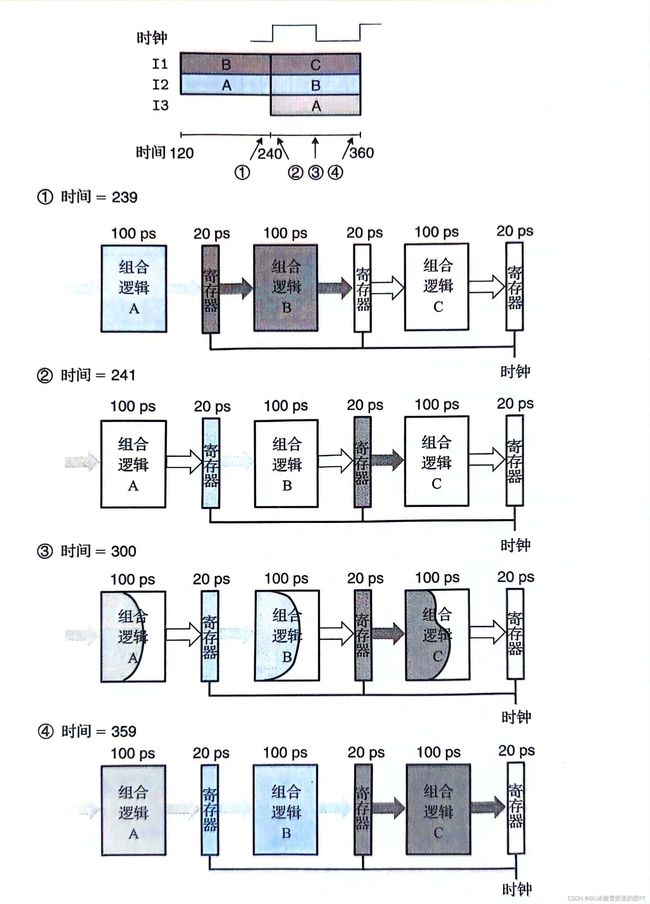
时间=239时,是时钟上升沿到来的前一刻,此时组合逻辑A已经完成了指令I2(蓝色),正在等待寄存器打入脉冲(即时间=240时的上升沿)。同理,组合逻辑B已经完成了指令I1(深灰色),正在等待寄存器打入脉冲(即时间=240时的上升沿)。
时间=241时,是时钟上升沿到来之后,指令I2(蓝色)的结果刚刚打入寄存器。指令I1(深灰色)的结果也刚刚打入寄存器。
时间=300时,是时钟上升沿到来之后,指令I2(蓝色)正在组合逻辑B中进行计算。指令I1(深灰色)正在组合逻辑C中进行计算。新加入的指令I3(浅灰色)正在组合逻辑A中进行计算。
Y86-64流水线实现(PIPE-与PIPE)
首先,对顺序的SEQ处理器做一点小的改动,将 PC的计算挪到第一阶段(取指)。原因:方便流水线源源不断的给出新指令。
然后,在各个阶段之间加上流水线寄存器。
开始实验
IIADDQ指令的添加
IIADDQ指令的添加与Part B一样。唯一要注意的是记得改条件码(set_cc)。
char simname[] = "Y86-64 Processor: pipe-full.hcl";
#include
#include "isa.h"
#include "pipeline.h"
#include "stages.h"
#include "sim.h"
int sim_main(int argc, char *argv[]);
int main(int argc, char *argv[]){return sim_main(argc,argv);}
long long gen_f_pc()
{
return ((((ex_mem_curr->icode) == (I_JMP)) & !(ex_mem_curr->takebranch)
) ? (ex_mem_curr->vala) : ((mem_wb_curr->icode) == (I_RET)) ?
(mem_wb_curr->valm) : (pc_curr->pc));
}
long long gen_f_icode()
{
return ((imem_error) ? (I_NOP) : (imem_icode));
}
long long gen_f_ifun()
{
return ((imem_error) ? (F_NONE) : (imem_ifun));
}
long long gen_instr_valid()
{
return ((if_id_next->icode) == (I_NOP) || (if_id_next->icode) ==
(I_HALT) || (if_id_next->icode) == (I_RRMOVQ) || (if_id_next->icode)
== (I_IRMOVQ) || (if_id_next->icode) == (I_RMMOVQ) ||
(if_id_next->icode) == (I_MRMOVQ) || (if_id_next->icode) == (I_ALU)
|| (if_id_next->icode) == (I_JMP) || (if_id_next->icode) == (I_CALL)
|| (if_id_next->icode) == (I_RET) || (if_id_next->icode) ==
(I_PUSHQ) || (if_id_next->icode) == (I_POPQ) || (if_id_next->icode)
== (I_IADDQ));
}
long long gen_f_stat()
{
return ((imem_error) ? (STAT_ADR) : !(instr_valid) ? (STAT_INS) : (
(if_id_next->icode) == (I_HALT)) ? (STAT_HLT) : (STAT_AOK));
}
long long gen_need_regids()
{
return ((if_id_next->icode) == (I_RRMOVQ) || (if_id_next->icode) ==
(I_ALU) || (if_id_next->icode) == (I_PUSHQ) || (if_id_next->icode)
== (I_POPQ) || (if_id_next->icode) == (I_IRMOVQ) ||
(if_id_next->icode) == (I_RMMOVQ) || (if_id_next->icode) ==
(I_MRMOVQ) || (if_id_next->icode) == (I_IADDQ));
}
long long gen_need_valC()
{
return ((if_id_next->icode) == (I_IRMOVQ) || (if_id_next->icode) ==
(I_RMMOVQ) || (if_id_next->icode) == (I_MRMOVQ) ||
(if_id_next->icode) == (I_JMP) || (if_id_next->icode) == (I_CALL) ||
(if_id_next->icode) == (I_IADDQ));
}
long long gen_f_predPC()
{
return (((if_id_next->icode) == (I_JMP) || (if_id_next->icode) ==
(I_CALL)) ? (if_id_next->valc) : (if_id_next->valp));
}
long long gen_d_srcA()
{
return (((if_id_curr->icode) == (I_RRMOVQ) || (if_id_curr->icode) ==
(I_RMMOVQ) || (if_id_curr->icode) == (I_ALU) || (if_id_curr->icode)
== (I_PUSHQ)) ? (if_id_curr->ra) : ((if_id_curr->icode) ==
(I_POPQ) || (if_id_curr->icode) == (I_RET)) ? (REG_RSP) :
(REG_NONE));
}
long long gen_d_srcB()
{
return (((if_id_curr->icode) == (I_ALU) || (if_id_curr->icode) ==
(I_RMMOVQ) || (if_id_curr->icode) == (I_MRMOVQ) ||
(if_id_curr->icode) == (I_IADDQ)) ? (if_id_curr->rb) : (
(if_id_curr->icode) == (I_PUSHQ) || (if_id_curr->icode) == (I_POPQ)
|| (if_id_curr->icode) == (I_CALL) || (if_id_curr->icode) ==
(I_RET)) ? (REG_RSP) : (REG_NONE));
}
long long gen_d_dstE()
{
return (((if_id_curr->icode) == (I_RRMOVQ) || (if_id_curr->icode) ==
(I_IRMOVQ) || (if_id_curr->icode) == (I_ALU) || (if_id_curr->icode)
== (I_IADDQ)) ? (if_id_curr->rb) : ((if_id_curr->icode) ==
(I_PUSHQ) || (if_id_curr->icode) == (I_POPQ) || (if_id_curr->icode)
== (I_CALL) || (if_id_curr->icode) == (I_RET)) ? (REG_RSP) :
(REG_NONE));
}
long long gen_d_dstM()
{
return (((if_id_curr->icode) == (I_MRMOVQ) || (if_id_curr->icode) ==
(I_POPQ)) ? (if_id_curr->ra) : (REG_NONE));
}
long long gen_d_valA()
{
return (((if_id_curr->icode) == (I_CALL) || (if_id_curr->icode) ==
(I_JMP)) ? (if_id_curr->valp) : ((id_ex_next->srca) ==
(ex_mem_next->deste)) ? (ex_mem_next->vale) : ((id_ex_next->srca)
== (ex_mem_curr->destm)) ? (mem_wb_next->valm) : (
(id_ex_next->srca) == (ex_mem_curr->deste)) ? (ex_mem_curr->vale)
: ((id_ex_next->srca) == (mem_wb_curr->destm)) ? (mem_wb_curr->valm)
: ((id_ex_next->srca) == (mem_wb_curr->deste)) ? (mem_wb_curr->vale)
: (d_regvala));
}
long long gen_d_valB()
{
return (((id_ex_next->srcb) == (ex_mem_next->deste)) ?
(ex_mem_next->vale) : ((id_ex_next->srcb) == (ex_mem_curr->destm)) ?
(mem_wb_next->valm) : ((id_ex_next->srcb) == (ex_mem_curr->deste)) ?
(ex_mem_curr->vale) : ((id_ex_next->srcb) == (mem_wb_curr->destm)) ?
(mem_wb_curr->valm) : ((id_ex_next->srcb) == (mem_wb_curr->deste)) ?
(mem_wb_curr->vale) : (d_regvalb));
}
long long gen_aluA()
{
return (((id_ex_curr->icode) == (I_RRMOVQ) || (id_ex_curr->icode) ==
(I_ALU)) ? (id_ex_curr->vala) : ((id_ex_curr->icode) == (I_IRMOVQ)
|| (id_ex_curr->icode) == (I_RMMOVQ) || (id_ex_curr->icode) ==
(I_MRMOVQ) || (id_ex_curr->icode) == (I_IADDQ)) ?
(id_ex_curr->valc) : ((id_ex_curr->icode) == (I_CALL) ||
(id_ex_curr->icode) == (I_PUSHQ)) ? -8 : ((id_ex_curr->icode) ==
(I_RET) || (id_ex_curr->icode) == (I_POPQ)) ? 8 : 0);
}
long long gen_aluB()
{
return (((id_ex_curr->icode) == (I_RMMOVQ) || (id_ex_curr->icode) ==
(I_MRMOVQ) || (id_ex_curr->icode) == (I_ALU) || (id_ex_curr->icode)
== (I_CALL) || (id_ex_curr->icode) == (I_PUSHQ) ||
(id_ex_curr->icode) == (I_RET) || (id_ex_curr->icode) == (I_POPQ)
|| (id_ex_curr->icode) == (I_IADDQ)) ? (id_ex_curr->valb) : (
(id_ex_curr->icode) == (I_RRMOVQ) || (id_ex_curr->icode) ==
(I_IRMOVQ)) ? 0 : 0);
}
long long gen_alufun()
{
return (((id_ex_curr->icode) == (I_ALU)) ? (id_ex_curr->ifun) : (A_ADD)
);
}
long long gen_set_cc()
{
return (((((id_ex_curr->icode) == (I_ALU)) & !((mem_wb_next->status)
== (STAT_ADR) || (mem_wb_next->status) == (STAT_INS) ||
(mem_wb_next->status) == (STAT_HLT))) & !((mem_wb_curr->status)
== (STAT_ADR) || (mem_wb_curr->status) == (STAT_INS) ||
(mem_wb_curr->status) == (STAT_HLT))) | ((id_ex_curr->icode) ==
(I_IADDQ)));
}
long long gen_e_valA()
{
return (id_ex_curr->vala);
}
long long gen_e_dstE()
{
return ((((id_ex_curr->icode) == (I_RRMOVQ)) & !
(ex_mem_next->takebranch)) ? (REG_NONE) : (id_ex_curr->deste));
}
long long gen_mem_addr()
{
return (((ex_mem_curr->icode) == (I_RMMOVQ) || (ex_mem_curr->icode) ==
(I_PUSHQ) || (ex_mem_curr->icode) == (I_CALL) ||
(ex_mem_curr->icode) == (I_MRMOVQ)) ? (ex_mem_curr->vale) : (
(ex_mem_curr->icode) == (I_POPQ) || (ex_mem_curr->icode) == (I_RET)
) ? (ex_mem_curr->vala) : 0);
}
long long gen_mem_read()
{
return ((ex_mem_curr->icode) == (I_MRMOVQ) || (ex_mem_curr->icode) ==
(I_POPQ) || (ex_mem_curr->icode) == (I_RET));
}
long long gen_mem_write()
{
return ((ex_mem_curr->icode) == (I_RMMOVQ) || (ex_mem_curr->icode) ==
(I_PUSHQ) || (ex_mem_curr->icode) == (I_CALL));
}
long long gen_m_stat()
{
return ((dmem_error) ? (STAT_ADR) : (ex_mem_curr->status));
}
long long gen_w_dstE()
{
return (mem_wb_curr->deste);
}
long long gen_w_valE()
{
return (mem_wb_curr->vale);
}
long long gen_w_dstM()
{
return (mem_wb_curr->destm);
}
long long gen_w_valM()
{
return (mem_wb_curr->valm);
}
long long gen_Stat()
{
return (((mem_wb_curr->status) == (STAT_BUB)) ? (STAT_AOK) :
(mem_wb_curr->status));
}
long long gen_F_bubble()
{
return 0;
}
long long gen_F_stall()
{
return ((((id_ex_curr->icode) == (I_MRMOVQ) || (id_ex_curr->icode) ==
(I_POPQ)) & ((id_ex_curr->destm) == (id_ex_next->srca) ||
(id_ex_curr->destm) == (id_ex_next->srcb))) | ((I_RET) ==
(if_id_curr->icode) || (I_RET) == (id_ex_curr->icode) || (I_RET)
== (ex_mem_curr->icode)));
}
long long gen_D_stall()
{
return (((id_ex_curr->icode) == (I_MRMOVQ) || (id_ex_curr->icode) ==
(I_POPQ)) & ((id_ex_curr->destm) == (id_ex_next->srca) ||
(id_ex_curr->destm) == (id_ex_next->srcb)));
}
long long gen_D_bubble()
{
return ((((id_ex_curr->icode) == (I_JMP)) & !(ex_mem_next->takebranch))
| (!(((id_ex_curr->icode) == (I_MRMOVQ) || (id_ex_curr->icode) ==
(I_POPQ)) & ((id_ex_curr->destm) == (id_ex_next->srca) ||
(id_ex_curr->destm) == (id_ex_next->srcb))) & ((I_RET) ==
(if_id_curr->icode) || (I_RET) == (id_ex_curr->icode) || (I_RET)
== (ex_mem_curr->icode))));
}
long long gen_E_stall()
{
return 0;
}
long long gen_E_bubble()
{
return ((((id_ex_curr->icode) == (I_JMP)) & !(ex_mem_next->takebranch))
| (((id_ex_curr->icode) == (I_MRMOVQ) || (id_ex_curr->icode) ==
(I_POPQ)) & ((id_ex_curr->destm) == (id_ex_next->srca) ||
(id_ex_curr->destm) == (id_ex_next->srcb))));
}
long long gen_M_stall()
{
return 0;
}
long long gen_M_bubble()
{
return (((mem_wb_next->status) == (STAT_ADR) || (mem_wb_next->status)
== (STAT_INS) || (mem_wb_next->status) == (STAT_HLT)) | (
(mem_wb_curr->status) == (STAT_ADR) || (mem_wb_curr->status) ==
(STAT_INS) || (mem_wb_curr->status) == (STAT_HLT)));
}
long long gen_W_stall()
{
return ((mem_wb_curr->status) == (STAT_ADR) || (mem_wb_curr->status)
== (STAT_INS) || (mem_wb_curr->status) == (STAT_HLT));
}
long long gen_W_bubble()
{
return 0;
}
改完之后,在pipe目录下:
make clean
make VERSION=full
然后测试:
./psim -t ../y86-code/asumi.yo
cd ../ptest; make SIM=../pipe/psim
cd ../ptest; make SIM=../pipe/psim TFLAGS=-i
发现都过了,那么IIADDQ指令就添加对了。接下来优化 ncopy.ys
优化 ncopy.ys
先从ptest目录回到pipe目录,测试一下基准程序:
cd ../pipe
./correctness.pl(测试正确性)
./benchmark.pl(给出得分)
 基准程序,CEP=15.18
基准程序,CEP=15.18
现在进行一些优化。
仅用第四章知识,CEP=11.55
1. 29行移到33行的位置,去掉原本的第33行。(效果:CPE降1)
2. 使用iaddq指令替换所有的addq指令
3. 把25行跳转改为传送?
不行
原因是,原句含义为“如果R[%r10]>0,那么R[%rax]++”。改为“%r11赋值为1,测试%r10,如果≤0,将立即数0传送给%r11,addq %r11,%rax,将r11恢复为立即数1以备下次循环使用”,测试结果是,跳转改为传送,可将CEP降低0.44,但“将r11恢复为立即数1以备下次循环使用”又将CEP提高了1.
4. 第20行,由于跳转策略,所以默认给它Loop(效果:CPE降0.14)
至此,用我们在第四章学到的知识,CEP=11.55,代码如下:
# You can modify this portion
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jg Loop # if so, goto Done:
ret
Loop: mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd1
iaddq $1, %rax
NoAdd1:
iaddq $8, %rdi # src++
iaddq $8, %rsi # dst++
iaddq $-1, %rdx # length--
jg Loop # if so, goto Loop:
然后用第五章的循环展开方法继续优化。
8x1展开,CPE=9.35
# You can modify this portion
xorq %rax,%rax # count = 0;
andq %rdx, %rdx
jg Judge
ret
Judge:
iaddq $-8, %rdx
jge Loop6
iaddq $8, %rdx
Loop1:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd
iaddq $1, %rax
NoAdd:
iaddq $8, %rdi
iaddq $8, %rsi
iaddq $-1, %rdx
jg Loop1
ret
Loop6:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd1
iaddq $1, %rax
NoAdd1:
mrmovq 8(%rdi), %r10 # read val from src...
rmmovq %r10, 8(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd2
iaddq $1, %rax
NoAdd2:
mrmovq 16(%rdi), %r10 # read val from src...
rmmovq %r10, 16(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd3
iaddq $1, %rax
NoAdd3:
mrmovq 24(%rdi), %r10 # read val from src...
rmmovq %r10, 24(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd4
iaddq $1, %rax
NoAdd4:
mrmovq 32(%rdi), %r10 # read val from src...
rmmovq %r10, 32(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd5
iaddq $1, %rax
NoAdd5:
mrmovq 40(%rdi), %r10 # read val from src...
rmmovq %r10, 40(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd6
iaddq $1, %rax
NoAdd6:
mrmovq 48(%rdi), %r10 # read val from src...
rmmovq %r10, 48(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd7
iaddq $1, %rax
NoAdd7:
mrmovq 56(%rdi), %r10 # read val from src...
rmmovq %r10, 56(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd8
iaddq $1, %rax
NoAdd8:
iaddq $64, %rdi
iaddq $64, %rsi
andq %rdx, %rdx
jg Judge
8x1展开+2x1展开+消除气泡,CPE=8.10
# You can modify this portion
#xorq %rax,%rax # count = 0;
andq %rdx, %rdx
jg Judge
ret
Unfold8:
mrmovq (%rdi), %r10 # read val from src...
mrmovq 8(%rdi), %r11 # read val from src...
mrmovq 16(%rdi), %r12 # read val from src...
mrmovq 24(%rdi), %r13 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
rmmovq %r11, 8(%rsi) # ...and store it to dst
rmmovq %r12, 16(%rsi) # ...and store it to dst
rmmovq %r13, 24(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd1
iaddq $1, %rax
NoAdd1:
andq %r11, %r11 # val <= 0?
jle NoAdd2
iaddq $1, %rax
NoAdd2:
andq %r12, %r12 # val <= 0?
jle NoAdd3
iaddq $1, %rax
NoAdd3:
andq %r13, %r13 # val <= 0?
jle NoAdd4
iaddq $1, %rax
NoAdd4:
mrmovq 32(%rdi), %r10 # read val from src...
mrmovq 40(%rdi), %r11 # read val from src...
mrmovq 48(%rdi), %r12 # read val from src...
mrmovq 56(%rdi), %r13 # read val from src...
rmmovq %r10, 32(%rsi) # ...and store it to dst
rmmovq %r11, 40(%rsi) # ...and store it to dst
rmmovq %r12, 48(%rsi) # ...and store it to dst
rmmovq %r13, 56(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle NoAdd5
iaddq $1, %rax
NoAdd5:
andq %r11, %r11 # val <= 0?
jle NoAdd6
iaddq $1, %rax
NoAdd6:
andq %r12, %r12 # val <= 0?
jle NoAdd7
iaddq $1, %rax
NoAdd7:
andq %r13, %r13 # val <= 0?
jle NoAdd8
iaddq $1, %rax
NoAdd8:
iaddq $64, %rdi
iaddq $64, %rsi
andq %rdx, %rdx
jg Judge
ret
Judge:
iaddq $-8, %rdx
jge Unfold8
iaddq $8, %rdx
Judge2:
iaddq $-2, %rdx
jge Unfold2
iaddq $2, %rdx
SingleLoop:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Done
iaddq $1, %rax
ret
Unfold2:
mrmovq (%rdi), %r10 # read val from src...
mrmovq 8(%rdi), %r11 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
rmmovq %r11, 8(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Noadd1
iaddq $1, %rax
Noadd1:
andq %r11, %r11 # val <= 0?
jle Noadd2
iaddq $1, %rax
Noadd2:
iaddq $16, %rdi
iaddq $16, %rsi
andq %rdx, %rdx
jg Judge2

参考
CSAPP | Lab4-Architecture Lab 深入解析 - 知乎 (zhihu.com)
[读书笔记]CSAPP:ArchLab - 知乎 (zhihu.com)