Spark大数据分析与实战笔记(第三章 Spark RDD弹性分布式数据集-01)
文章目录
- 每日一句正能量
- 第3章 Spark RDD弹性分布式数据集
- 章节概要
-
- 3.1 RDD简介
- 3.2 RDD的创建方式
-
- 3.2.1 从文件系统加载数据创建RDD
- 3.2.2 通过并行集合创建RDD
每日一句正能量
学如积薪,后来者居上。
第3章 Spark RDD弹性分布式数据集
章节概要
传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。Spark中的RDD可以很好的解决这一缺点。
RDD是Spark提供的最重要的抽象概念,我们可以将RDD理解为一个分布式存储在集群中的大型数据集合,不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理的速度和性能。接下来,本章将针对RDD进行详细讲解。
3.1 RDD简介
RDD (Resilient Distributed Dataset),即弹性分布式数据集,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并且还能控制数据的分区。对于迭代式计算和交互式数据挖掘,RDD可以将中间计算的数据结果保存在内存中,若是后面需要中间结果参与计算时,则可以直接从内存中读取,从而可以极大地提高计算速度。
每个RDD都具有五大特征,具体如下:
-
分区列表
每个RDD被分为多个分区(Partitions),这些分区运行在集群中的不同节点,每个分区都会被一个计算任务处理,分区数决定了并行计算的数量,创建RDD时可以指定RDD分区的个数。如果不指定分区数量,当RDD从集合创建时,默认分区数量为该程序所分配到的资源的CPU核数(每个Core可以承载2~4个Partition),如果是从HDFS文件创建,默认为文件的 Block数。 -
每个分区都有一个计算函数
Spark的RDD的计算函数是以分片为基本单位的,每个RDD都会实现compute函数,对具体的分片进行计算。 -
依赖于其他RDD
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。 -
(Key,Value)数据类型的RDD分区器
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于(Key,Value)的RDD,才会有Partitioner(分区),非(Key,Value)的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分区数量,也决定了parent RDD Shuffie输出时的分区数量。 -
每个分区都有一个优先位置列表
优先位置列表会存储每个Partition的优先位置,对于一个HDFS文件来说,就是每个Partition块的位置。按照“移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
3.2 RDD的创建方式
Spark提供了两种创建RDD的方式,分别是从文件系统(本地和HDFS)中加载数据创建RDD和通过并行集合创建RDD。
3.2.1 从文件系统加载数据创建RDD
Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。
这里以Linux本地系统和HDFS分布式文件系统为例,讲解如何创建RDD。
- 从Linux本地文件系统加载数据创建RDD
准备工作:
1.在Linux本地文件系统中有一个名为test.txt的文件,如果没有的话,在hadoop01上的/export/data目录下创建test.txt。命令如下:
vi test.txt
2.编辑test.txt,添加以下内容。
1 hadoop spark
2 itcast heima
3 scala spark
4 spark itcast
5 itcast hadoop
在Linux本地系统读取test.txt文件数据创建RDD,具体代码执行如下:
scala> var test = sc.textFile("file:///export/data/test.txt")
test: org.apache.spark.rdd.RDD[ String]=file:///export/data/test.txtMapPartitionsRDD[ 1] at textFile at console>:24
具体步骤如下:
1.首先要进入到spark shell的交互式页面。如下图所示
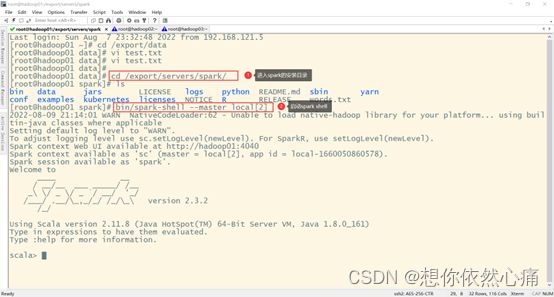
2.在Linux本地系统读取test.txt文件数据创建RDD,如下图所示
![]()
- 从HDFS中加载数据创建RDD
准备工作
假设,在HDFS上的"/data"目录下有一个名为test.txt的文件,该文件内容与上述文件相同。接下来,我们通过加载HDFS中的数据创建RDD,具体代码如下:
scala> val testRDD=sc.textFile("/data/test.txt")
testRDD:org.apache.spark.rdd.RDD[String]=/data/test.txt MapPartitionsRDD[1] at textFile at <console>:24
具体步骤
1.打开hadoop01,右键克隆一个会话。
2.启动hadoop集群。
(1) 进入hadoop目录,命令如下
cd /export/servers/hadoop-2.7.4/etc/hadoop
(2) 在主节点hadoop01上执行以下命令
start-dfs.sh
(3) 在主节点hadoop01上执行以下命令
start-yarn.sh
3.在hadoop 上创建/data目录。命令如下
hadoop fs -mkdir /data
4.将本地的test.txt文件上传到HDFS的data目录下。
cd /export/data/
hadoop fs -put test.txt /data
5.到spark shell的会话中,创建RDD。
scala> val testRDD=sc.textFile("/data/test.txt")
testRDD:org.apache.spark.rdd.RDD[String]=/data/test.txt MapPartitionsRDD[1] at textFile at <console>:24
注意:这里的路径/data/test.txt是简写,完整的路径是:hdfs://主机名:端口/路径。所以说,spark shell 默认解析的路径就是HDFS 的路径。
3.2.2 通过并行集合创建RDD
Spark可以通过并行集合创建RDD。即从一个已经存在的集合、数组上,通过SparkContext对象调用parallelize()方法创建RDD。若要创建RDD,则需要先创建一个数组,再通过执行parallelize()方法实现,具体代码如下:
scala> val array=Array( 1,2,3,4,5)
array : Array [Int]=Array ( 1,2,3,4,5)
scala> val arrRDD=sc.parallelize( array)
arrRDD: org.apache.spark.rdd. RDD[ Int ]=ParallelcollectionRDD[6] at parallelizeat <console> :26
转载自:
欢迎 点赞✍评论⭐收藏,欢迎指正