MySQL存储过程(一)
一、什么是存储过程
存储过程(Stored Procedure),简单地说,存储过程就是数据库中保存(Stored)的一系列SQL命令(Procedure)的集合。也可以将其看作相互之间有关系的 SQL命令组织在一起形成的一个小程序。它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它
优点
(1)高执行性能
通常在客户端执行 SQL 命令时,在数据库中有解析到编译的这个前期准备过程。但是,存储过程是事先完成了解析、编译的处理后保存在数据库中的,执行时能减轻数据库负担,提高执行性能。
(2)可减轻网络负担
使用存储过程后,复杂的数据库操作也可以在数据库服务器中完成。只需要从客户端(或应用程序)传递给数据库必要的参数就行,比起需要多次传递 SOL 命令本身,这大大减轻了网络负担。特别是在应用程序与数据库服务器之间通过网络通信的场合,能够减少相互之间的通信量,大幅度提高整体的性能。
(3)可防止对表的直接访问
可以禁止对表本身的访问,只赋予用户对相关存储过程的访问权限。限制客户端只能通过存储过程才能访问表,可以事前防止对表的一些预想不到的操作。
(4)可将数据库的处理黑匣子化
构建应用程序时,在应用程序中编写对数据库进行的复杂处理,是减低程序可读性的重要原因。
但是,如果将这些处理以存储过程的形式编写,并保存在数据库中,应用程序的处理将会简洁许多。应用程序中完全不用考虑存储过程的内部详细处理,只需要知道调用哪个存储过程就可以了。
二、mysql8.0版的存储过程保存在哪个表?
想查看存储过程的话:show procedure status; (显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等)
想看存储过程代码:show create procedure procedure_name;(显示某一个存储过程的详细信息)
存储过程存放在infomation_schema.ROUTINES表内。
通过关键字符模糊匹配使用到的存储过程:
SELECT a.ROUTINE_SCHEMA,a.ROUTINE_TYPE,a.ROUTINE_NAME FROM information_schema.ROUTINES a where a.ROUTINE_DEFINITION like '%关键字%';三、定义存储过程
创建存储过程使用 CREATE PROCEDURE 命令,具体的语法如下
CREATE PROCEDURE 存储过程名(
参数的种类1 参数1 数据类型 1
[,参数的种类2 参数2 数据类型 2···]
)
BEGIN
处理内容
EnD即将“处理内容”定义为名为[存储过程名]的存储过程。通常在存储过程名前加上[sp_]样的开头,以区别数据库中的其他对象。处理内容必须在 BEGIN 与END 之间编写。
在调用存储过程时可以指定参数。参数是存储过程与调用方进行信息交换的中介。
存储过程的参数可以分为输入参数《接受调用方的数据),输出参数(向调用方返回处理结果)。定义时在具体参数前指定IN OUT INOUT 的其中之一(输入参数时可省略N)由关键字IN、OUT、INOUT决定参数到底是输入参数还是输出参数。INOUT 的参数既是输入型参数,也是输出型参数。

3.1 通过DELIMITER命令改变分隔符
DELIMITER 是改变 MySQL 监视器中使用的 SQL 语分离符的命令。默认的分隔符是[;]。但是,存储过程本身就是命令的集合,其中一定会含有引 [;]。如果保持原来的默认分隔符,那么究竟是CREATE PROCEDURE 命令的结束符,还是存储过程内部 SQL语的结符,MySQL 监视器是无法分清的。(使用Navicat等链接可以不执行此步骤)
3.2 存储过程中可使用的控制语句
存储过程并非只是简单的 SOL 命令的集合体,还可以通过使用各种控制语来实现更复杂的处理。具体的控制语句有条件分支选择语句、循环控制语句等,如表所示

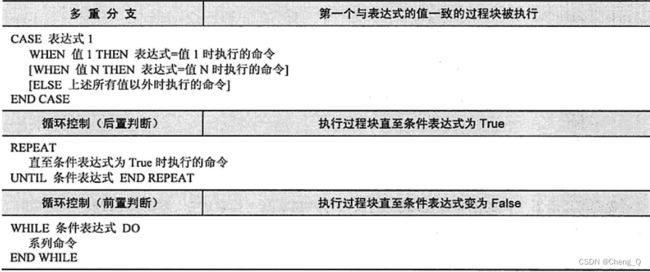
3.3 确认数据库中存储过程
正确执行了CREATE PROCEDURE 命令后,查看一下存储过程是否已经存在时,使用之前提到的语句:SHOWPROCEDURE STATUS ;
security_type:项目的[DEFINER]值的意思是,存储过程的执行权限与创建用户权限一致。
3.4 调用存储过过程
CALL 存储过程名(参数,...); 在调用存储过程时,如果出现参数数目不符(多或者少)的情况,将会显示错误信息。因此,即使参数为空字符串的情况下也是不能省略的。
3.5 删除存储过程
存储过程在创建之后,被保存在服务器上以供使用,直至被删除。
DROP PROCEDURE sp_search_customer;删除命令从服务器中删除存储过程,请注意没有使用后面的(),只给出存储过程名。
如果指定的过程不存在,则 DROP PROCEDURE 将产生一个错误。当过程存在想删除它时 (如果过程不存在也不产生错误)可使用 DROP PROCEDURE IF EXIST。
四、Mysql变量定义与赋值
4.1 局部变量
4.1.1 声明局部变量语法
declare var_name type [default var_value];
DECLARE:声明变量的关键字;var_name:变量的名称,可同时定义多个;
type:变量数据类型;DEFAULT value:为变量定义默认值,默认值为NULL。
-- 定义一个变量 a ,数据类型为 int ,默认值为 0:
declare a int default value 0;注意: 局部变量的定义,在begin/end块中有效。
4.1.2 变量赋值
方式一:使用 set 关键字赋值
SET var_name = expr[,var_name = expr]...
set:变量赋值关键字;var_name: 变量的名称;expr: 赋值表达式。
注意:一个 SET 语句可以同时为多个变量赋值,各个变量的赋值语句之间用逗号隔开。
# 声明一个默认值为unknown的val_name局部变量
declare val_name varchar(32) default 'unknown';
# 为局部变量赋值
set val_name = '张三';方式二:使用 SELECT ... INTO 赋值。
SELECT col_name [...] INTO var_name[,...] FROM table_name WEHRE condition ;
col_name: 查询的字段名称;var_name: 变量的名称;table_name: 参数指表的名称;condition: 指查询条件。
注意:将查询结果赋值给变量时,该查询语句的返回结果只能是单行。
# 定义两个变量存放name和age
declare val_name varchar(32) default '';
declare val_age int;
# 查询表中id为1的name和age并放在定义的两个变量中
select name,age into val_name,val_age from employee where id = 1;
4.2 用户变量
用户自定义用户变量,当前会话(连接)有效。与Java中的成员变量相似。
用户变量无需声明,直接赋值即可。用户变量名不区分大小写。名称的最大长度为64个字符。
语法: @val_name
方式一:使用 SET 赋值
可以使用形如 set @变量名=变量值 或者 set@变量名:=变量值 的方式赋值。
SET @a=1,@b:=2;
方式二:使用 SELECT 赋值
select @变量名:=变量值
select @变量名:=字段名 from table where ... limit 1;
注意: 通过查询表给变量赋值时,需保证查询结果只有一条记录,如果查询出多条结果,最好在查询后进行 limit 操作。
4.3 会话变量
会话变量是由系统提供的,只在当前会话(连接)中有效。
SESSION类型会话变量在每一次建立新链接是初始化,作用域与用户变量一样,仅限于当前连接。
语法: @@session.val_name
# 查看所有会话变量
show session variables;
# 查看指定的会话变量
select @@session.val_name;
# 修改指定的会话变量
set @@session.val_name = 0;
# 修改会话变量,以修改是否自动提交为例
SET autocommit=1;
SET SESSION autocommit=1;
SET @@global.autocommit=1;4.4 全局变量
全局变量由系统提供,整个MySQL服务器内有效。
GLOBAL全局变量在MySQL启动时由服务器自动初始化默认值,这些默认值可通过MySQL的配置文件my.cnf进行更改。临时性修改可以直接使用 set 进行设置,但是重启服务后会设置失效。
语法: @@global.val_name
# 查看全局变量中变量名有admin的记录
show global variables like '%admin%'
# 查看全局变量 admin_port 的值
select @@global.admin_port;
修改全局变量:以修改是否自动提交为例
SET GLOBAL autocommit=1;
SET @@global.autocommit=1;例:下面三条命令,都表示查看storage_engine变量,区别在于第二条指定查看的是全局变量,第三条指定查看的是会话变量,第一条并未指定,但是在会话变量和全局变量同时存在的情况下,默认显示的是会话变量。
select @@storage_engine;
select @@global.storage_engine;
select @@session.storage_engine;