《scikit-learn》决策树之分类树
前面我们学习了决策树的一些算法,提及到了scikit learn,这里我们已经基本具备了一些基本的知识,接下来我们进入实战环节,真实地去操作一把数据。希望在此学习的基础上基本掌握scikit learn的使用方法。
作为具体操作scikit learn的第一篇,先得做好一些准备工作。
conda install graphviz
conda install scikit-learn
此外还需要下载graphviz,并把其bin目录添加环境变量,重启开发环境即可。
一:分类树
先来看个例子
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz
# 分类问题举例,加载自带的红酒数据集
wine = load_wine() # 178个数据,13个属性,三个分类种类。
print(wine.data.shape)
print(wine.target.shape)
print(wine.target_names) # 所有类别标签地名称
print(wine.feature_names) # 所有特征属性的名称
# 把红酒数据进行切分,切分成训练集和测试集合,切分比例一般是7:3
data_train, data_test, target_train, target_test = train_test_split(wine.data, wine.target, test_size=0.3)
print(data_train.shape)
print(target_train.shape)
print(data_test.shape)
print(target_test.shape)
# 进行模型的搭建和训练
clf = tree.DecisionTreeClassifier(criterion='entropy') # 定义一个决策树的实例,决策树节点的分裂选择的是 根据信息熵划分
clf = clf.fit(data_train, target_train) # 用训练数据和标签,进行训练。简单的就这么简单就训练出了模型。
idxs = clf.apply(data_test) # 返回每个测试样本所在的叶子节点的索引
print(idxs)
results = clf.predict(data_test) # 返回每个测试样本分类/回归的结果
print(results)
score = clf.score(data_test, target_test) # 用已经训练好的模型,对测试数据进行预测准确率,0~1,越接近1越好。
print(score)
# 打印出一些其他的属性和信息
print(clf.feature_importances_) # 1: 打印各个属性的重要程度,数值越大,则表明重要性越高。
print(*zip(wine.feature_names, clf.feature_importances_)) # 1: 打印各个属性的重要程度,对应上各个属性的名称
print(clf.classes_) # 列出决策树的所有标签,是一个数组
print(clf.max_features_) # 最大的属性个数的推断值
print(clf.n_classes_) # 有几个分类
print(clf.n_features_) # 样本训练fit的时候有几个属性特征
print(clf.n_outputs_) # 样本训练fit的时候输出结果的个数
print(clf.tree_.max_depth) # 决策树的最大深度
print(clf.tree_.n_leaves) # 决策树一共有几个节点
# 把这棵树clf进行图像化,让人看着更加清晰
dot_data = tree.export_graphviz(clf, # 决策树本身
feature_names=wine.feature_names, # 特征名称
class_names=wine.target_names, # 类别名称
filled=True, # 给图形填充颜色
rounded=True # 图形的节点是圆角矩形
)
graph = graphviz.Source(dot_data)
graph.view(filename='kk.png', cleanup=True)
自行跑跑代码:
常用的接口和类
1、 数据集:演示的例子中给的是红酒的数据集,一共有178个数据样本,每个样本数据拥有13个属性,最后样本的类别个数是3个。
2、 tree.DecisionTreeClassifier:表示决策树的类,实例化的时候带有很多参数,比如指定评判标准等,等下还会细讲一些常用的参数。Criterion参数可以使用"gini"或者"entropy",前者代表基尼系数,后者代表信息增益。一般说使用默认的基尼系数"gini"就可以了,即CART算法。
3、 tree.DecisionTreeClassifier.fit方法,就是训练数据的方法。
4、 tree.DecisionTreeClassifier.apply方法,返回每个测试样本所在的叶子节点的索引。
5、 tree.DecisionTreeClassifier.predict方法, 返回每个测试样本分类/回归的结果
6、 tree.DecisionTreeClassifier.score方法, 用已经训练好的模型,对测试数据进行预测准确率,范围0~1,越接近1越好。
分类树类常用的属性
print(clf.feature_importances_) # 1: 打印各个属性的重要程度,数值越大,则表明重要性越高。
print(*zip(wine.feature_names, clf.feature_importances_)) # 1: 打印各个属性的重要程度,对应上各个属性的名称
print(clf.classes_) # 列出决策树的所有标签,是一个数组
print(clf.max_features_) # 最大的属性个数的推断值
print(clf.n_classes_) # 有几个分类
print(clf.n_features_) # 样本训练fit的时候有几个属性特征
print(clf.n_outputs_) # 样本训练fit的时候输出结果的个数
print(clf.tree_.max_depth) # 决策树的最大深度
print(clf.tree_.n_leaves) # 决策树一共有几个节点
最后呢,我们需要把这个树模型图像化,看的更加清晰易懂。
tree.export_graphviz:具体有以下参数
clf就是决策树本身,feature_names=wine.feature_names就是训练数据特征名称,class_names=wine.target_names就是数据所有类别名称,filled=True指示给图形填充颜色,rounded=Tru指示画图形的节点是圆角矩形。
展示图如下:
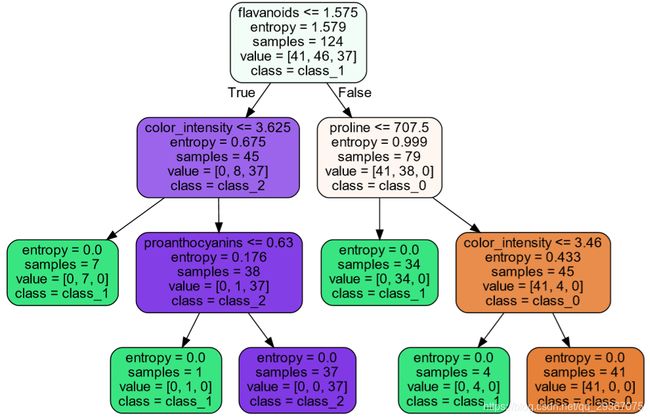
现在我们可以得到一棵树了。我们来看看这个树的图形化表示,里面有哪些含义呢?
Entropy:表示这个节点的信息熵,越大表示越混乱。
Samples:这个节点待分裂的样本个数,根节点的数目就是训练集的样本数目。
Vlaue:有几个分类,就有几个value,元素表示每个分裂的样本数目。
Class:根据投票原则,哪个类别的数目最多,这个节点最可能属于某个类别。
叶子节点就这四个指标,非叶子节点的话都是需要特征分裂的,因此会多一项过呢据特征划分的(第一行就是根据某个特征做出怎样的分裂)。
好了,我们现在来学习分类树类一些常用的参数。
1:随机性参数:
训练数据集不同,会影响模型结果,除此之外呢。
决策树在建立树的时候,在每一次的分裂过程中,都是不断地去找最优的分裂节点来分类。但是即使是这样,也不能表示说能保证最后得到的树是最优的,继承算法可以解决这个问题。Sklearn表示既然一棵树不能保证最优,那就建立不同的树,从中选取一个最优的树(这个思路还是很6的)。具体的做法就是在每次建立树的时候,都是随机选取其中部分特征来建立决策树(不是全部参数),这样建立的树具有随机性。这种做法就是为了探索多种树的可能,以便寻找出最优的树。但是也带来了缺点,就是带来了模型的不稳定性,每一次运行,哪怕是相同的训练数据集合,都会得到不同的结果。
random_state: 控制随机性种子,默认是None,高维数据下容易显现,低维数据几乎不显现。随意输入一个整数,固定了随机seed,于是每次运行都会生长出同一棵树。
splitter:俩输入值,默认是best,也就是说每一次进行特征分裂的时候都会选择最重要的、最优的特征进行分裂,这也是符合我们对决策树算法的一般的认识。但是他还有另外一个值是random,这个值就表示在节点的特征分裂时候对特征的选择会变得随机。这也是防止过拟合的一种办法,这俩参数可以降低过拟合。
具体代码展示如下:
clf = tree.DecisionTreeClassifier(criterion='entropy',
random_state=20,
splitter="best")
clf = clf.fit(data_train, target_train)
score = clf.score(data_test, target_test)
print(score)
2:剪枝参数
模型容易法还是能过拟合,我么需要对树进行剪枝操作。
max_depth:限制树的最大深度,超过指定深度的枝叶去拿不裁剪掉。
min_samples_leaf:一个节点在根据某个特征分裂后,每个子节点必须包含至少该指定个训练样本,否则,就不会用该特征进行分裂。
min_samples_split:一个节点必须包含指定个训练样本,低于该值,就不会对这个节点进行分裂。
max_features:在建立树的时候,每一次最多考虑指定个数个属性,多出的就不许用,太暴力了,强行削减信息量,高纬度数据下会使用的到,一般不太考虑使用这个,一般情况下建议可以先使用PCA等降维算法处理下。
min_imputity_decrease:限制信息增益的大小,我们知道,最纯的叶子节点,信息增益是0,父节点总是比叶子节点的信息熵大,可是如果父节点分裂后,得到的信息增益微乎其微,太小了,那么也没必要分裂了,不然这样会来巨大的计算量,却没有得到很多实际效果。
实例代码如下:
clf = tree.DecisionTreeClassifier(criterion='entropy', # 决策树节点的分裂选择的是 根据信息熵划分
random_state=20, # 随机seed是20,保证每次运行的结果是一致。
splitter="best", # 每次节点分裂策略都是寻找最优的特征
max_depth=5, # 树的最大深度是5
min_samples_leaf=2, # 一个节点在根据某个特征分裂后,2,否则,就不会用该特征进行分裂。
min_samples_split=10, # 一个节点必须包含10个训练样本,才能发生分裂。
min_impurity_decrease=0.001 # 信息增益若小于该值,则不进行分裂。
)
clf = clf.fit(data_train, target_train)
score = clf.score(data_test, target_test)
print(score)
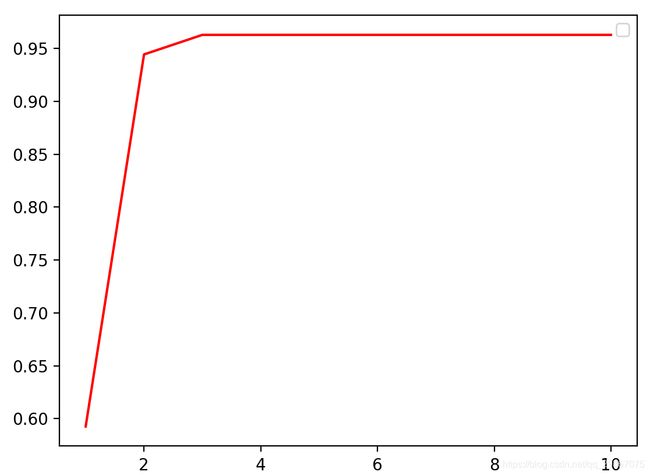
至于具体去哪些参数呢?我们可以建立超参数的曲线进行观察,比如以max_depth为例,尝试使用不同的数值,去训练数据,看看最后的效果如何。
比如实例代码如下:
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(criterion='entropy', # 决策树节点的分裂选择的是 根据信息熵划分
random_state=20, # 随机seed是20,保证每次运行的结果是一致。
splitter="best", # 每次节点分裂策略都是寻找最优的特征
max_depth=i+1, # 树的最大深度是i+1
)
clf = clf.fit(data_train, target_train)
score = clf.score(data_test, target_test)
test.append(score)
plt.plot(range(1, 11), test, color='red')
plt.legend()
plt.show()
通过观察超参数曲线,来确定最优的参数。
3:目标权重参数
class_weight:指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高,让模型向少数类别标签进行倾斜。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的"None",表示所有标签相同的权重。
min_weight_fraction_leaf:这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
实例代码:
clf = tree.DecisionTreeClassifier(criterion='entropy', # 决策树节点的分裂选择的是 根据信息熵划分
random_state=20, # 随机seed是20,保证每次运行的结果是一致。
splitter="best", # 每次节点分裂策略都是寻找最优的特征
max_depth=i+1, # 树的最大深度是i+1
class_weight='balanced' # 自动季孙各个样本的权重,是的样本均衡一些。
)
clf = clf.fit(data_train, target_train)
score = clf.score(data_test, target_test)
test.append(score)